【YOLO系列】YOLOv1论文笔记

论文链接:[1506.02640] You Only Look Once: Unified, Real-Time Object Detection (arxiv.org)

YOLO将目标检测看作回归问题,使用单个神经网络直接从完整图像上预测边界框和类别概率。(端到端:输入原始数据,输出的是最后结果,之前输入端是在原始数据中提取的特征)

YOLO过程总结:
训练阶段:
首先将一张图像分成 S × S个 gird cell,然后全部送入CNN,生成S × S × (B × 5 + C)个结果,最后根据结果求Loss并反向传播梯度下降。
(S x S个网格,每个网格都有B个预测框,每个框有5个参数,再加上每个网格都有C个预测类)
预测、验证阶段:
首先将一张图像分成 S × S网格(gird cell),然后全部送入CNN,生成S × S × (B × 5 + C)个结果,最后用NMS选出合适的预选框。
(NMS:主要解决一个目标被多次检测的问题,即在一个区域里交叠的很多框选一个最优的。
注意: NMS只发生在预测阶段,训练阶段是不能用NMS的,因为在训练阶段不管这个框是否用于预测物体的,它都和损失函数相关,不能随便重置成0。)
YOLO思想
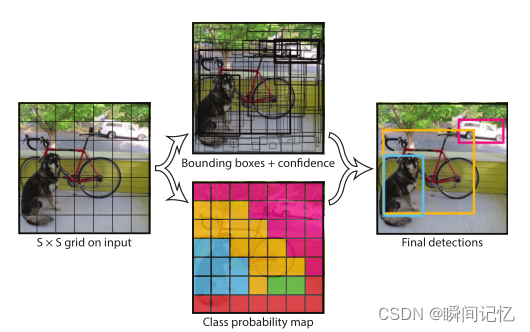
YOLO将目标检测问题作为回归问题。会将输入图像分成S×S的网格,如果一个物体的中心点落入到一个cell中,那么该cell就要负责预测该物体,一个格子只能预测一个物体,会生成两个预测框。
对于每个grid cell:
(1)预测B个边界框,每个框都有一个置信度分数(confidence score)这些框大小尺寸等等都随便,只有一个要求,就是生成框的中心点必须在grid cell里。
(2)每个边界框包含5个元素:(x,y,w,h)
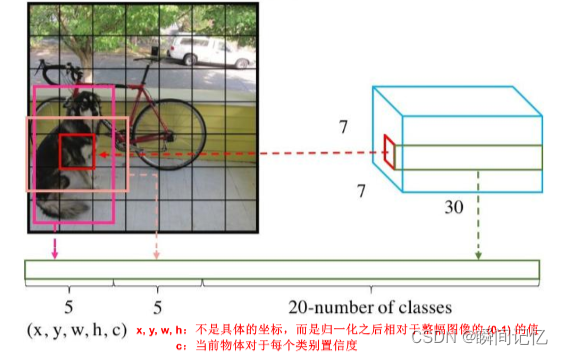
(3)不管框 B 的数量是多少,只负责预测一个目标。
(4)预测 C 个条件概率类别(物体属于每一种类别的可能性)
YOLO网络详解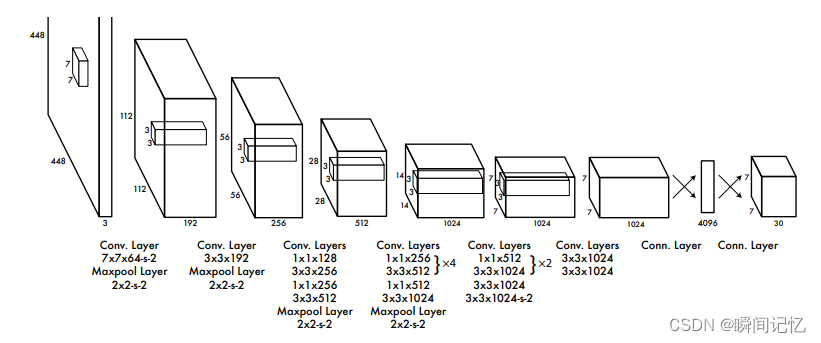
YOLO优点:
(1)YOLO的速度非常快;
(2)YOLO在做预测时使用的是全局图像;
(3)YOLO 学到物体更泛化的特征表示。
YOLO缺点:
(1)对于图片中一些群体性小目标检测效果比较差;
(2)原始图片只划分为7x7的网格,当两个物体靠得很近时(挨在一起且中点都落在同一个格子上的情况),效果比较差;
(3)每个网格只对应两个bounding box,当物体的长宽比不常见(也就是训练数据集覆盖不到时),效果较差;
(4)最终每个网格只对应一个类别,容易出现漏检(物体没有被识别到)。
参考链接:【YOLO系列】YOLOv1论文超详细解读(翻译 +学习笔记)_路人贾'ω'的博客-CSDN博客