搞定常见八大排序

文章目录
-
- 注意事项
- 插入排序
-
- 插入排序
- 希尔排序
- 分组预排序
- 选择排序
-
- 堆排序
- 直接选择排序(最拉胯的排序)
- 交换排序
-
- 冒泡排序
- 快速排序
-
- 1. hoare版本
- 如何解决快排缺陷?
- 2.挖坑法版本
- 3.双指针法版本(建议)
- 快排算法优化
- 实现非递归快排
- 归并排序
-
- 归并排序
- 非比较排序
-
- 计数排序
- 外排序
注意事项
- 下面排序一律使用升序实现
插入排序
插入排序
核心: 不断地往有序队列里插入值
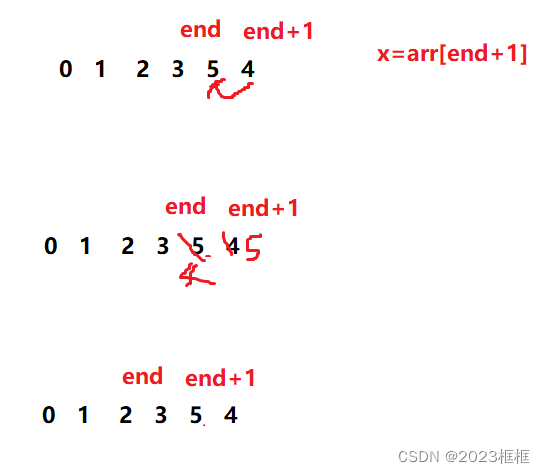
// 时间复杂度:O(N^2)
// 最好:O(N) -- 顺序有序或者接近有序
// 最坏:O(N^2) -- 逆序
// 空间复杂度:O(1)
void InsertSort(int* a, int n)
{assert(a);for (int i = 0; i < n - 1; ++i){// 将x插入[0, end]有序区间int end = i;int x = a[end+1];while (end >= 0){if (a[end] > x){a[end + 1] = a[end];--end;}else{break;}}a[end + 1] = x;}
}
希尔排序
核心:
-
- 分组预排序 – 让数组接近有序
-
- 直接插入排序
分组预排序
第一步:
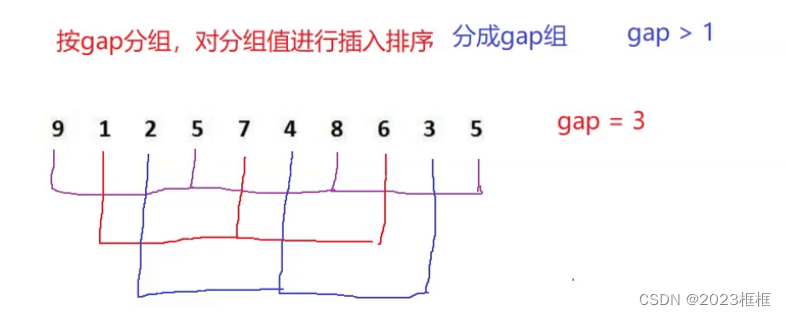
gap是一个整数, 如下图gap为3, 紫色,红色和蓝色,这三组,就是gap组;
紫色组:9,5,8,5
红色组:1,7,6
蓝色组:2,4,3
每相同组元素之间间隔gap个元素.
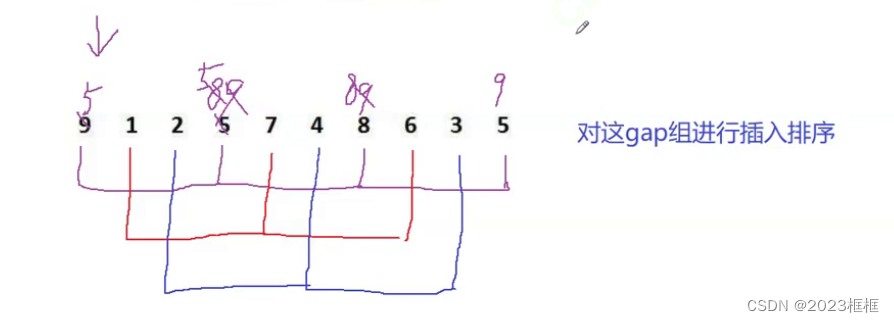
第二步:
每一组进行插入排序
如下图:
紫色组,从第一个元素9开始插入排序.
红色组蓝色组也是一样.
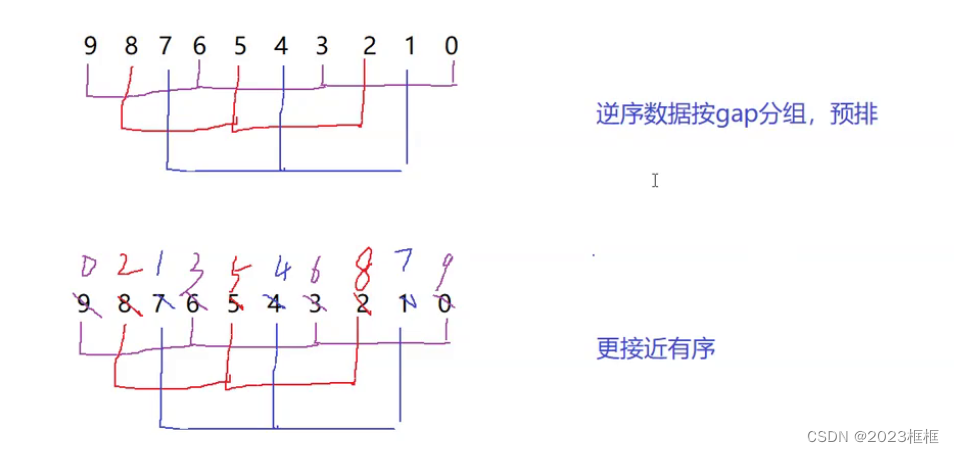
第三步(了解):
如图 对逆序数组预排之后,接近有序
第四步:
我们感觉到预排消耗挺大的,后面我们与其他排序进行对比分析.
第五步:
实现预排操作
基础版:
时间复杂度:
最好: O(N)
最坏: F(N,gap) = (1+2+3+… N/gap) * gap – gap个组里,每一组时间复杂度 (1+2+…N/gap)
通过上述时间复杂度, gap越大,预排越快 , gap越小时间复杂度不断接近O(N^2)
void ShellSort(int* a, int n)
{// 按gap分组数据进行预排序int gap = 3;for (int j = 0; j < gap; ++j){// 下面一组一组来插入排序for (int i = j; i < n - gap; i += gap){int end = i;int x = a[end + gap];while (end >= 0){if (a[end] > x){a[end + gap] = a[end];end -= gap;}else{break;}}a[end + gap] = x;}}
}
改造版(多组一窝顿):
void ShellSort(int* a, int n)
{// 按gap分组数据进行预排序int gap = 3;// 下面一组一组来插入排序for (int i = j; i < n - gap; i ++){int end = i;int x = a[end + gap];while (end >= 0){if (a[end] > x){a[end + gap] = a[end];end -= gap;}else{break;}}a[end + gap] = x;}}
第六步:
如何通过gap提高效率? 多大的gap值最合适?
我们分析
第一点 :
gap越大,预排越快,预排后越不接近有序
gap越小,预排越慢,预排后越接近有序
第二点:
多次预排序 (gap > 1)
直接插入 (gap == 1)
第三点:
结合第二点,我们列出gap的倍数数, 其范围 [ while{ gap = gap/3 +1 } ],这些gap倍数数去进行预排序.
即gap从大到小进行作为预排值,由于,gap虽然不断的在变小,由于前面预排的操作让数据不断的接近有序,并且前期的预排很快,数据越有序那么预排越快,即插入排序越快.
第四点:
实际书本上希尔排序时间复杂度为 logN^1.3 ;
我们自己大概估算
希尔排序时间复杂度为 O( N*log(N) )
每次最好预排的时间大概为O(N) – 最快的情况是O(N^2),由于前面的预排,所以最快的情况被优化成接近O(N)
所以每次预排的时间大概为O(N).
代码实现:
int gap = n;while (gap > 1){//gap = gap / 2;gap = gap / 3 + 1;// 多组一锅炖for (int i = 0; i < n - gap; ++i){int end = i;int x = a[end + gap];while (end >= 0){if (a[end] > x){a[end + gap] = a[end];end -= gap;}else{break;}}a[end + gap] = x;}}
选择排序
堆排序
利用堆的性质, 让堆帮我们选择
void HeapSort(int* a, int n)
{// 直接把a构建成堆,直接控制a数组int root = n;while (root >0){AdjustDown(a, root);root--;}
}
// 堆排序 -- O(N*logN)
void HeapSort(int* a, int n)
{// O(N)for (int i = (n - 1 - 1) / 2; i >= 0; --i){AdjustDown(a, n, i);}// O(N*logN)int end = n - 1;while (end > 0){Swap(&a[0], &a[end]);AdjustDown(a, end, 0);--end;}
}
直接选择排序(最拉胯的排序)
基础版:
每次选最值,往数组左边堆
代码省略
优化版的:
每次在未选范围内选择最小值和最大值, 时间复杂度 O(N^2) = N + N-2 + N-4+…N-2*n
注意 : 该代码存在小bug, 已修改
// 选择排序
// 时间复杂度:O(N^2)
// 最好:O(N^2)
// 整体而言最差的排序,因为无论什么情况都是O(N^2)
void SelectSort(int* a, int n)
{int begin = 0, end = n - 1;while (begin < end){int mini = begin, maxi = begin;for (int i = begin; i <= end; ++i){if (a[i] < a[mini])mini = i;if (a[i] > a[maxi])maxi = i;}
//bugSwap(&a[begin], &a[mini]);// begin == maxi时,最大被换走了,修正一下maxi的位置if (begin == maxi)maxi = mini;Swap(&a[end], &a[maxi]);++begin;--end;}
}
交换排序
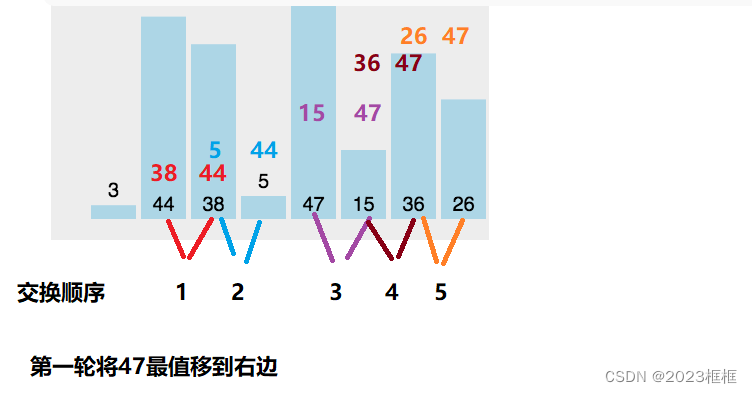
冒泡排序
核心:循环n论,每一论让交换操作让一个最值的元素移到最右侧,跟选择排序差不多,不过这是交换两个数据
时间复杂度:O(N^2)
最好:O(N)
void BubbleSort(int* a, int n)
{
// 方法一:for (int j = 0; j < n; j++){// 该循环让一个最值数不断的通过交换数据,移到最右侧for (int i = 1; i < n-j; ++i){if (a[i - 1] > a[i]){Swap(&a[i - 1], &a[i]);}}
}
// 方法二:与方法一差不多
// 用end来代替n-j
// flag变量是用来优化程序的,当循环一轮后发现没有交换,说明已经有序了,结束后续操作int end = n;while (end > 0){int flag= 0;for (int i = 1; i < end; ++i){if (a[i - 1] > a[i]){flag= 1;Swap(&a[i - 1], &a[i]);}}--end;if (flag== 0){break;}}}快速排序
核心:
任取待排序元素序列中的某元素作为基准值,按照该排序码将待排序集合分割成两子序列,左子序列中所有元素均小于基准值,右子序列中所有元素均大于基准值,然后最左右子序列重复该过程,直到所有元素都排列在相应位置上为止。
1. hoare版本
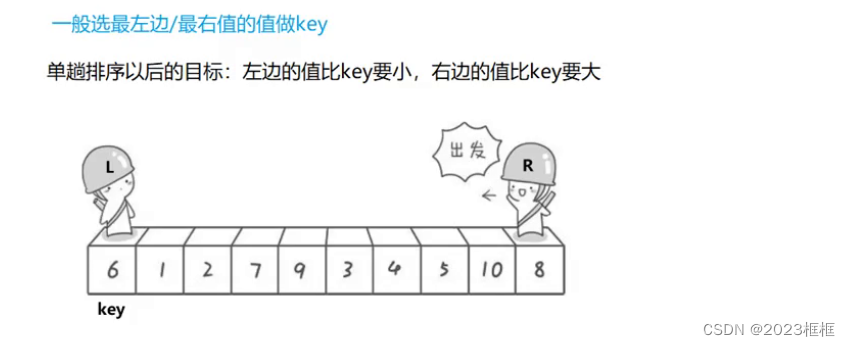
第一步:
取key值
 第二步:
第二步:
L:选比key大的元素。
R:选比key小的元素。
然后
L与R进行交换
重复如上步骤
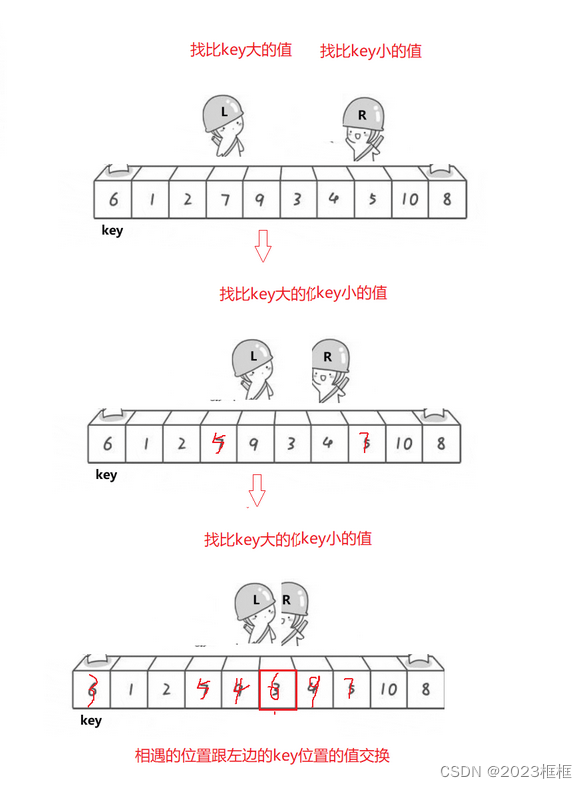
第三步:
L和R相遇,相遇的位置与key进行交换
第四步:
我们考虑到第三步的交换时,可能会出现相遇的值不是预期的值,即相遇的值可能比key大或者小,不确定。
如何解决?
选最左边的值做key,右边先走 -》》》 左右相遇比key小
选最右边的值做key,左边先走 -》》》 左右相遇比key大
我们分析选最左边的值做key,
L和R在不考虑谁先走的情况,L和R有4种情况
a.L找到了 ,R找到了 , 它们交换
b.L找到了,R没找到,R与L相遇,此时交换就出错了 erro
c.L没找到,L与R相遇 ,它们交换
d.L和R没找到,不会出现此情况
解决方法:如果我们让R先走,那么就能解决b情况。
第五步:
实现快排
// O(N*logN)
void QuickSort(int* a, int left, int right)
{if (left >= right)return;int keyi = Partion1(a, left, right);// [left, keyi-1] keyi [keyi+1, right]QuickSort(a, left, keyi - 1);QuickSort(a, keyi + 1, right);}
}
// hoare版本
// [left, right]
// O(N)
int Partion1(int* a, int left, int right)
{int keyi = left;while (left < right){// 右边先走,找小while (left < right && a[right] >= a[keyi])--right;//左边再走,找大while (left < right && a[left] <= a[keyi])++left;Swap(&a[left], &a[right]);}Swap(&a[left], &a[keyi]);return left;
}
如何解决快排缺陷?
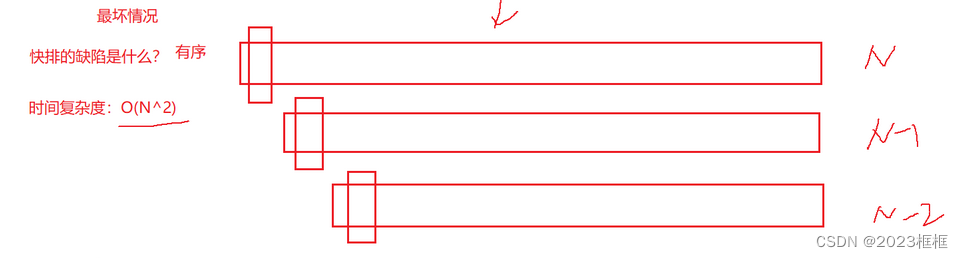
1. 快排的缺陷是什么? – 数据逆序时,时间复杂度O(N^2),递归深度深,栈溢出
最坏情况如图:
数据逆序时,时间复杂度O(N^2)
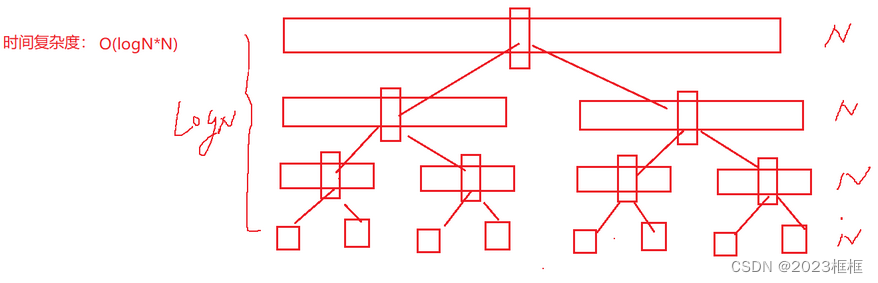
最好情况如图:
每次能取到中位数作为基准值,就是一颗二叉树的形式了
2.如何解决快排缺陷?
三数取中是让数据的最左,最右和中间的值,取一个中间数。
让中间数作为基准值。
// 三数取中
int GetMidIndex(int* a, int left, int right)
{//int mid = (left + right) / 2;int mid = left + ((right - left) >> 1);if (a[left] < a[mid]){if (a[mid] < a[right]){return mid;}else if (a[left] > a[right]){return left;}else{return right;}}else // a[left] > a[mid]{if (a[mid] > a[right]){return mid;}else if (a[left] < a[right]){return left;}else{return right;}}
}// hoare版本
// [left, right]
// O(N)
int Partion1(int* a, int left, int right)
{// 三数取中 -- 面对有序最坏情况,变成选中位数做key,变成最好情况int mini = GetMidIndex(a, left, right);Swap(&a[mini], &a[left]);int keyi = left;while (left < right){// 右边先走,找小while (left < right && a[right] >= a[keyi])--right;//左边再走,找大while (left < right && a[left] <= a[keyi])++left;Swap(&a[left], &a[right]);}Swap(&a[left], &a[keyi]);return left;
}
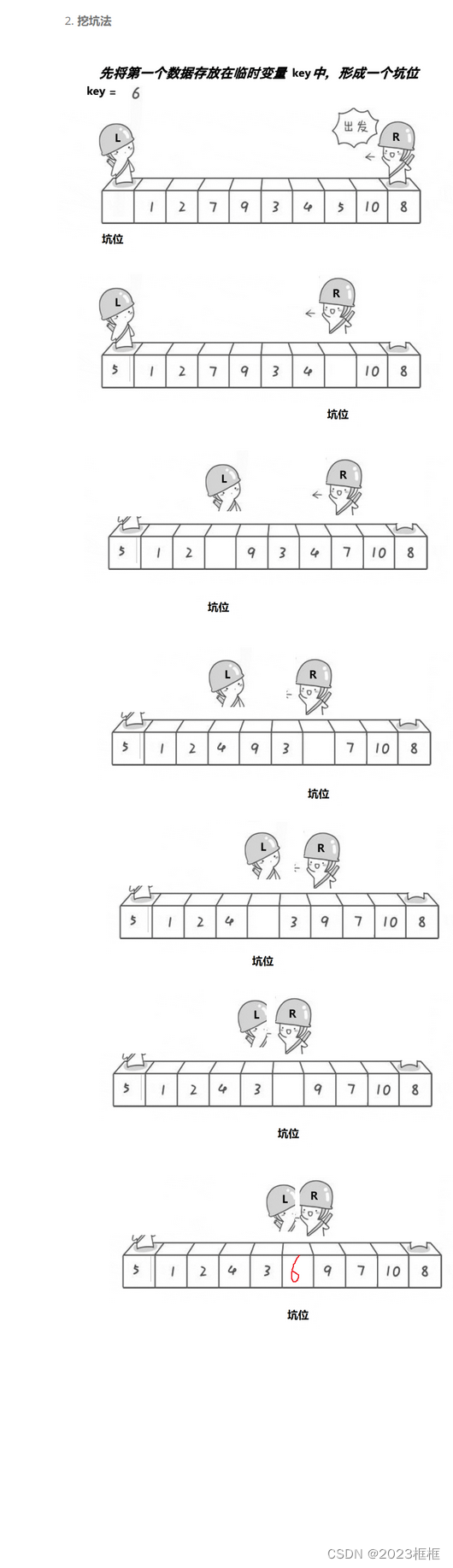
2.挖坑法版本
hoare版本的变形,我们不需要考虑谁先走的问题了。
算法步骤:
a. 为占坑位的找值,然后填坑,自己作为坑位
b. 最后相遇以后,将key值放到坑里
算法实现:
// 挖坑法
int Partion2(int* a, int left, int right)
{// 三数取中 -- 面对有序最坏情况,变成选中位数做key,变成最好情况int mini = GetMidIndex(a, left, right);Swap(&a[mini], &a[left]);int key = a[left];int pivot = left;while (left < right){// 右边找小, 放到左边的坑里面while (left < right && a[right] >= key){--right;}a[pivot] = a[right];pivot = right;// 左边找大,放到右边的坑里面while (left < right && a[left] <= key){++left;}a[pivot] = a[left];pivot = left;}a[pivot] = key;return pivot;
}
3.双指针法版本(建议)
// 推荐掌握这个 -- 思想三种大家都要掌握
int Partion3(int* a, int left, int right)
{// 三数取中 -- 面对有序最坏情况,变成选中位数做key,变成最好情况int mini = GetMidIndex(a, left, right);Swap(&a[mini], &a[left]);int keyi = left;int prev = left;int cur = prev + 1;while (cur <= right){if (a[cur] < a[keyi] && ++prev != cur){Swap(&a[cur], &a[prev]);}++cur;}Swap(&a[prev], &a[keyi]);return prev;
}
快排算法优化
我们发现快排在递归时,最后几层递归次数占总体的大部分,因此我们对最后几层的递归改用插入排序,进行分割排序。
// O(N*logN)
void QuickSort(int* a, int left, int right)
{if (left >= right)return;// 小区间优化,当分割到小区间时,不再用递归分割思路让这段子区间有序// 对于递归快排,减少递归次数// 常数10是不确定的,因为这个优化并不是决定性的if (right - left + 1 < 10){// InsertSort()为插入排序InsertSort(a + left, right - left + 1);}else{int keyi = Partion3(a, left, right);// [left, keyi-1] keyi [keyi+1, right]QuickSort(a, left, keyi - 1);QuickSort(a, keyi + 1, right);}
}
实现非递归快排
递归深度太深会栈溢出,我们可以改用非递归实现。
// 递归深度太深的程序,只能考虑改非递归
void QuickSortNonR(int* a, int left, int right)
{stack<int> st;st.push(left);st.push(right);while (!st.empty()){int end = st.top();st.pop();int begin = st.top();;st.pop();int keyi = Partion3(a, begin, end);// [begin, keyi-1] keyi [keyi+1, end]if (keyi + 1 < end){st.push(keyi + 1);st.push(end);}if (begin < keyi - 1){st.push(begin);st.push(keyi - 1);}}}
归并排序
归并排序
总结:
- 归并的缺点在于需要O(N)的空间复杂度,归并排序的思考更多的是解决在磁盘中的外排序问题。
- 时间复杂度:O(N*logN)
- 空间复杂度:O(N)
- 稳定性:稳定
基本思想:
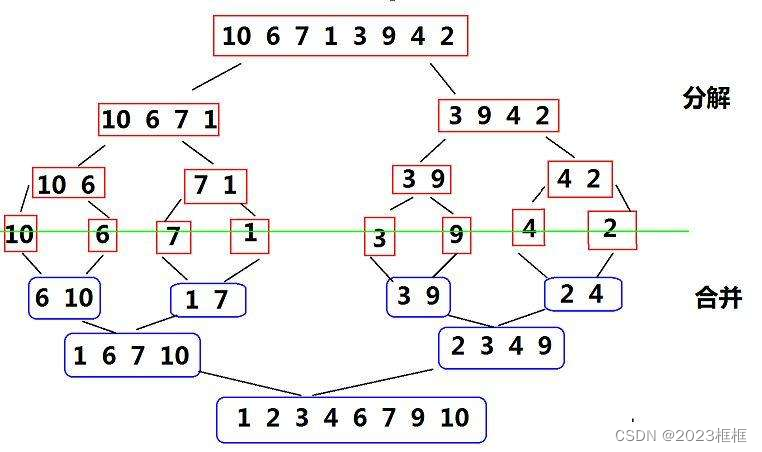
归并排序(MERGE-SORT)是建立在归并操作上的一种有效的排序算法,该算法是采用分治法(Divide andConquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并。
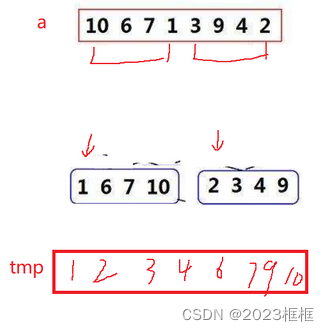
归并排序核心步骤:
将a数组进行排序,划分成了两个子序列,假设两个子序列已经排好序了,接下来归并到tmp数组里,使两个子序列合并成有序的,然后将tmp数组拷贝到原数组里。
递归实现:
void _MergeSort(int* a, int left, int right, int* tmp)
{if (left >= right){return;}int mid = (left + right) / 2;// [left, mid] [mid+1, right] 有序_MergeSort(a, left, mid, tmp);_MergeSort(a, mid + 1, right, tmp);int begin1 = left, end1 = mid;int begin2 = mid+1, end2 = right;int i = left;while (begin1 <= end1 && begin2 <= end2){if (a[begin1] < a[begin2]){tmp[i++] = a[begin1++];}else{tmp[i++] = a[begin2++];}}while (begin1 <= end1){tmp[i++] = a[begin1++];}while (begin2 <= end2){tmp[i++] = a[begin2++];}// tmp 数组拷贝回afor (int j = left; j <= right; ++j){a[j] = tmp[j];}
}void MergeSort(int* a, int n)
{int* tmp = (int*)malloc(sizeof(int)*n);if (tmp == NULL){printf("malloc fail\\n");exit(-1);}_MergeSort(a, 0, n - 1, tmp);free(tmp);tmp = NULL;
}
非递归实现:
第一步:
【框架搭好】
使用用循环来实现归并排序,按照层序的方式归并,第一层是1 个元素的两个序列进行归并,第二层是2个元素的两个有序序列进行归并,以此类推。
注意:这个代码存在边界问题,下面进行处理
void MergeSortNonR(int* a, int n)
{int* tmp = (int*)malloc(sizeof(int)*n);if (tmp == NULL){printf("malloc fail\\n");exit(-1);}
// gap控制子序列长度int gap = 1;while (gap < n){for (int i = 0; i < n; i += 2 * gap){// [i,i+gap-1] [i+gap,i+2*gap-1]int begin1 = i, end1 = i + gap - 1;int begin2 = i + gap, end2 = i + 2 * gap - 1;int index = i;while (begin1 <= end1 && begin2 <= end2){if (a[begin1] < a[begin2]){tmp[index++] = a[begin1++];}else{tmp[index++] = a[begin2++];}}while (begin1 <= end1){tmp[index++] = a[begin1++];}while (begin2 <= end2){tmp[index++] = a[begin2++];}// 把归并小区间拷贝回原数组for (int j = i; j <= end2; ++j){a[j] = tmp[j];}}gap *= 2;}free(tmp);tmp = NULL;
}
第二步:
【边界控制】
核心思想:end1、begin2、end2都有可能越界,通过调整这三个值来控制边界,让其不会越界错误
版本一:
void MergeSortNonR(int* a, int n)
{int* tmp = (int*)malloc(sizeof(int)*n);if (tmp == NULL){printf("malloc fail\\n");exit(-1);}int gap = 1;while (gap < n){for (int i = 0; i < n; i += 2 * gap){// [i,i+gap-1] [i+gap,i+2*gap-1]int begin1 = i, end1 = i + gap - 1;int begin2 = i+gap, end2 = i + 2*gap-1;//printf("[%d,%d][%d,%d]", begin1, end1, begin2, end2);// end1 越界,[begin2,end2]不存在if (end1 >= n){end1 = n - 1;}//[begin1,end1]存在 [begin2,end2]不存在if (begin2 >= n){begin2 = n;end2 = n - 1;}if (end2 >= n){end2 = n - 1;}//printf("[%d,%d][%d,%d]", begin1, end1, begin2, end2);int index = i;while (begin1 <= end1 && begin2 <= end2){//printf(" %d ", index);if (a[begin1] < a[begin2]){tmp[index++] = a[begin1++];}else{tmp[index++] = a[begin2++];}}while (begin1 <= end1){//printf(" %d ", index);tmp[index++] = a[begin1++];}while (begin2 <= end2){//printf(" %d ", index);tmp[index++] = a[begin2++];}}printf("\\n");// 把归并数据拷贝回原数组for (int i = 0; i < n; ++i){a[i] = tmp[i];}gap *= 2;}free(tmp);tmp = NULL;
}
改进版本一:
void MergeSortNonR(int* a, int n)
{int* tmp = (int*)malloc(sizeof(int)*n);if (tmp == NULL){printf("malloc fail\\n");exit(-1);}int gap = 1;while (gap < n){for (int i = 0; i < n; i += 2 * gap){// [i,i+gap-1] [i+gap,i+2*gap-1]int begin1 = i, end1 = i + gap - 1;int begin2 = i + gap, end2 = i + 2 * gap - 1;// 核心思想:end1、begin2、end2都有可能越界// end1越界 或者 begin2 越界都不需要归并// 原数组 【begin1,n-1】是有序的,现在不合法归并条件,我们不进行归并处理就可以了if (end1 >= n || begin2 >= n){break;}// end2 越界,需要归并,修正end2if (end2 >= n){end2 = n- 1;}int index = i;while (begin1 <= end1 && begin2 <= end2){if (a[begin1] < a[begin2]){tmp[index++] = a[begin1++];}else{tmp[index++] = a[begin2++];}}while (begin1 <= end1){tmp[index++] = a[begin1++];}while (begin2 <= end2){tmp[index++] = a[begin2++];}// 把归并小区间拷贝回原数组for (int j = i; j <= end2; ++j){a[j] = tmp[j];}}gap *= 2;}free(tmp);tmp = NULL;
}
非比较排序
计数排序
核心:
计数排序又称为鸽巢原理,是对哈希直接定址法的变形应用。
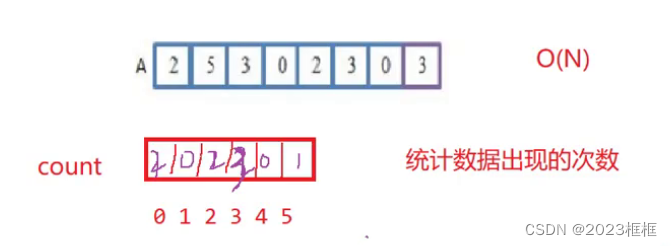
第一步:
统计数据出现的次数,开辟一个count数组统计A数组的所有元素的个数。
如下图:
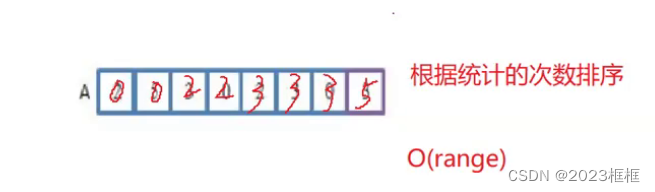
第二步:
根据统计的次数count数组,进行排序
第三步:
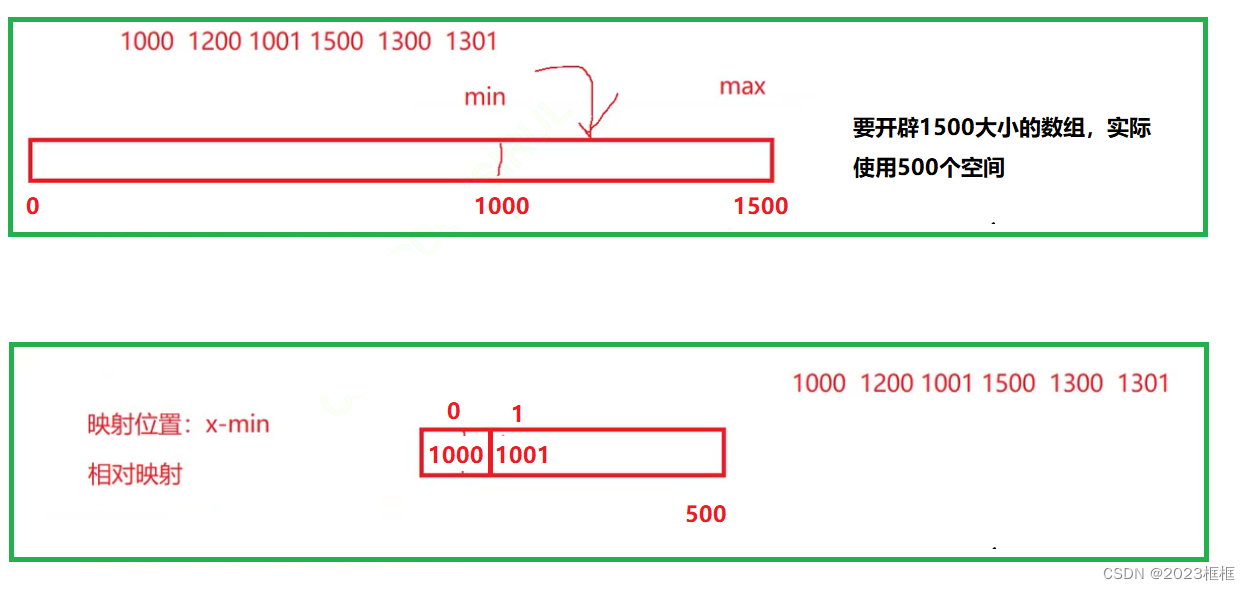
计数排序的空间优化,如下这组数据 【1000,1200,1001,1500,1300,1301】,
min:1000,max=1500,我们需要开辟1500个元素空间进行统计。
优化步骤:
a.相对映射
b.我们只需要开辟max-min个元素空间
c.映射位置=x-min , x为元素
如图:
实现代码:
// 时间复杂度:O(Max(N, Range))
// 空间复杂度:O(range)
// 适合范围比较集中的整数数组
// 范围较大,或者是浮点数等等都不适合排序了
void CountSort(int* a, int n)
{int max = a[0], min = a[0];for (int i = 1; i < n; ++i){if (a[i] > max){max = a[i];}if (a[i] < min){min = a[i];}}int range = max - min + 1;int* count = (int*)malloc(sizeof(int)*range);memset(count, 0, sizeof(int)*range);if (count == NULL){printf("malloc fail\\n");exit(-1);}// 统计次数for (int i = 0; i < n; ++i){count[a[i] - min]++;}// 根据次数,进行排序int j = 0;for (int i = 0; i < range; ++i){while (count[i]--){a[j++] = i + min;}}
}
外排序
假设文件上有10亿个数据要进行排序,内存中只能存放1000w的数据,如何排序?
解题步骤:
- 将10亿个数据切分成1000个小文件。
- 将小文件加载到内存进行排序,写入回小文件里。
- 如图1,file1和file2归并mfile文件里。
- 如图2,file1=mfile,mfile=123,file2=3,将file1和file2归并到mfile文件里。
- 如此类推,
- 注意:处理上述方法还有其他方法可以实现,相对于其他方法这个比较简单,但效率差。
图1:
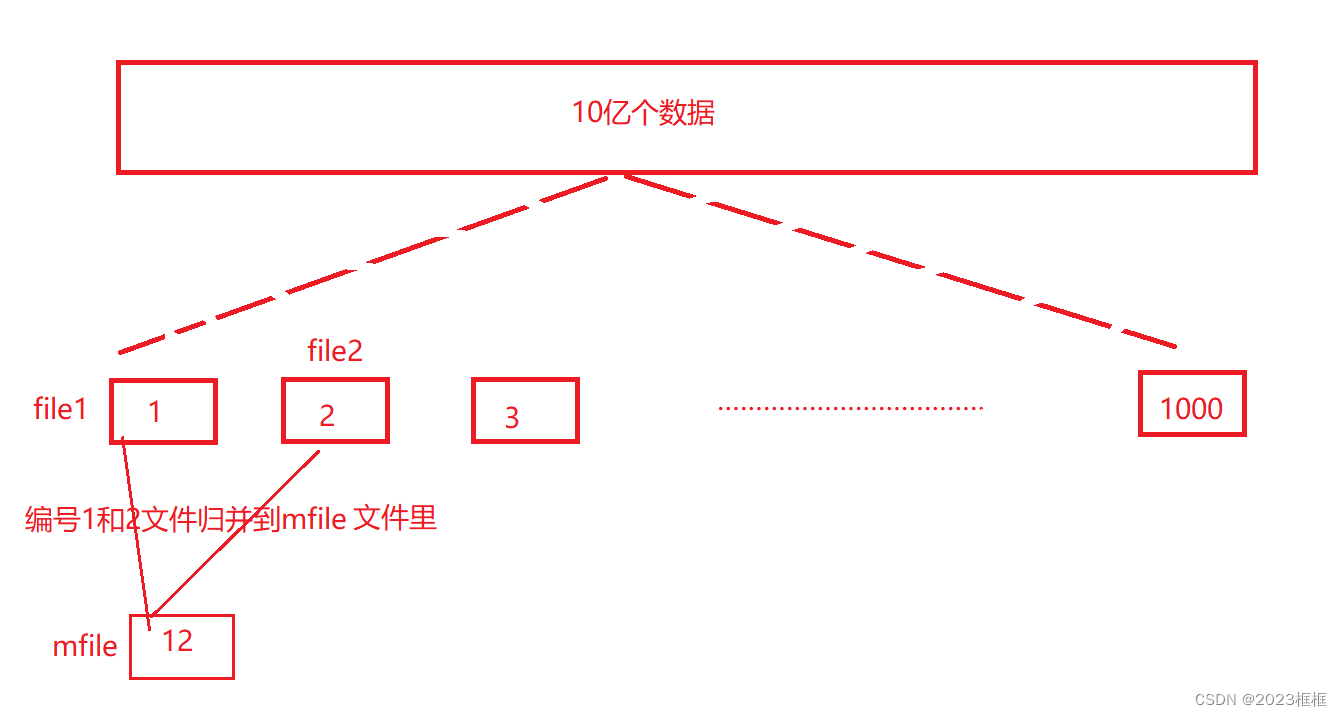
图2:
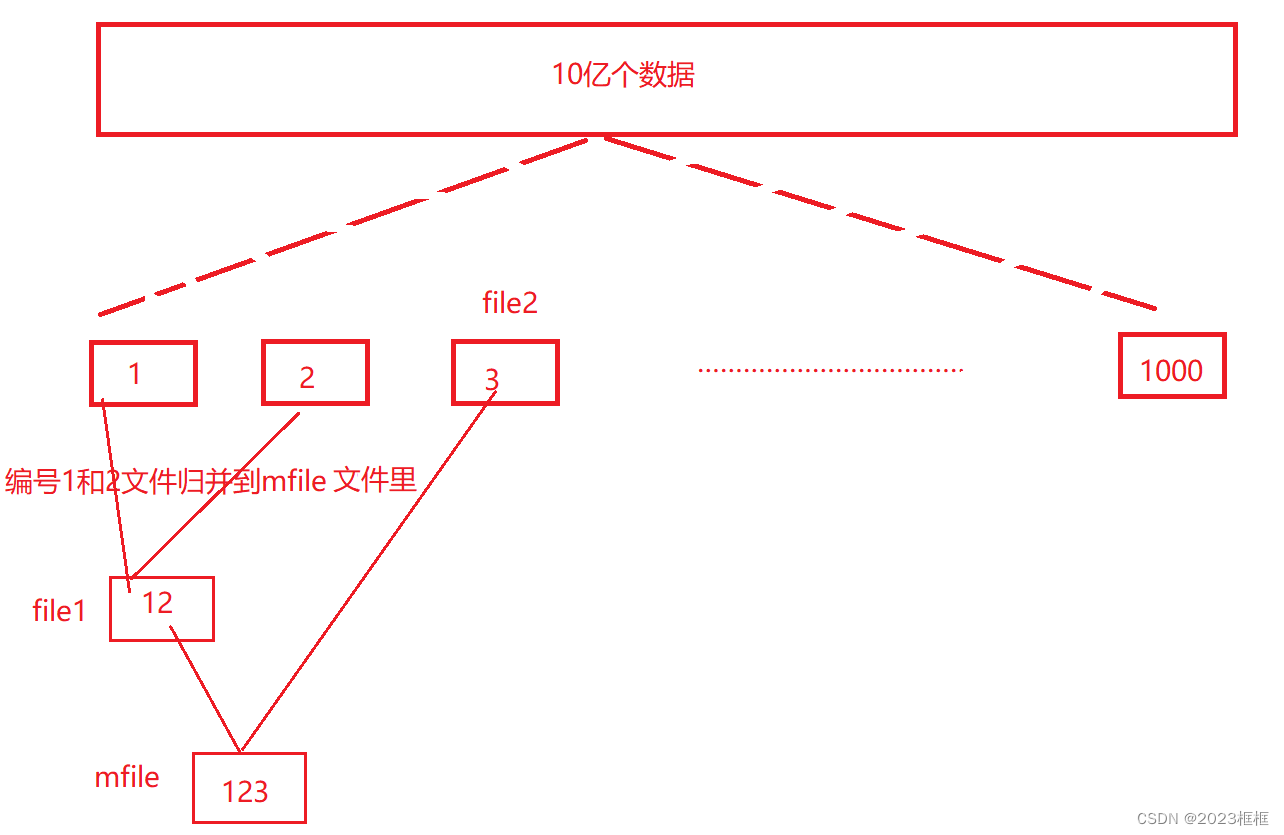
代码实现:
void _MergeFile(const char* file1, const char* file2, const char* mfile)
{FILE* fout1 = fopen(file1, "r");if (fout1 == NULL){printf("打开文件失败\\n");exit(-1);}FILE* fout2 = fopen(file2, "r");if (fout2 == NULL){printf("打开文件失败\\n");exit(-1);}FILE* fin = fopen(mfile, "w");if (fin == NULL){printf("打开文件失败\\n");exit(-1);}int num1, num2;int ret1 = fscanf(fout1, "%d\\n", &num1);int ret2 = fscanf(fout2, "%d\\n", &num2);while (ret1 != EOF && ret2 != EOF){if (num1 < num2){fprintf(fin, "%d\\n", num1);ret1 = fscanf(fout1, "%d\\n", &num1);}else{fprintf(fin, "%d\\n", num2);ret2 = fscanf(fout2, "%d\\n", &num2);}}while (ret1 != EOF){fprintf(fin, "%d\\n", num1);ret1 = fscanf(fout1, "%d\\n", &num1);}while (ret2 != EOF){fprintf(fin, "%d\\n", num2);ret2 = fscanf(fout2, "%d\\n", &num2);}fclose(fout1);fclose(fout2);fclose(fin);
}void MergeSortFile(const char* file)
{FILE* fout = fopen(file, "r");if (fout == NULL){printf("打开文件失败\\n");exit(-1);}// 分割成一段一段数据,内存排序后写到,小文件,int n = 10;int a[10];int i = 0;int num = 0;char subfile[20];int filei = 1;memset(a, 0, sizeof(int)*n);while (fscanf(fout, "%d\\n", &num) != EOF){if (i < n - 1){a[i++] = num;}else{a[i] = num;QuickSort(a, 0, n - 1);sprintf(subfile, "%d", filei++);FILE* fin = fopen(subfile, "w");if (fin == NULL){printf("打开文件失败\\n");exit(-1);}for (int j = 0; j < n; j++){fprintf(fin, "%d\\n", a[j]);}fclose(fin);i = 0;memset(a, 0, sizeof(int)*n);}}// 利用互相归并到文件,实现整体有序char mfile[100] = "12";char file1[100] = "1";char file2[100] = "2";for (int i = 2; i <= n; ++i){// 读取file1和file2,进行归并出mfile_MergeFile(file1, file2, mfile);strcpy(file1, mfile);sprintf(file2, "%d", i + 1);sprintf(mfile, "%s%d", mfile, i + 1);}printf("%s文件排序成功\\n", file);fclose(fout);
}int main()
{MergeSortFile("SortData.txt");return 0;
}