自编码器简单介绍—使用PyTorch库实现一个简单的自编码器,并使用MNIST数据集进行训练和测试

文章目录
自编码器简单介绍
自编码器是一种无监督学习算法,用于学习数据中的特征,并将这些特征用于重构与输入相似的新数据。自编码器由编码器和解码器两部分组成,编码器用于将输入数据压缩到一个低维度的表示形式,解码器将该表示形式还原回输入数据的形式。自编码器可以应用于多种领域,例如图像处理、语音识别和自然语言处理等。
什么是自编码器?
自编码器是一种无监督学习算法,用于学习数据的压缩表示。它由两个部分组成:编码器和解码器。编码器将输入数据压缩成低维表示,解码器将这个低维表示重构成与原始输入尽可能接近的输出。
简单结构如下:
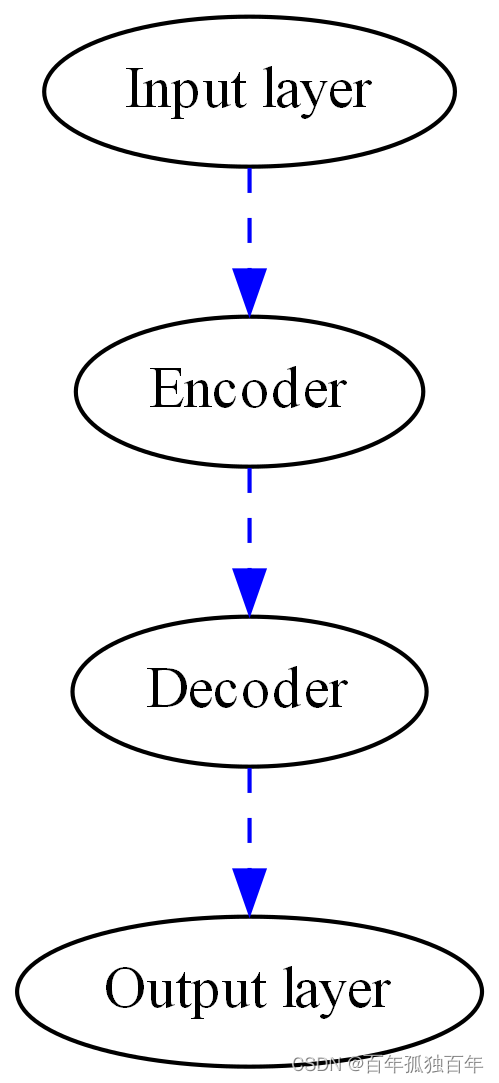
自动编码器和卷积神经网络的区别?
自动编码器和卷积神经网络(CNN)都是深度学习中常用的模型,但它们的目的和结构略有不同。
自动编码器是一种无监督学习模型,其目的是学习一个对输入数据进行压缩和解压缩的函数。自动编码器通常由两个部分组成:编码器和解码器。编码器将输入数据转换为潜在表示,解码器将潜在表示转换回原始数据。自动编码器的目标是最小化重构误差,即在解码器输出的数据与原始数据之间的差异。
与之不同,卷积神经网络是一种用于图像分类、目标检测、语音识别等任务的有监督学习模型。卷积神经网络通常由卷积层、池化层、全连接层等组成。卷积层可以捕捉输入数据的局部特征,池化层可以减少特征图的大小,全连接层可以将特征图转换为分类结果。
虽然自动编码器和卷积神经网络的目的和结构不同,但它们都可以用于特征提取。自动编码器可以学习输入数据的低维表示,卷积神经网络可以提取输入数据的局部特征。在某些任务中,这些特征可以作为输入传递到其他模型中,以提高任务的性能。
除了特征提取,自动编码器和卷积神经网络还有其他方面的不同之处。
自动编码器可以用于数据的降维和去噪。通过学习输入数据的低维表示,自动编码器可以将高维数据降低到更低的维度,从而简化数据。此外,自动编码器还可以在输入数据中去除噪声,因为它们的目标是在重构时最小化重构误差,这有助于滤除输入数据中的噪声。
卷积神经网络则更适合处理图像、语音、视频等具有空间结构的数据。卷积层可以捕捉输入数据的局部特征,这对于图像分类、目标检测等任务非常重要。此外,卷积神经网络还可以通过使用池化层来减少特征图的大小,从而在处理大型图像时降低计算成本。
总的来说,自动编码器和卷积神经网络是两种不同的深度学习模型,它们的应用场景和目标略有不同。但是,它们都是非常有用的工具,可以在各种任务中发挥重要作用。
如何构建一个自编码器?
首先,需要确定编码器和解码器的结构。编码器可以是多层感知器(MLP)或卷积神经网络(CNN),其中每一层都包含多个神经元,并通过非线性函数进行激活。解码器通常与编码器结构相对称,也可以是一个MLP或CNN。在训练自编码器时,将输入数据输入编码器并计算编码器输出,然后将其输入解码器并计算解码器输出。最终的目标是最小化解码器输出和原始输入之间的差异。
如何训练自编码器?
训练自编码器的关键是确定损失函数。通常使用均方误差(MSE)来计算解码器输出和原始输入之间的差异。MSE的计算方式如下:
$ 在公式中, y i y_i yi 是实际值, y i ^ \\hat{y_i} yi^ 是预测值, N N N 是数据集中的样本数。
M S E = 1 N ∑ i = 1 N ( y i − y ^ i ) 2 \\mathrm MSE=\\frac{1}{N}\\sum_{i=1}^N(y_i-\\hat y_i)^2 MSE=N1i=1∑N(yi−y^i)2
其中,N是样本数量, y i y_i yi是实际值, y ^ i \\hat y_i y^i是解码器输出,即预测值。通过反向传播算法,可以计算编码器和解码器中所有参数的梯度,并使用梯度下降算法对参数进行更新。
如何使用自编码器进行图像压缩?
在用自编码器压缩图像时,将图像输入自编码器的编码器部分,得到低维表示,该表示可以看作是图像的压缩版本。可以通过解码器部分将该低维表示解码成原始图像。由于自编码器的解码器部分重构图像,因此可以使用自编码器进行图像压缩。
总结
以上是自编码器的简单入门教程。自编码器是一种无监督学习算法,可以用于学习数据的压缩表示。在训练自编码器时需要确定编码器和解码器的结构以及损失函数,并使用梯度下降算法对参数进行更新。自编码器可以用于图像压缩等任务。
使用PyTorch构建简单的自动编码器
在本教程中,我们将使用PyTorch库实现一个简单的自编码器,并使用MNIST数据集进行训练和测试。
第一步:导入库和数据集
首先,我们需要导入必要的库并加载MNIST数据集。
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms# 检查是否安装了CUDA,并且CUDA是否适用于你的GPU
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')# 超参数设置
batch_size = 64
learning_rate = 1e-3
num_epochs = 10# 加载MNIST手写数字数据集
train_dataset = datasets.MNIST(root='./data/', train=True, transform=transforms.ToTensor(), download=True)
test_dataset = datasets.MNIST(root='./data/', train=False, transform=transforms.ToTensor())# 创建数据加载器
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=batch_size, shuffle=False)
第二步:建立编码器和解码器
接下来,我们需要建立编码器和解码器模型。
# 定义一个自编码器的类
class Autoencoder(nn.Module):def __init__(self):super(Autoencoder, self).__init__()# 编码器部分self.encoder = nn.Sequential(nn.Conv2d(1, 16, kernel_size=3, stride=2, padding=1), # 输入1通道,输出16通道,3x3卷积,步长为2,padding为1nn.ReLU(),nn.Conv2d(16, 32, kernel_size=3, stride=2, padding=1), # 输入16通道,输出32通道,3x3卷积,步长为2,padding为1nn.ReLU(),nn.Conv2d(32, 64, kernel_size=7), # 输入32通道,输出64通道,7x7卷积)# 解码器部分self.decoder = nn.Sequential(nn.ConvTranspose2d(64, 32, kernel_size=7), # 输入64通道,输出32通道,7x7卷积转置nn.ReLU(),nn.ConvTranspose2d(32, 16, kernel_size=3, stride=2, padding=1, output_padding=1), # 输入32通道,输出16通道,3x3卷积转置,步长为2,padding为1,输出padding为1nn.ReLU(),nn.ConvTranspose2d(16, 1, kernel_size=3, stride=2, padding=1, output_padding=1), # 输入16通道,输出1通道,3x3卷积转置,步长为2,padding为1,输出padding为1nn.Sigmoid())def forward(self, x):x = self.encoder(x)x = self.decoder(x)return x# 创建自编码器对象并将模型移动到GPU
model = Autoencoder().to(device)第三步:定义损失函数和优化器
定义损失函数和优化器如下。
# 定义损失函数和优化器
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)第四步:训练自编码器模型
现在可以使用MNIST数据集训练自编码器模型。
# 训练自编码器
for epoch in range(num_epochs):for data in train_loader:img, _ = dataimg = img.to(device)# 前向传播output = model(img)loss = criterion(output, img)# 反向传播和优化器优化optimizer.zero_grad()loss.backward()optimizer.step()print("Epoch[{}/{}], loss:{:.4f}".format(epoch+1, num_epochs, loss.data))
第五步:测试自编码器模型
# 测试自编码器
model.eval()
total_loss = 0
with torch.no_grad():for data in test_loader:img, _ = dataimg = img.to(device)output = model(img)loss = criterion(output, img)total_loss += loss.item()print("Test average loss:{:.4f}".format(total_loss / len(test_loader)))
第六部:对比重构结果
在训练完成后,我们可以使用自编码器模型重构一些测试数据,并将重构的结果与原始数据进行比较。
# 迭代测试数据集,生成迭代器
dataiter = iter(test_loader)# 从迭代器中获取下一个批次的图像和标签
images, labels = next(dataiter)# 使用模型进行推断,处理获取的图像数据,并将结果保存在output变量中
output = model(images.to(device))# 创建子图和轴对象,其中第一行显示原始图像,第二行显示重构后的图像
fig, axes = plt.subplots(nrows=2, ncols=10, sharex=True, sharey=True, figsize=(25,4))# 循环遍历前10个图像,绘制原始图像和重构图像并添加标题
for i in range(10):# 显示原始图像axes[0,i].imshow(images[i].squeeze().numpy(), cmap='gray')axes[0,i].set_title("Original")axes[0,i].get_xaxis().set_visible(False)axes[0,i].get_yaxis().set_visible(False)# 显示重构后的图像axes[1,i].imshow(output[i].squeeze().cpu().detach().numpy(), cmap='gray')axes[1,i].set_title("Reconstructed")axes[1,i].get_xaxis().set_visible(False)axes[1,i].get_yaxis().set_visible(False)# 显示生成的子图
plt.show()
运行完整的程序后,我们应该会看到原始图像和重构图像的对比结果。自编码器可以在其中一些图像上产生较好的结果,但在其他图像上可能会出现一些失真或模糊。
自编码器在实际应用中有许多变体和扩展,例如稀疏自编码器和卷积自编码器。这里仅仅是一个简单的入门教程,可以让您了解自编码器的基本原理和应用。