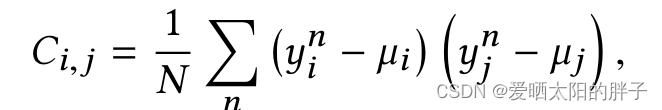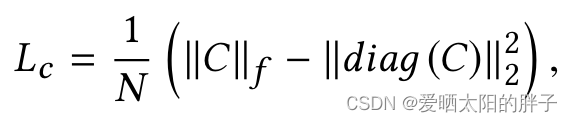User Diverse Preference Modeling by Multimodal Attentive Metric Learning

BACKGROUND
现有模型通常采用一个固定向量去表示用户偏好,在假设——特征向量每一个维度都代表了用户的一种特性或者一个方面,这种方式似乎不妥,因为用户对于不同物品的偏好是不一样的,例如因演员喜欢一部电影,而因特效而喜欢另一部特效,鉴于此,本文采用注意力和度量学习方式,使得用户特征向量随着物品的不同而变化。
METHOD
分别代表用户和物品的潜在特征向量,采用随机初始化。
注:推荐系统的核心就是学习用户&物品的特征向量。
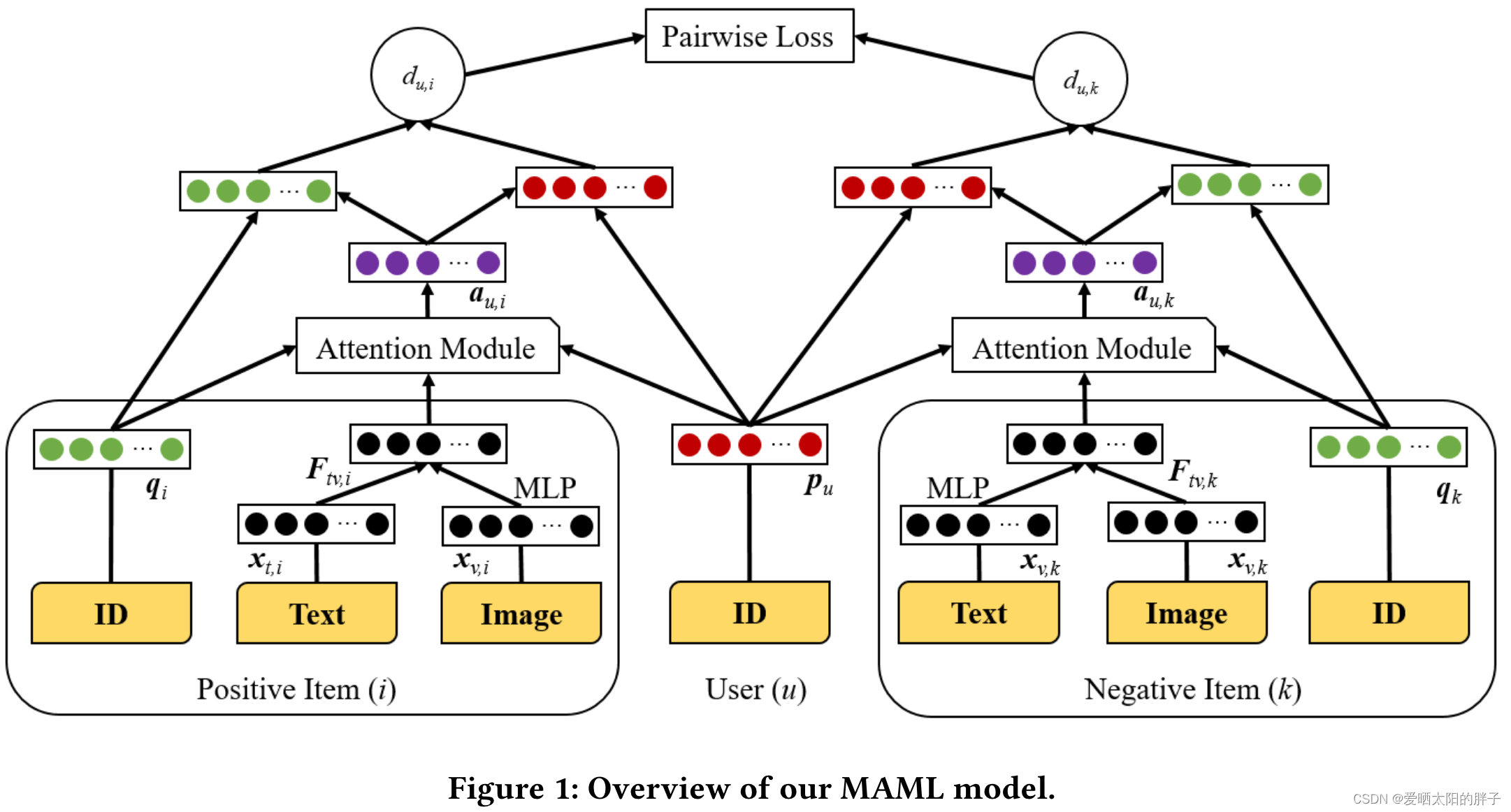
通过整体框架图可知,本文的训练样本为三元组(u,i,k)其中i为正样本(用户交互过的物品),k为负样本(用户未交互过的物品),正负样本的处理方式相同,核心是注意力模块,通过计算得到的注意力,对进行更改。因为该模块的输入为user_id,item_id即item相关的特征向量,所以对于不同的user和item,计算得到的注意力不同,则用户的特征表示也不同。
另外本文采用距离相关性替换了MF中的点积操作(点积不满足三角不等式,限制了性能)
Item Features
对于每个物品i 分别从评论和图片中提取出文本特征和视觉特征
,本文通过多层神经网络进行特征融合,具体如下:
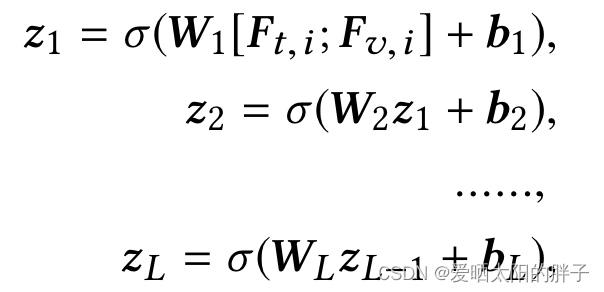
并将最后的结果,作为物品i的特征表示
Attention Mechanism
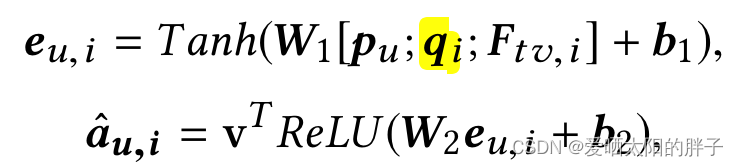
[;]为concat。本文的注意力部分的亮点为注意力分数到注意力分数的转化方式。
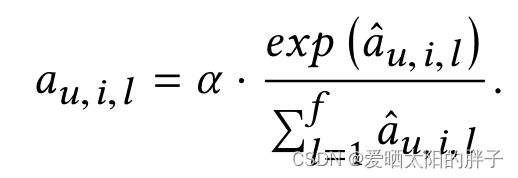
本文数字为特征向量的长度。
为什么不直接用softmax?
从上文可知,本步输出作用在用户&物品的特征向量上,换言之,要在初始id_embedding每维上乘以一个数得到新的新的特征向量,注意力计算模块的input&output的维度都等于id_embedding=f的维度,假设f=100,则权重的平均值为0.01非常小,训练时会因为区分小,而影响模型性能。
Optimization
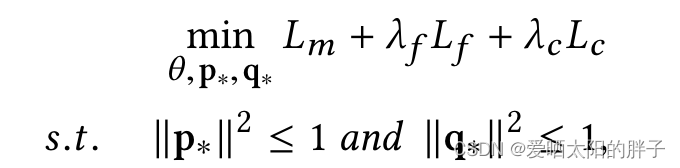
如上可知,损失函数有三部分组成,让我们分别来看一下组成形式和作用。
Metric Learning
m为边缘距离, ,此处时损失函数的主要部分,本文用欧式距离替换了MF的点积。
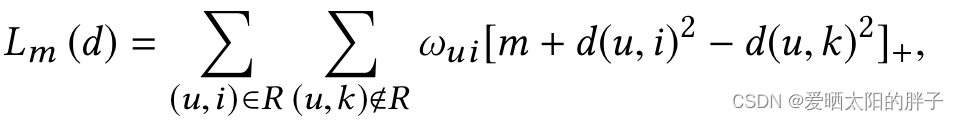
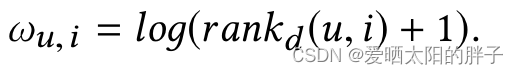
![]()
关于
细节见: Cheng-Kang Hsieh, Longqi Yang, Yin Cui, Tsung-Yi Lin, Serge Belongie, and Deborah Estrin. 2017. Collaborative metric learning. In WWW. IW3C2, 193–201
Regularization
一、实现文本特征和视觉特征越相似的物品在潜在空间中接近。
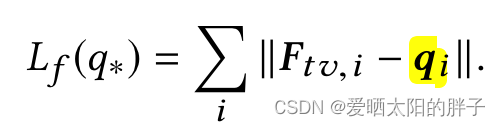
二、通过协方差来消除特征空间中的维度线性相关性,