doccano使用记录

参考文章:https://github.com/PaddlePaddle/PaddleNLP/blob/develop/model_zoo/uie/doccano.md
参考文章:https://github.com/doccano/doccano
参考文章:https://doccano.github.io/doccano/
参考文章:https://zhuanlan.zhihu.com/p/371752234
系统: Ubuntu 20.04.4 LTS (GNU/Linux 5.4.0-146-generic x86_64)
Python: 3.8.10
doccano
安装
使用下面的语句来安装,注意仅支持3.8以上的python。
pip install doccano
默认情况下,SQLite 3 用于默认数据库。如果要使用 PostgreSQL,请安装额外的依赖项:
pip install 'doccano[postgresql]'
并DATABASE_URL根据您的 PostgreSQL 凭据设置环境变量:
DATABASE_URL="postgres://${POSTGRES_USER}:${POSTGRES_PASSWORD}@${POSTGRES_HOST}:${POSTGRES_PORT}/${POSTGRES_DB}?sslmode=disable"
初始化doccano数据库
doccano init
创建一个super user。这里要把pass改成你需要的密码。当然,用户名也可以改成别的。
doccano createuser --username admin --password 123456
启动webserver
参考文章:https://doccano.github.io/doccano/faq/#how-to-create-a-user
首先,在终端中运行下面的代码来启动WebServer
doccano webserver --port 30003
然后,打开另一个终端,运行下面的代码启动任务队列:
doccano task
然后在电脑中打开http://127.0.0.1:30003/,使用刚刚的账号即可登陆。
在浏览器输入http://127.0.0.1:30003/admin/即可进行修改密码,新增用户等操作。
使用
参考文章:https://github.com/PaddlePaddle/PaddleNLP/blob/develop/model_zoo/uie/doccano.md
创建项目
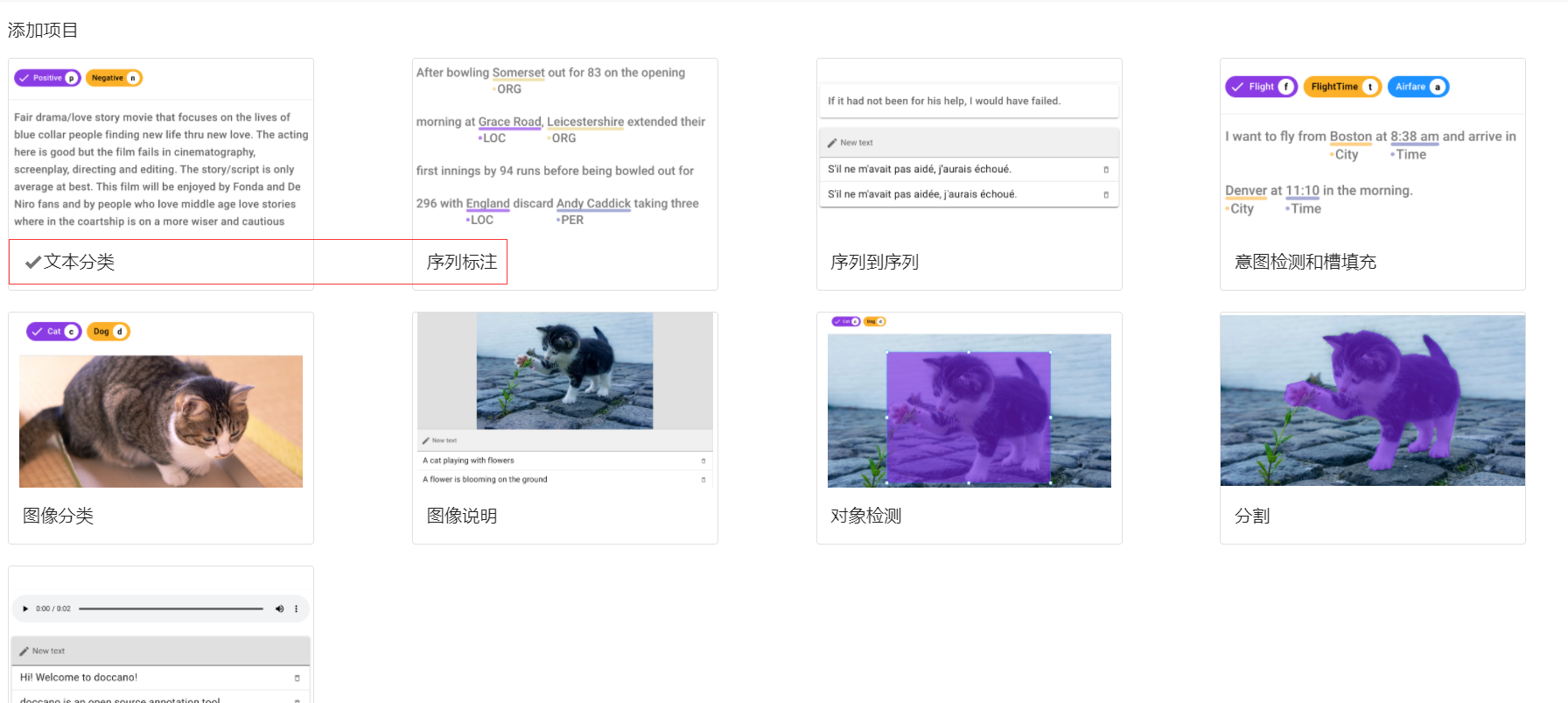
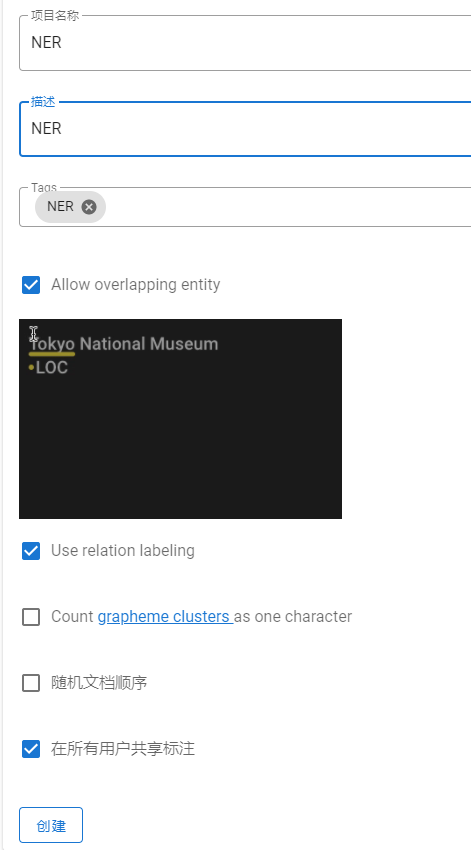
创建项目时选择序列标注任务,并勾选Allow overlapping entity及Use relation Labeling。适配命名实体识别、关系抽取、事件抽取、评价观点抽取等任务。
创建项目时选择文本分类任务。适配文本分类、句子级情感倾向分类等任务。
下面是序列标注的子选项
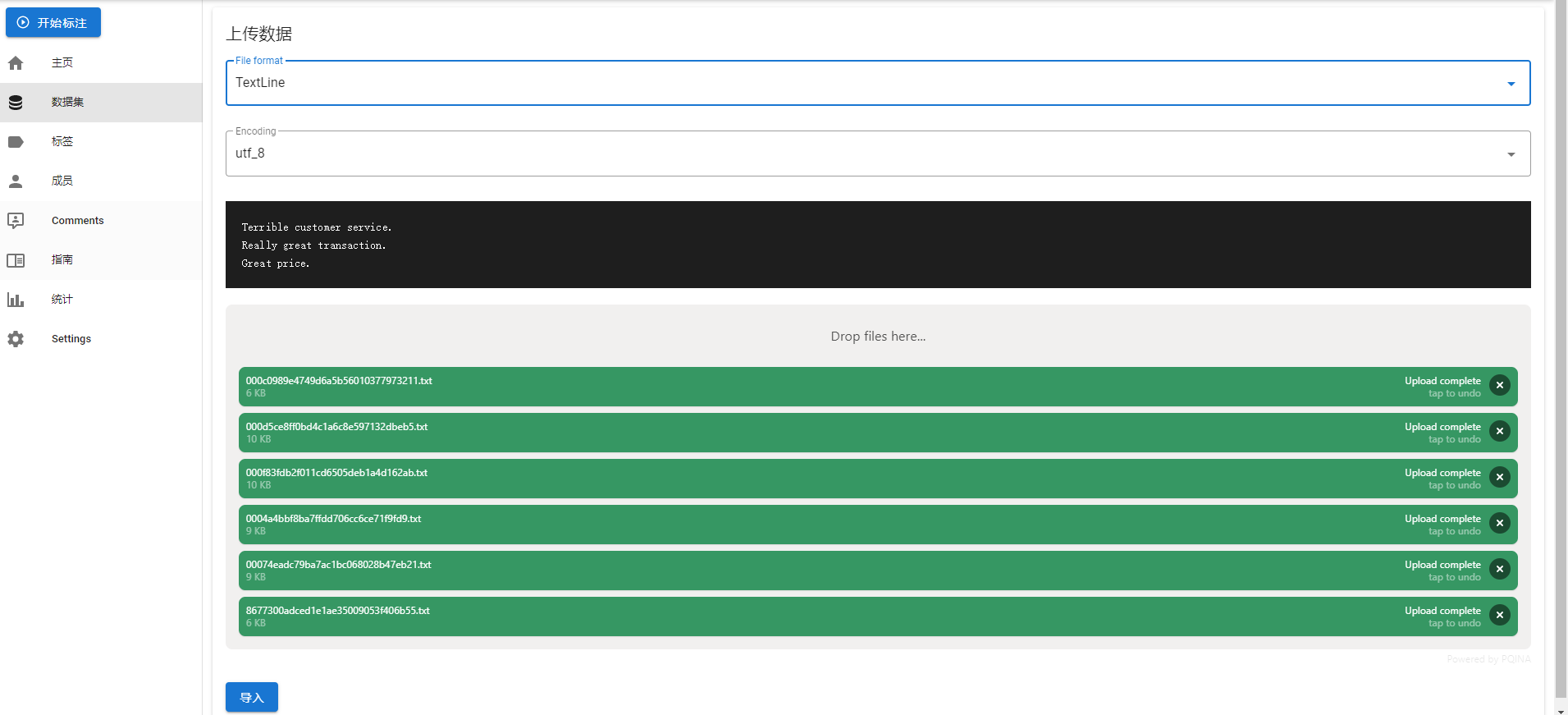
导入数据集
标签构建
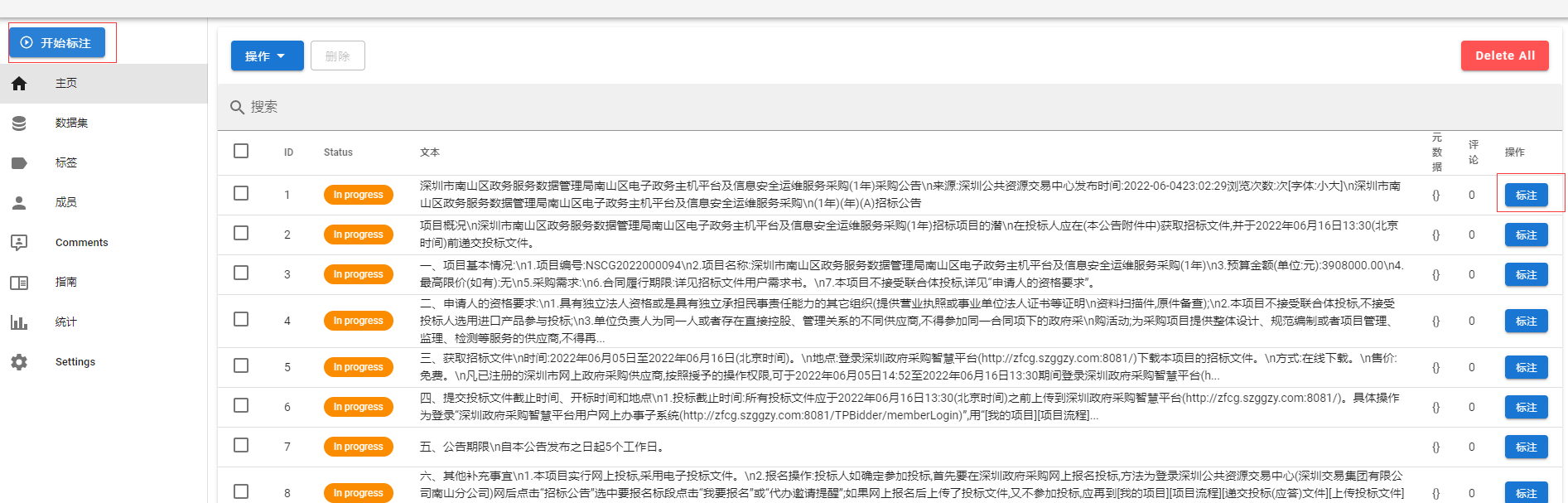
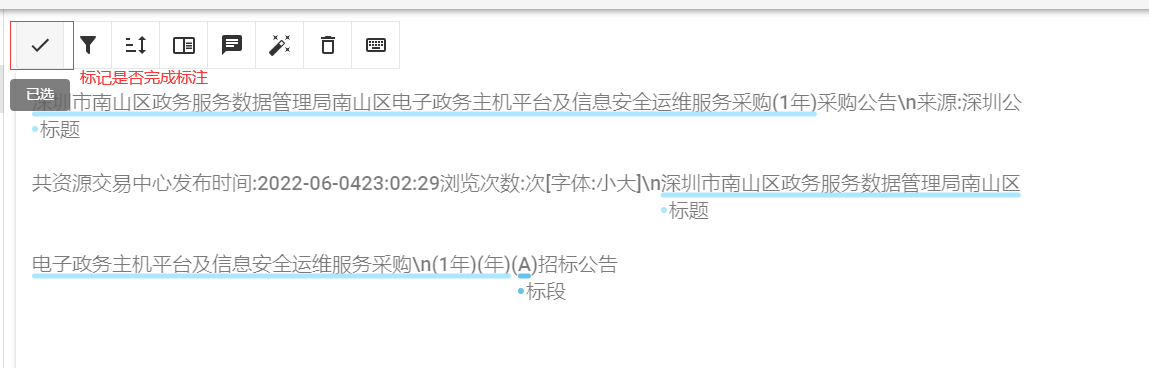
任务标注
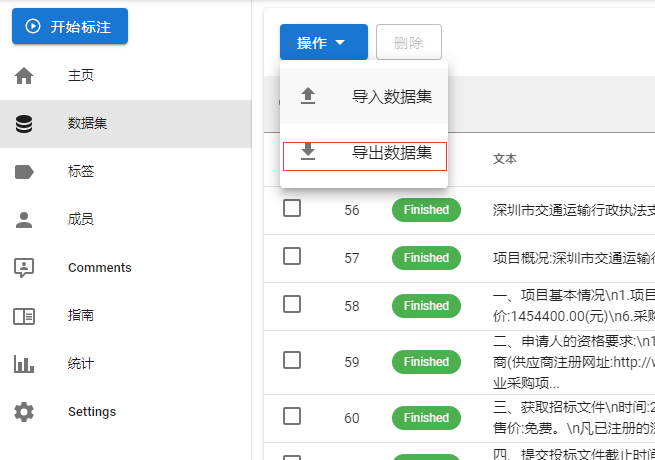
数据导出
抽取式和实体/评价维度级分类任务数据
{ "id" : 56,
"text" : "深圳市交通运输行政执法支队2023年交通执法后勤物资配送服务项目1标采购公告\\\\n来源:深圳公共资源交易中心发布时间:2023-03-1318:54:04浏览次数:次[字体:]",
"entities" :[{ "id" : 92,
"label" : "标题",
"start_offset" : 0,
"end_offset" : 36 },{ "id" : 169,
"label" : "标段",
"start_offset" : 32,
"end_offset" : 34 }],
"relations" :[],
"Comments" :[]}
标注数据保存在同一个文本文件中,每条样例占一行且存储为json格式,其包含以下字段
- id: 样本在数据集中的唯一标识ID。
- text: 原始文本数据。
- entities: 数据中包含的Span标签,每个Span标签包含四个字段:
- id: Span在数据集中的唯一标识ID。
- start_offset: Span的起始token在文本中的下标。
- end_offset: Span的结束token在文本中下标的下一个位置。
- label: Span类型。
- relations: 数据中包含的Relation标签,每个Relation标签包含四个字段:
- id: (Span1, Relation, Span2)三元组在数据集中的唯一标识ID,不同样本中的相同三元组对应同一个ID。
- from_id: Span1对应的标识ID。
- to_id: Span2对应的标识ID。
- type: Relation类型。
句子级分类任务数据
{"id": 41,"data": "大年初一就把车前保险杠给碰坏了,保险杠和保险公司 真够倒霉的,我决定步行反省。","label": ["负向"]
}
- id: 样本在数据集中的唯一标识ID。
- data: 原始文本数据。
- label: 文本对应类别标签。