读论文--Token Merging for Fast Stable Diffusion(用于快速Diffusion模型的tome技术)

摘要
The landscape of image generation has been forever changed by open vocabulary diffusion models.
However, at their core these models use transformers, which makes generation slow. Better implementations to increase the throughput of these transformers have emerged, but they still evaluate the entire model.
In this paper, we instead speed up diffusion models by exploiting natural redundancy in generated images by merging redundant tokens.
After making some diffusion-specific improvements to Token Merging (ToMe), our ToMe for Stable Diffusion can reduce the number of tokens in an existing Stable Diffusion model by up to 60% while still producing high quality images without any extra training.
In the process, we speed up image generation by up to 2× and reduce memory consumption by up to 5.6×.
Furthermore, this speed-up stacks with effi- cient implementations such as xFormers, minimally impact- ing quality while being up to 5.4× faster for large images. Code is available at
开放的词汇扩散模型已经永远改变了图像生成的格局。
然而,这些型号的核心是使用变压器,这使得发电速度变慢。已经出现了更好的实现来提高这些转换器的吞吐量,但它们仍然会评估整个模型。
在本文中,我们通过合并冗余令牌来利用生成图像中的自然冗余,从而加快扩散模型的速度。
在对令牌合并(ToMe)进行了一些特定于扩散的改进后,我们的ToMe for Stable diffusion可以将现有稳定扩散模型中的令牌数量减少60%,同时仍然可以在没有任何额外训练的情况下生成高质量图像。
在此过程中,我们将图像生成速度提高了2倍,并将内存消耗减少了5.6倍。
此外,这种加速与xFormers等高效实现相结合,对质量的影响最小,同时对大图像的速度高达5.4倍。代码可在
一 介绍
xxx
Though most of these methods require re-training the model (which would be prohibitively expensive for e.g., Stable Diffusion), Token Merging (ToMe) [1] stands out in particular by not requiring any additional training.
While the authors only apply it to ViT [5] for classification, they claim that it should also work for downstream tasks.
In this paper, we put that to the test by applying ToMe to Stable Diffusion.
Out of the box, a na ̈ıve application can speed up diffusion by up to 2× and reduce memory con- sumption by 4× (Tab. 1), but the resulting image quality suffers greatly (Fig. 3).
To address this, we introduce new techniques for token partitioning (Fig. 5) and perform sev- eral experiments to decide how to apply ToMe (Tab. 3).
As a result, we can keep the speed and improve the memory benefits of ToMe, while producing images extremely close to the original model (Fig. 6, Tab. 4).
Furthermore, this speed- up stacks with implementations such as xFormers (Fig. 1).
尽管这些方法中的大多数都需要重新训练模型(这对于例如稳定扩散来说是非常昂贵的),但令牌合并(ToMe)[1]尤其突出,因为它不需要任何额外的训练。
虽然作者只将其应用于ViT[5]进行分类,但他们声称它也应该适用于下游任务。
在本文中,我们通过将ToMe应用于稳定扩散来测试这一点。
开箱即用的应用程序可以将扩散速度提高2倍,并将内存消耗减少4倍(表1),但最终的图像质量会受到很大影响(图3)。
为了解决这个问题,我们引入了新的令牌划分技术(图5),并进行了一些实验来决定如何应用ToMe(表3)。
因此,我们可以保持ToMe的速度并提高其内存优势,同时生成非常接近原始模型的图像(图6,表4)。
此外,这种加速与xFormers等实现相叠加(图1)。
图5
Figure 5. Partitioning src and dst.
ToMe [1] merges tokens from src into dst.
(a) 默认间隔取值 By default, ToMe alternates src and dst tokens.
In our case, this causes dst to form regular columns which leads to bad outputs (poor fish).
(b) 2x2取值左上角(2d的步长) We can improve generation by sampling dst with a 2d stride (e.g., 2 × 2), but this still forms a regular grid.
(c) 随机取值 We can introduce irregularity by sampling randomly, but this can cause undesirable clumps of dst tokens.
(d) 随机取值左上角 Thus, we sample one dst token randomly in each 2 × 2 region.
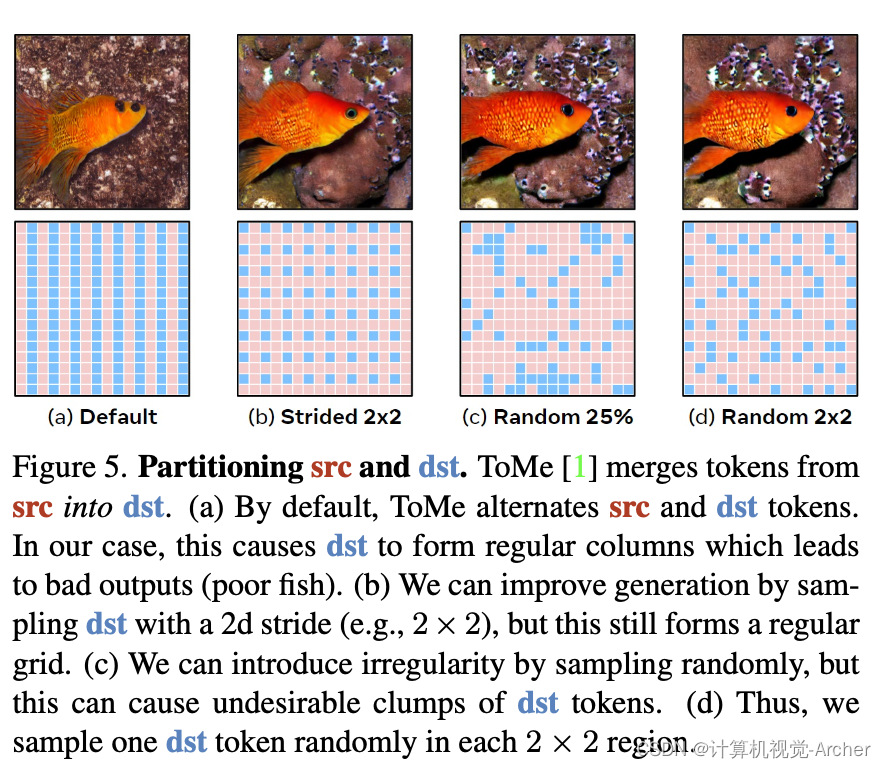
图5-对src和dst进行分区。
ToMe[1]将src中的令牌合并到dst中。
(a) 默认情况下,ToMe交替使用src和dst标记。在我们的例子中,这会导致dst形成规则列,从而导致糟糕的输出(较差的fish)。
(b) 我们可以通过以2d步长(例如,2×2)对dst进行采样来改进生成,但这仍然形成了一个规则的网格。
(c) 我们可以通过随机采样引入不规则性,但这可能会导致不希望的dst标记聚集。
(d) 因此,我们在每个2×2区域中随机采样一个dst令牌。
二 背景
Stabel Diffusion.xxx
Token Merging.
Token Merging (ToMe) [1] reduces the number of tokens in a transformer gradually by merging r tokens in each block.
To do this efficiently, it partitions the tokens into a source (src) and destination (dst) set. Then, it merges the r most similar tokens from src into dst, reducing the number of tokens by r, making the next block faster.
令牌合并(ToMe)[1](这是第一篇tome工作: Token Merging: Your ViT But Faster)通过合并每个块中的r个令牌,逐渐减少转换器中的令牌数量。
为了有效地做到这一点,它将令牌划分为源(src)和目标(dst)集。然后,它将src中r个最相似的令牌合并到dst中,将令牌数量减少r,使下一个块更快。
三 Token Merging for Stable Diffusion
While ToMe as described in Sec. 2 works well for classification, it’s not entirely straightforward to apply it to a dense prediction task like diffusion.
While classification only needs a single token to make a prediction, diffusion needs to know the noise to remove for every token.
Thus, we need to introduce the concept of unmerging.
虽然第2节中描述的ToMe在分类方面效果良好,但将其应用于扩散等密集预测任务并不完全简单。
虽然分类只需要一个令牌来进行预测,但扩散需要知道每个令牌要去除的噪声。
因此,我们需要引入unmerging的概念。
3.1. Defining Unmerging
While other token reduction methods such as pruning (e.g., [14]) remove tokens, ToMe is different in that it merges them.
And if we have information about what tokens we merged, we have enough information to then unmerge those same tokens.
This is crucial for a dense prediction task, where we really do need every token.

虽然其他令牌减少方法,如修剪(例如,[14])删除令牌,但ToMe的不同之处在于它合并了它们。
如果我们有关于我们合并了哪些令牌的信息,我们就有足够的信息来取消合并这些相同的令牌。
这对于密集的预测任务至关重要,因为我们确实需要每一个令牌。
x*1,2是合并后的token
x1' x2'是umerge的token
3.2. An Initial Na ̈ıve Approach
Merging tokens and then immediately unmerging them doesn’t help us though.
Instead, we’d like to merge tokens, do some (now reduced) computation, and then unmerge them afterward so we don’t lose any tokens.
Na ̈ıvely, we can just apply ToMe before each component of each block (i.e., self attn, cross attn, mlp), and then unmerge the outputs before adding the skip connection (see Fig. 2).
Details.
Because we’re not accumulating any token reduction (merged tokens are quickly unmerged), we have to merge a lot more than the original ToMe.Thus instead of removing a quantity of tokens r, we remove a percentage (r%) of all tokens.
Moreover, computing token similarities for merging is expensive, so we only do it once at the start of each block.
Finally, we don’t use proportional attention and use the input to the block x for similarly rather than attention keys k.
More exploration is necessary to find if these techniques carry over from the classification setting.
合并token然后立即取消合并对我们没有帮助。
相反,我们希望合并令牌,进行一些(现在减少了)计算,然后取消它们的合并,这样我们就不会丢失任何令牌。
总之,我们可以在每个块的每个组件(即self-attn、cross-attn、mlp)之前应用ToMe,然后在添加跳过连接之前取消合并输出(见图2)。
细节
因为我们没有积累任何token减少(合并后的token很快就会被取消合并),所以我们必须比原始的ToMe合并更多。
因此,我们不是移除一定数量的令牌r,而是移除所有令牌的百分比(r%)。加大力度
此外,计算用于合并的令牌相似性是昂贵的,所以我们只在每个块开始时进行一次。
最后,我们不使用比例注意力,而是将block x的输入用于smilarity计算而不是attention keys k。
有必要进行更多的探索,以确定这些技术是否从分类设置中继承下来。
图2
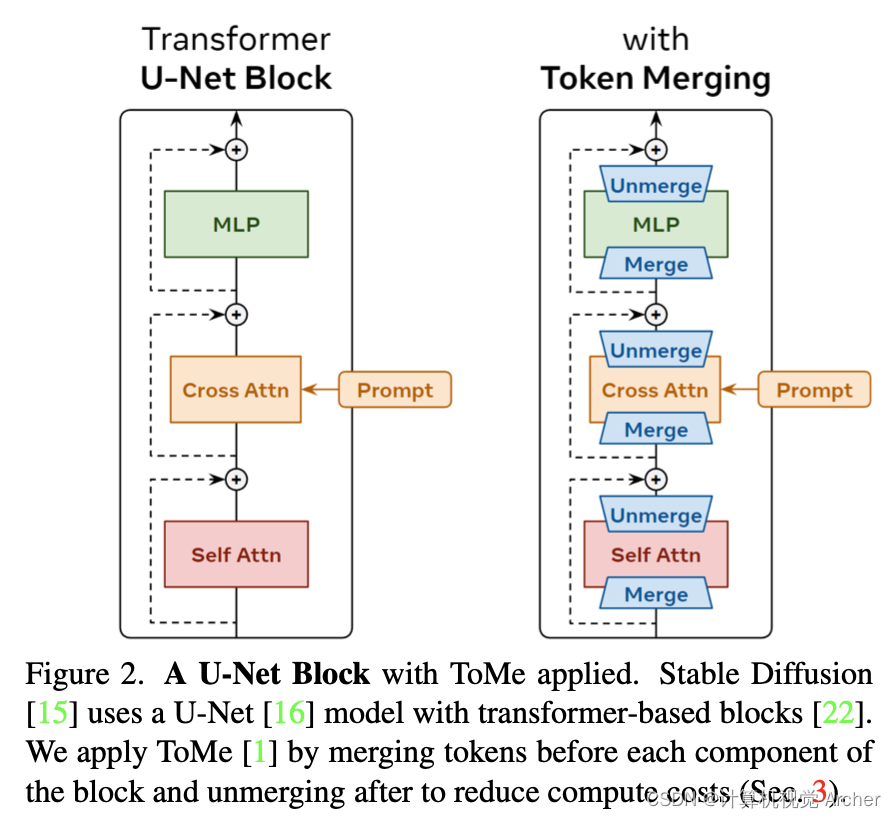
fig.2 应用了ToMe的U-Net块。
稳定扩散[15]使用具有基于变压器的块[22]的U-Net[16]模型。
我们通过在块的每个组件之前合并令牌并在之后取消合并来应用ToMe[1],以降低计算成本(第3节)。
四 Further Exploration
Amazingly, the simple approach described in Sec. 3 works fairly well out of the box without any training, even for large amounts of token reduction (see Fig. 3).
This is in stark contrast to if we pruned tokens instead, which completely destroys the image (see Fig. 4).
However, we’re not done yet.
While the images with ToMe applied look alright, the content within each image changes drastically (mostly for the worse).
Thus, we make further improvements using Na ̈ıve ToMe with 50% reduction as our starting point.Experimental Details.
To quantify performance, we use Stable diffusion v1.5 to generate 2,000 512×512 images of ImageNet-1k [3] classes (2 per class) using 50 PLMS [9] diffusion steps with a cfg scale [4] of 7.5.
We then compute FID [6] scores between those 2,000 samples and 5,000 class-balanced ImageNet-1k val examples using [19].
To test speed, we simply average the time taken over all 2,000 samples on a single 4090 GPU.
Applying ToMe naively increases FID substantially (see Tab. 1), though evaluation is up to 2× faster with up to 4× less memory used.
令人惊讶的是,第3节中描述的简单方法在没有任何训练的情况下,即使对于大量的代币减少,也能很好地开箱即用(见图3)。
这与我们修剪标记pruned tokens形成了鲜明对比,后者完全破坏了图像(见图4)。
然而,我们还没有结束。
虽然应用了ToMe的图像看起来不错,但每个图像中的内容都会发生巨大变化(大部分情况更糟)。
因此,我们使用Naıve ToMe进行进一步改进,并以减少50%为起点。
实验细节
为了量化性能,我们使用Stable diffusion v1.5生成2000个512×512 ImageNet-1k[3]类的图像(每个类2个),使用50个PLMS[9]扩散步骤,cfg scale[4]为7.5。
然后,我们使用[19]计算2000个样本和5000个类别平衡的ImageNet-1k val样本之间的FID[6]分数。
为了测试速度,我们简单地对单个4090 GPU上所有2000个样本所花费的时间进行平均。应用ToMe 大大增加了FID(见表1),尽管评估速度快了2倍,使用的内存少了4倍。
图3图4

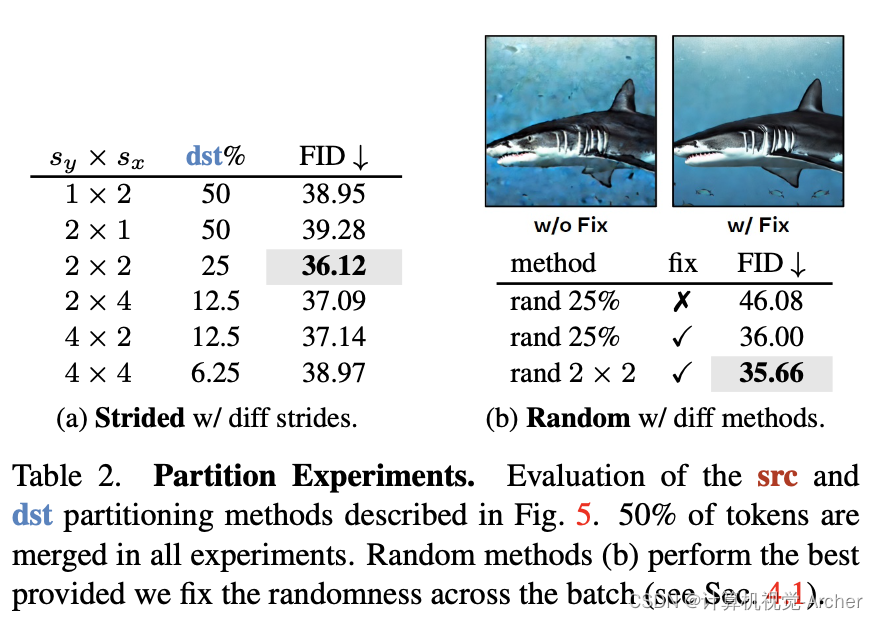
4.1. A New Partitioning Method
By default, ToMe partitions the tokens into src and dst (see Sec. 2) by alternating between the two.
This works for ViTs without unmerging, but in our case this causes src and dst to form alternating columns (see Fig. 5a).
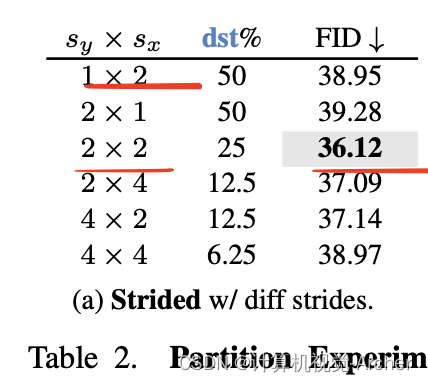
Since half of all tokens are in src, if we merge 50% of all tokens, then the entirety of src gets merged into dst, so we effectively halve the resolution of the images along the rows.A simple fix would be to select tokens for dst with some 2d stride.
This significantly improves the image both qualitatively (Fig. 5b) and quantitatively (Tab. 2a) and gives us the ability to merge more tokens if we want (i.e., the src set is larger), but the dst tokens are still always in the same place.
To resolve this, we can introduce randomness.However, if we just sample dst randomly, the FID jumps massively (Tab. 2b w/o fix). Crucially, we find that when using classifier-free guidance [4], the prompted and un- prompted samples need to allocate dst tokens in the same way.
We resolve this by fixing the randomness across the batch, which improves results past using a 2d stride (Fig. 5c,Tab. 2b w/ fix).
Combining the two methods by randomly choosing one dst token in each 2 × 2 region performs even better (Fig. 5d), so we make this our default going forward.
默认情况下,ToMe通过在src和dst之间交替来将令牌划分为这两个部分(请参见第2节)。
(src = token[:,::2,:] dst = token[:,1::2,:])
这适用于没有ummerging的ViT,但在我们的情况下,这会导致src和dst形成交替的列(见图5a)。
由于一半的token在src中,如果我们合并50%的令牌,那么整个src将合并到dst中,因此我们有效地将各行图像的分辨率减半。
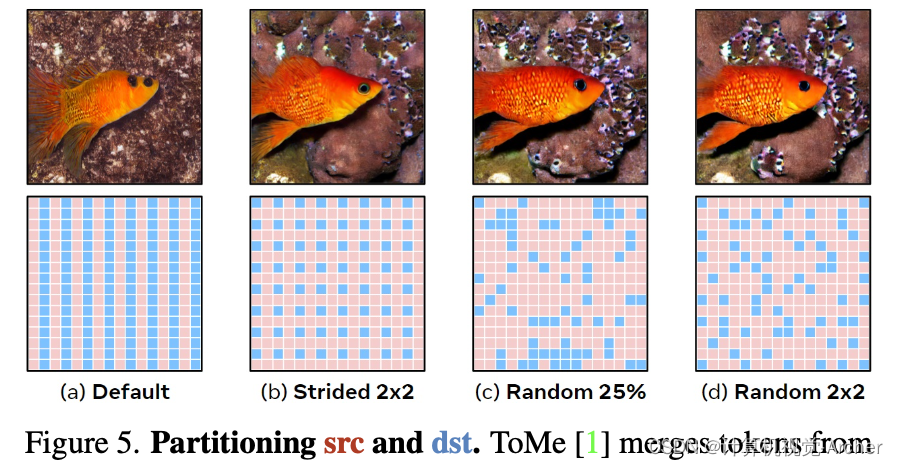 Fig.5 abcd
Fig.5 abcd
 Tab2(a)
Tab2(a) Tab2(b)
Tab2(b)
Partition Experiments. Evaluation of the src and dst partitioning methods described in Fig. 5. 50% of tokens are merged in all experiments. Random methods (b) perform the best provided we fix the randomness across the batch (see Sec. 4.1).
分区实验。图5中描述的src和dst分区方法的评估。在所有实验中,50%的令牌被合并。随机方法(b)表现最好,前提是我们修复了整个批次的随机性(见第4.1节)。
一个简单的修复方法是为dst选择一些2d步幅的token。
这显著改善了图像的质量(图5b)和数量(表2a),并使我们能够根据需要合并更多的token(即src集更大),但dst令牌仍然总是在同一位置。
为了解决这个问题,我们可以引入随机性。
然而,如果我们只是随机采样dst,FID会大幅跳跃(表2b w/o fix)。
至关重要的是,我们发现,当使用classifier-free guidance[4]时,提示样本和非提示样本(prompted and unprompted samples)需要以相同的方式分配dst令牌。
我们通过修复整个批次的随机性(fixing the randomness across the batch)来解决这一问题,这使用2d步长来改进过去的结果(图5c,表2b w/fix)。
通过在每个2×2区域中随机选择一个dst令牌来组合这两种方法,效果甚至更好(图5d),因此我们将其作为默认值。
图2
Table 2. Partition Experiments. Evaluation of the src and dst partitioning methods described in Fig. 5.
50% of tokens are merged in all experiments.
Random methods (b) perform the best provided we fix the randomness across the batch (see Sec. 4.1).分区实验。图5中描述的src和dst分区方法的评估。在所有实验中,50%的令牌被合并。随机方法(b)表现最好,前提是我们修复了整个批次的随机性(见第4.1节)。
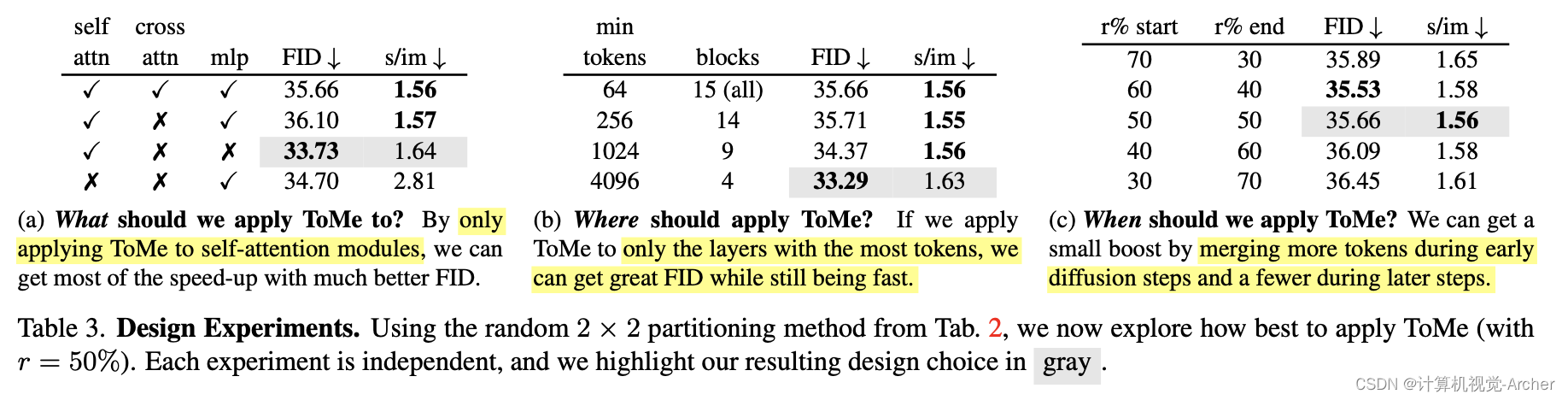
4.2. Design Experiments
In Sec. 3, we apply ToMe to every module, layer, and diffusion step. Here we search for a better design (Tab. 3).
What should we apply ToMe to? Originally, we applied ToMe to all modules (self attn, cross attn, mlp). In Tab. 3a, we test applying ToMe to different combinations of these modules and find that in terms of speed vs. FID trade-off, just applying ToMe to self attn is the clear winner. Note that FID doesn’t consider prompt adherance, which is likely why merging the cross attn module actually reduces FID.
Where should we apply ToMe? Applying ToMe to every block in the network is not ideal, since blocks at deeper U-Net scales have much fewer tokens. In Tab. 3b, we try restricting ToMe to only blocks with some minimum number of tokens and find that only the blocks with the most tokens need ToMe applied to get most of the speed-up.
When should we apply ToMe? It might not be right to reduce the same number of tokens in each diffusion step. Earlier diffusion steps are coarser and thus might be more forgiving to errors. In Tab. 3c, we test this by linearly interpolating the percent of tokens reduced and find that indeed merging more tokens earlier and fewer tokens later is slightly better, but not enough to be worth it.
在第3节中,我们将ToMe应用于每个模块、层和扩散步骤。在这里,我们寻找一个更好的设计(表3)。
我们应该将ToMe应用于什么?最初,我们将ToMe应用于所有模块(self-attn、cross-attn、mlp)。在表3a中,我们测试了将ToMe应用于这些模块的不同组合,发现就速度与FID的权衡而言,仅将ToMe用于self-attn显然是赢家。请注意,FID不考虑prompt adherance,这可能是合并交叉attn模块实际上会降低FID的原因。
我们应该在哪里应用ToMe?将ToMe应用于网络中的每个区块并不理想,因为更深U-Net规模的区块的token要少得多。在表3b中,我们试图将ToMe限制为仅具有一些最小令牌数量的块,并发现只有具有最多token的block才需要应用ToMe来获得大部分加速。
我们应该什么时候申请ToMe?在每个扩散步骤中减少相同数量的token可能是不对的。早期的扩散步骤比较粗糙,因此可能对误差更宽容。在表3c中,我们通过线性插值减少的token百分比来测试这一点,发现事实上,提前合并更多token,晚合并更少token稍微好一点,但不足以证明这一点。
Tab3 abc
五. Putting It All Together
We combine all the techniques discussed in Sec. 4 into one method, dubbed “ToMe for Stable Diffusion”. In Fig. 6
we show representative samples of how it performs visually, and in Tab. 4 we show the same qualitatively. Overall, ToMe for Stable Diffusion minimally impacts visual quality while offering up to 2× faster evaluation using 5.6× less memory.
ToMe + xFormers. Since ToMe just reduces the number of tokens, we can still use off the shelf fast transformer im- plementations to get even more benefit. In Fig. 1 we test generating a 2048 × 2048 image with ToMe and xFormers combined and find massive speed benefits. We can get even more speed-up if we’re okay with sacrificing more visual quality (Fig. 7). Note that with smaller images, we found this speed-up to be less pronounced, likely due to the diffusion model not being the bottleneck. Moreover, the memory benefits did not stack with xFormers.
我们将第4节中讨论的所有技术合并为一种方法,称为“ToMe for Stable Diffusion”。在图6中
我们展示了它在视觉上表现的代表性样本,在表4中,我们定性地展示了同样的情况。总体而言,ToMe for Stable Diffusion对视觉质量的影响最小,同时使用5.6倍的内存提供高达2倍的快速评估。
ToMe+xFormers。由于ToMe只是减少了token的数量,我们仍然可以使用现成的快速转换器来获得更多的好处。在图1中,我们测试了ToMe和xFormers组合生成2048×2048图像,并发现了巨大的速度优势。如果我们可以牺牲更多的视觉质量,我们可以获得更多的加速(图7)。请注意,对于较小的图像,我们发现这种加速不太明显,这可能是因为diffusion model不是瓶颈。此外,xFormers并没有带来内存优势。
图6。定性结果。我们的ToMe版本保留了图像内容,即使在高代币减少的情况下也是如此。虽然一些细微的细节可能会丢失(例如,在狗和鸟的背景中),但我们的方法仍然能很好地处理复杂的场景(如珊瑚礁)。
图7。调整以获得更高的速度。图1(a)中的结果使用了第4节中做出的选择,这些选择被调整为最佳质量。然而,如果我们可以接受保真度的下降(b),我们可以获得更多的加速,但有一个极限(c),在这个极限之后,大多数时间都被我们无法控制的模块占用,导致几乎没有进一步的加速。(提示:这只鸟的羽毛变得不那么详细了)。


六. Conclusion and Future Directions
Overall, we successfully apply ToMe to Stable Diffusion in a way that generates high quality images while being significantly faster. Notably, we do this without training which is rather remarkable, as any other token reduction method would require retraining. Still, these results could likely be improved by exploring 1.) better unmerging strategies or 2.) whether proportional attention or key-based similarity are useful for diffusion. Furthermore, our success moti- vates more exploration into using ToMe for dense predic- tion tasks. We hope this work can serve as both a useful tool for practitioners as well as a starting point for future research in token merging.
结论和未来方向
总的来说,我们成功地将ToMe应用于稳定扩散,从而生成高质量的图像,同时速度显著加快。值得注意的是,我们在没有经过培训的情况下做到了这一点,这相当了不起,因为任何其他代币减少方法都需要重新培训。尽管如此,这些结果可能会通过探索
1)更好的unmerging策略
2)比例注意力或基于关键点的相似性(proportional attention or key-based similarity )是否对扩散有用而得到改善。此外,我们的成功促使人们更多地探索将ToMe用于密集的预测任务。我们希望这项工作既能成为从业者的有用工具,也能成为未来代币合并研究的起点。