对比yolov4和yolov3

目录
1. 网络结构的不同
1.1 Backbone
1.1.1 Darknet53
1.1.2 CSPDarknet53
1.2 Neck
1.2.1 FPN
1.2.2 PAN
1.2.3 SPP
1.3 Head
2. 数据增强
2.1 CutMix
2.2 Mosaic
3. 激活函数
4. 损失函数
5. 正则化方法
知识点
记录备忘。
总体而言,yolov4是尝试组合一堆tricks,获取得到的模型,该模型具有训练更快、模型更轻、精度更高的特性。
1. 网络结构的不同
yolov4网络结构可分为以下三部分。其中backbone和neck不同,head是一样的。

1.1 Backbone
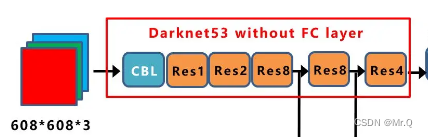
yolov3是Darknet53, yolov4是CSPDarknet53(并配合使用了SPP block增加感受野)。
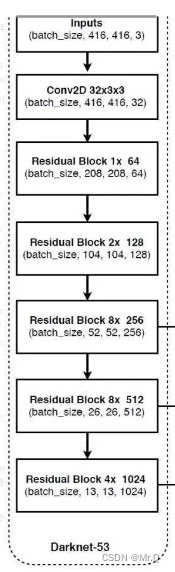
1.1.1 Darknet53
属于全卷积网络结构。
(1)整体可分为1个普通的3x3核,步长为2的卷积,再接5个layer;
(2)每个layer堆叠了大量的残差块Residual Block,且每个layer之间插入一个步长为2,3x3的卷积,完成下采样过程;
(3)如果输入的是416x416,则输出三个尺度:52x52x256, 26x26x512, 13x13x1024.
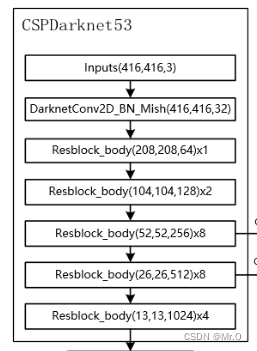
1.1.2 CSPDarknet53
CSPDarknet53是在Darknet53的基础上加了CSP block. csp block的特点是充分利用跨层信息:使用Cross Stage Partial Network结构,将输入特征图分成两个部分,然后通过跨层连接来结合这两个部分的信息。这样可以在减少计算复杂度的同时,提高网络的感受野和特征表达能力。
(1)Darknet53是由一系列residual block组成;
(2)而CSPDarknet53则是在每个卷积层CBM后追加CSP blocks. 如下图所示。
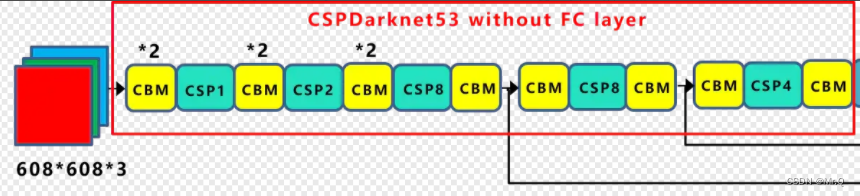
图中CBL = conv + BN + Leaky relu;CBM = conv + BN + Mish. 即激活函数换成平滑非单调的Mish激活函数(后面会详细介绍)。
CSP网络结构
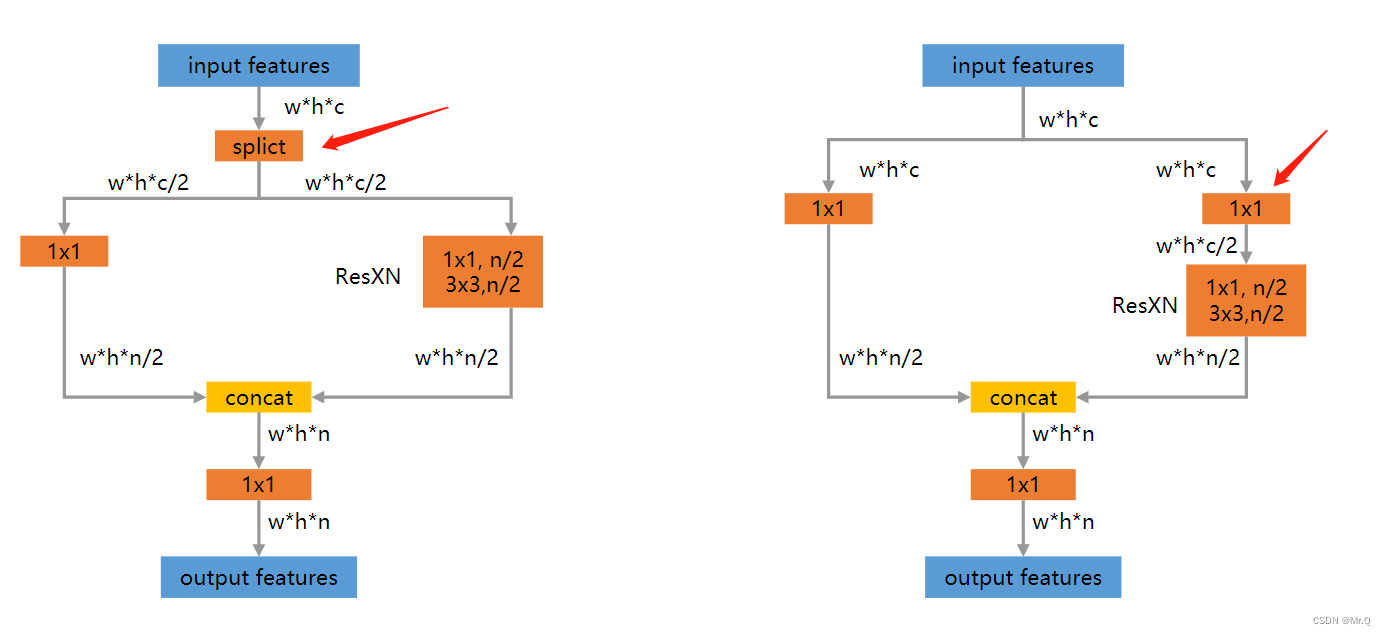
在进入多个残差块之前,左右两种方式都将通道数减半,坐边是简单的splict函数直接拆分通道,右边是通过1x1的卷积。通道数减半后,再进入残差块,计算量就少了。
实际的算法实现通常是采用第二种,一个是方便部署(模型转换时估计不支持split函数),一个是1x1的卷积操作使得两个分支都充分的使用到了输入的全部特征,而不是一半。具体实现如下所示。

1.2 Neck
特征融合方式,yolov3使用的是FPN,而yolov4组合使用了SPP和PAN.

1.2.1 FPN
FPN,Feature Pyramid Network结构示意图如下。FPN结构通过上采样不断的融合不同尺度的特征,得到多尺度的输出,使得网络能够预测多尺度目标。
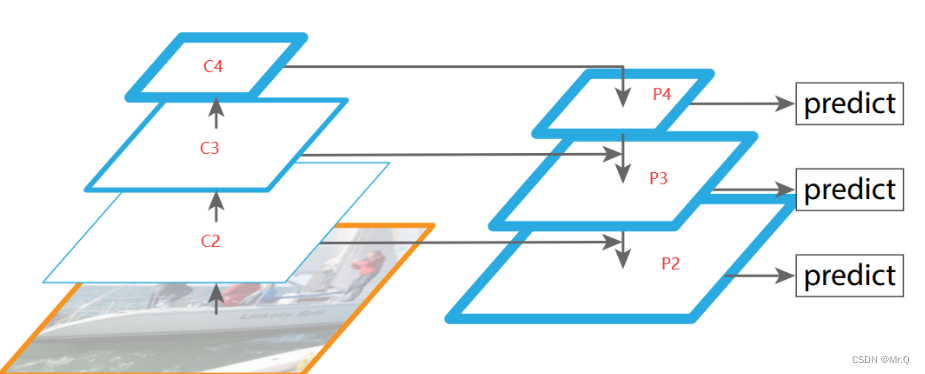
yolov3中的Darknet53输出三种尺度的特征(b,1024,13,13), (b,512,26,26), (b,256,52,52),经过FPN结构输出的对应结果尺度是(b,num_anchor*(5+num_cls),13,13), (b,num_anchor*(5+num_cls),26,26), (b,num_anchor*(5+num_cls),52,52).
yolov3中FPN结构如下。
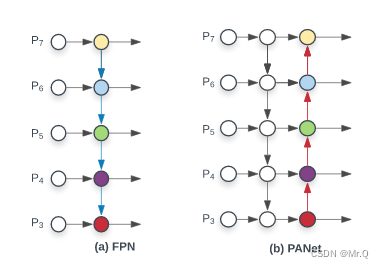
1.2.2 PAN
PAN, Path Aggregation Network(路径聚合网络)网络结构如下。左边和右边的PAN区别在于不同尺度特征融合方式,左边是相加、右边是concat方式。
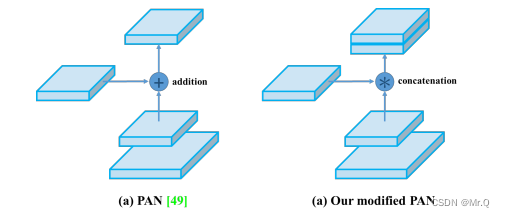
FPN(Feature Pyramid Network)和PAN(Path Aggregation Network)是两种常用于多尺度目标检测和语义分割任务的神经网络模型,它们的相同点和不同点如下所述:
相同点:多尺度特征融合,FPN和PAN都采用类似的特征金字塔结构来融合不同尺度的特征,以捕捉目标物体的多尺度信息。
不同点:连接方式不同,FPN是自顶向下的路径,从而形成一个单一的特征金字塔。而PAN则包含了自顶向下和自下而上的路径,路径更多,以实现不同分辨率的特征融合。
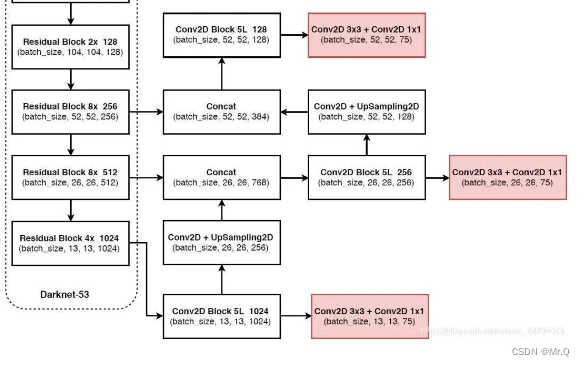
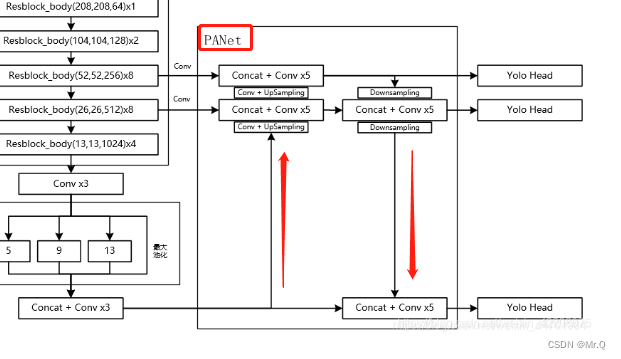
yolov4中PAN结构如下。
1.2.3 SPP
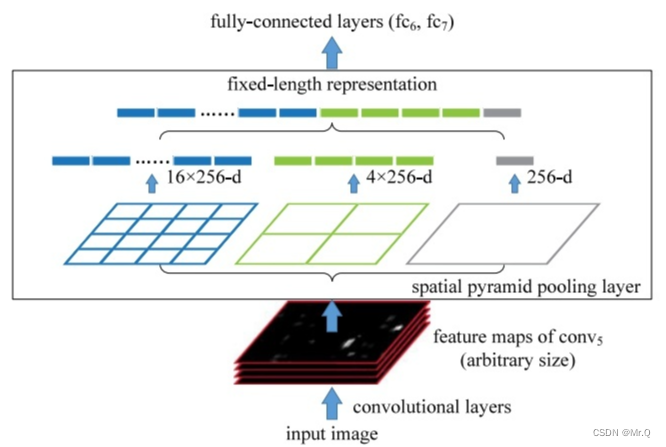
SPP,Spatial Pyramid Pooling结构如下。下面是传统意义上的SPP结构,通过把输出划分成不同的网格数,每个网格使用不同尺度核大小的maxpool。输出固定大小的向量。
如下图所示,每个网络输出一个值,有256个通道,则最大池化后,输出的向量维度是固定的,左边的4x4个网格,输出向量维度是16x256,中间是2x2个网格,输出向量维度是4x256,右边是1x1的网格,输出向量维度是256. 最后的拼接在一起,所以最后的向量维度是固定的。方便分类网络兼容多尺度输入。
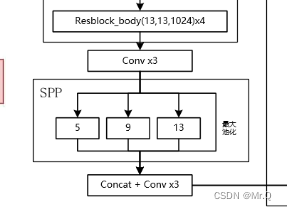
yolov4中的SPP结构如下。可以看到有4个分支,每个分支都是最大池化,从左往右最大池化核大小是k={5x5, 9x9, 13x13, 1x1}. 采用了padding操作,使其输出不改变尺度。
1.3 Head
yolov3和yolov4的head是一样的,都基于anchor,输出多个尺度结果:
(b,num_anchor*(5+num_cls),13,13).
(b,num_anchor*(5+num_cls),26,26).
(b,num_anchor*(5+num_cls),52,52).
2. 数据增强
YOLOv4在数据增强方面比YOLOv3做得更好。YOLOv4使用了一系列新的数据增强技术,如CutMix、Mosaic等,可以帮助模型更好地学习不同角度、不同大小、不同位置的目标,从而提高模型的鲁棒性和泛化能力。而YOLOv3则使用了一些基本的数据增强技术,如随机裁剪、随机翻转等。
2.1 CutMix

两张图片,随机裁剪其中一张图片,粘贴到另一张图片中。
2.2 Mosaic

Mosaic数据增强方法采用随机缩放、随机裁剪、随机排列的方式拼接,形成一张新的图片作为训练数据。这种增强方法可以提高模型的泛化能力,增强模型对于多样化背景、物体大小、旋转角度等情况的识别能力。
3. 激活函数
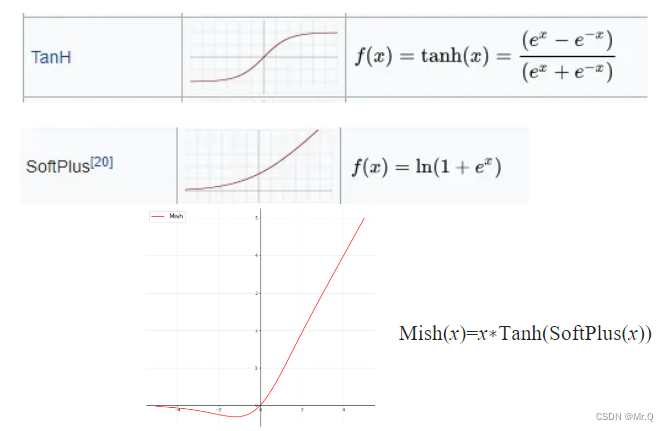
非单调的Mish激活函数是在单调递增的softplus激活函数基础上,再外包了一个单调递增的tanh激活函数。如下所示。
4. 损失函数
yolov4使用的是CIoU-loss,yolov3
Smoothing
5. 正则化方法
DropBlock.
待续。。。
知识点
参数量计算公式:
其中括号内是一个卷积核的参数量,+1是bias,是卷积核个数。
计算量计算公式:
中括号内是计算出feature map中一个点所需要的计算量,一次卷积的计算量。其中第一个小括号是乘法计算量,第二个括号是加法计算量,-1是因为加法是逐个往第一个数累加的原因,+1是bias。有C_o x W x H个输出点。
参考:
深入浅出Yolo系列之Yolov3&Yolov4&Yolov5&Yolox核心基础知识完整讲解 - 知乎YOLOv4特征提取网络——CSPDarkNet结构解析及PyTorch实现 - 知乎深入浅出Yolo系列之Yolov3&Yolov4&Yolov5&Yolox核心基础知识完整讲解 - 知乎
目标检测 - Neck的设计 PAN(Path Aggregation Network)_西西弗Sisyphus的博客-CSDN博客_pan 目标检测