CSAPP第五章 面向编译器的优化(2)

回顾

先复习一下之前的东西。
练习5.7

我们可以看到,相比combine4生成的基于指针的代码,GCC使用了C代码中数组引
用的更加直接的转换。循环索引i在寄存器rdx中,data的地址在寄存器rax中。和
前面一样,累积值acc在向量寄存器xmm0中。循环展开会导致两条vmulsd指令———
条将data[i]加到acc上,第二条将data[i+1]加到acc上。图5-18给出了这段代码的
图形化表示。每条vmulsd指令被翻译成两个操作:一个操作是从内存中加载一个数组元
素,另一个是把这个值乘以已有的累积值。这里我们看到,循环的每次执行中,对寄存
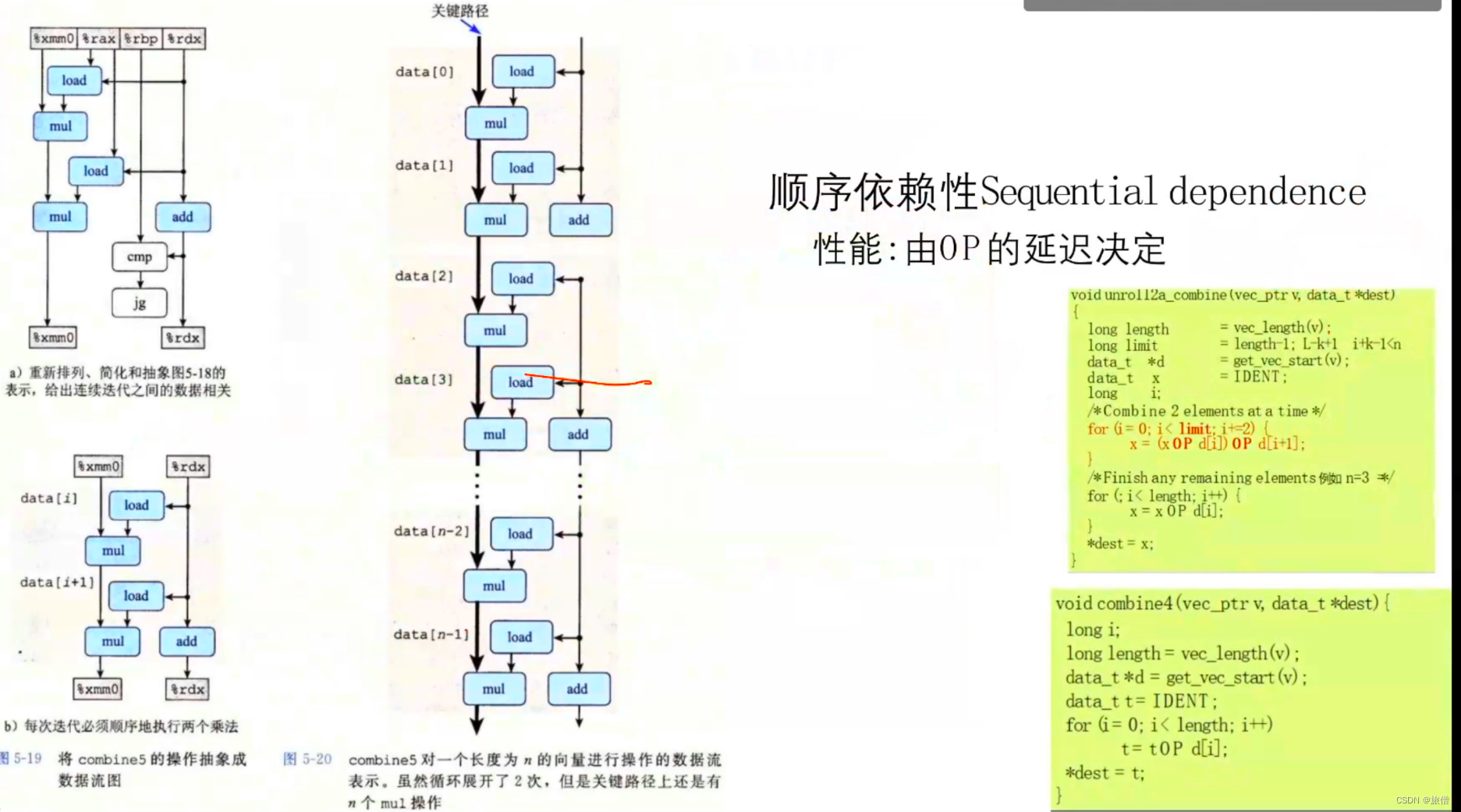
器xmm0读和写两次。可以重新排列、简化和抽象这张图,按照图5-19a所示的过程得到
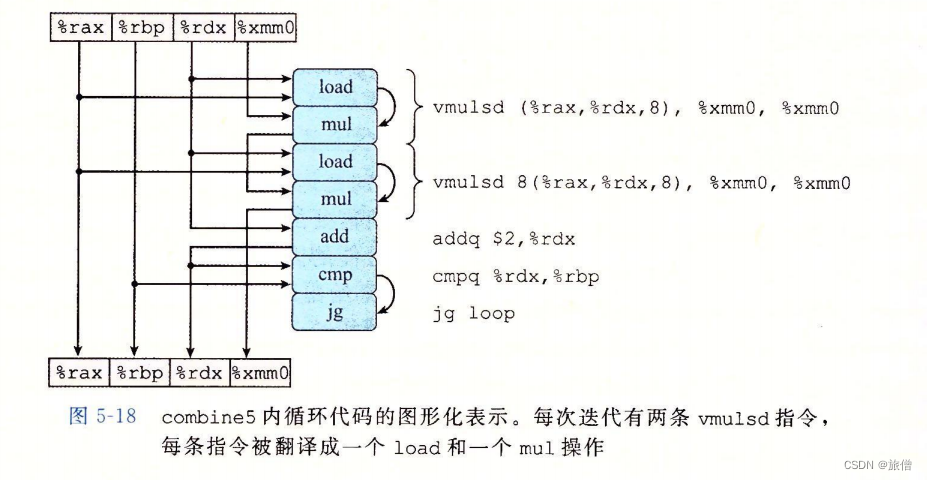
图5-19b所示的模板。然后,把这个模板复制n/2次,给出一个长度为n的向量的计算,
得到如图5-20所示的数据流表示。在此我们看到,这张图中关键路径还是n个mul操
作——迭代次数减半了,但是每次迭代中还是有两个顺序的乘法操作。这个关键路径是循
环没有展开代码的性能制约因素,而它仍然是k×1循环展开代码的性能制约因素。

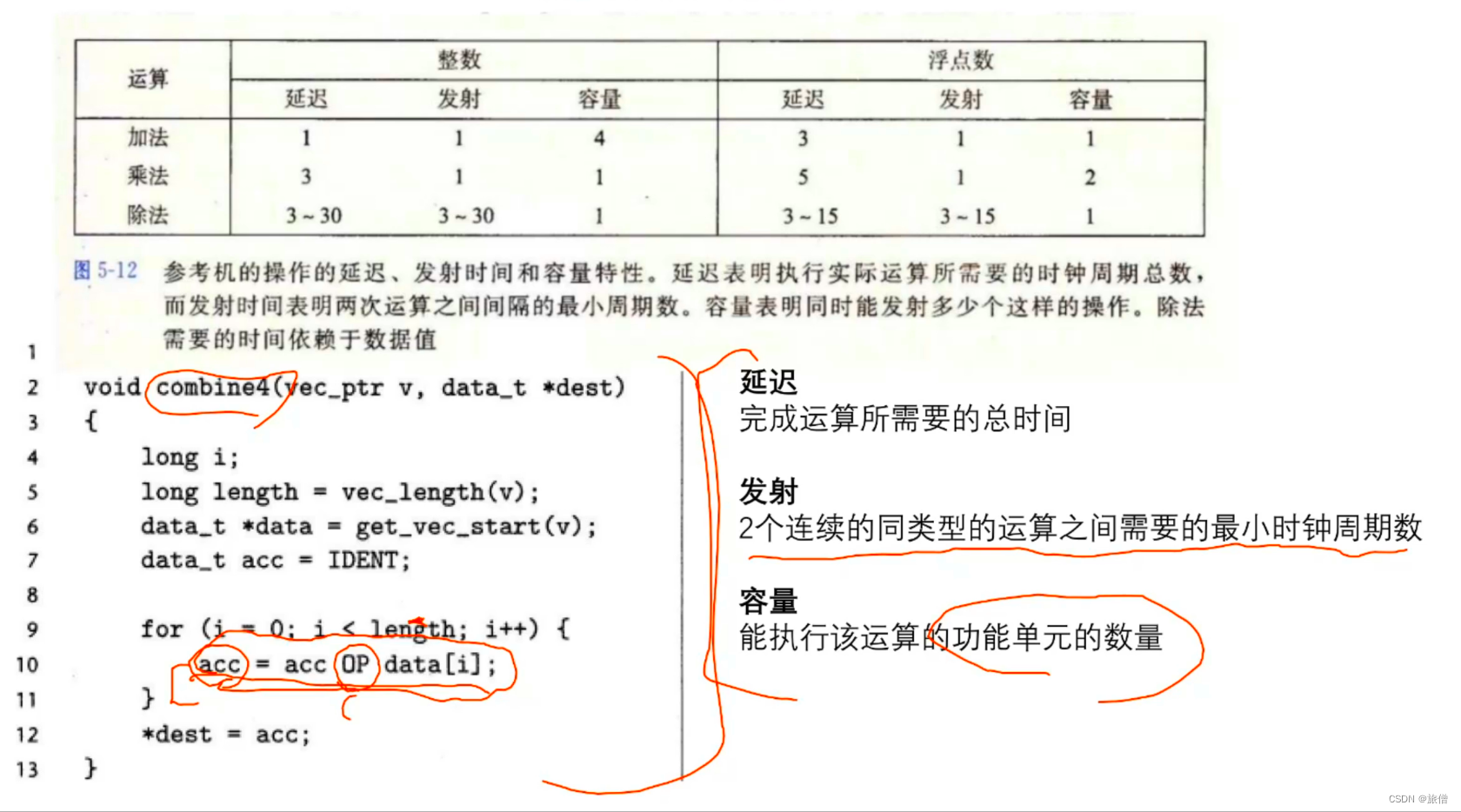
前面我们说到,可以把值存放在临时变量中,执行完之后再写入会内存,或者是利用代码移动减少函数的引用
优化程序性能
循环展开

每次循环进行两个OP,
 有数据依赖
有数据依赖
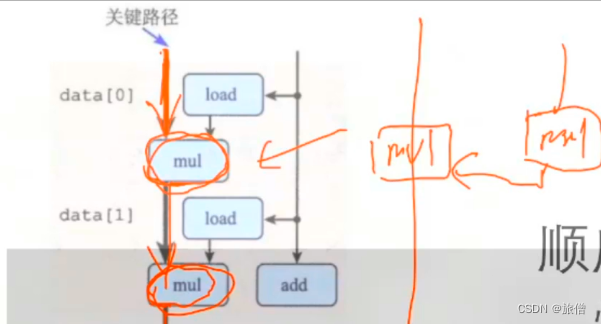
那么我能能否 将乘法并行的计算,减少数据依赖性。
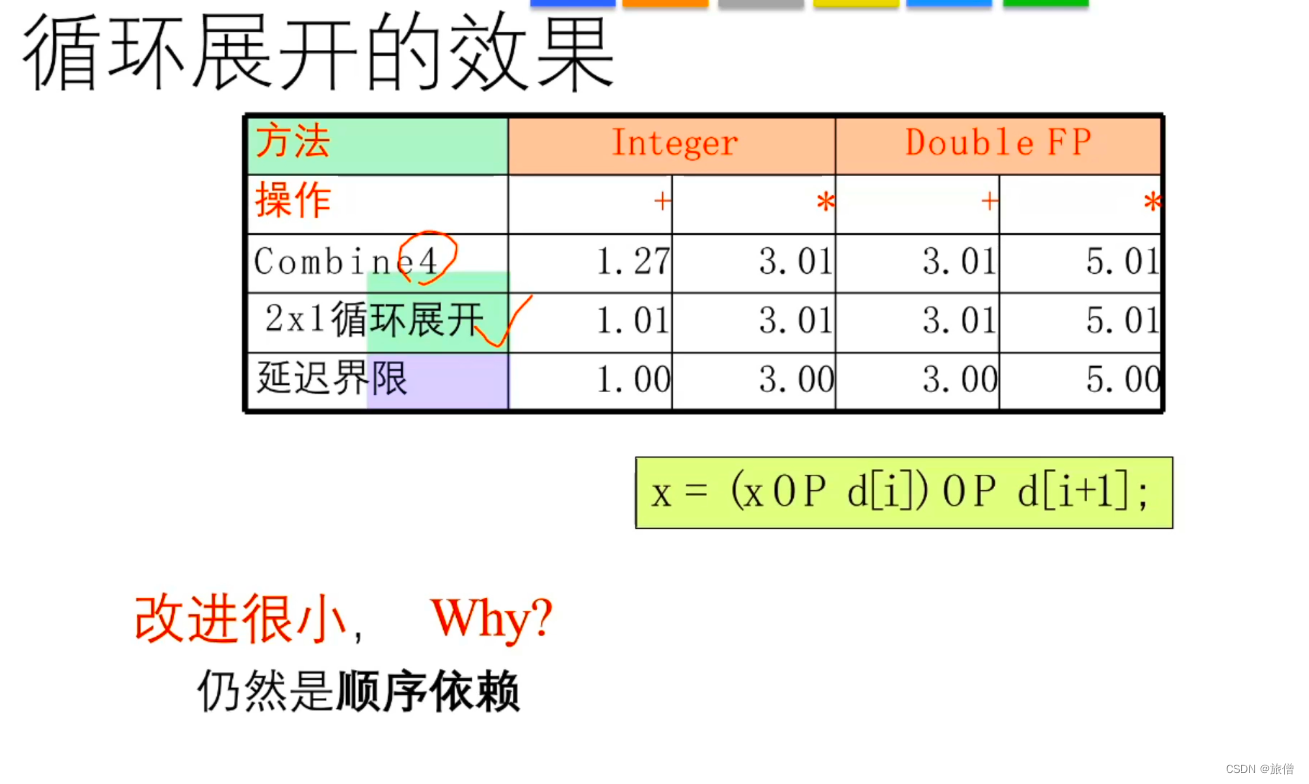
改进循环展开

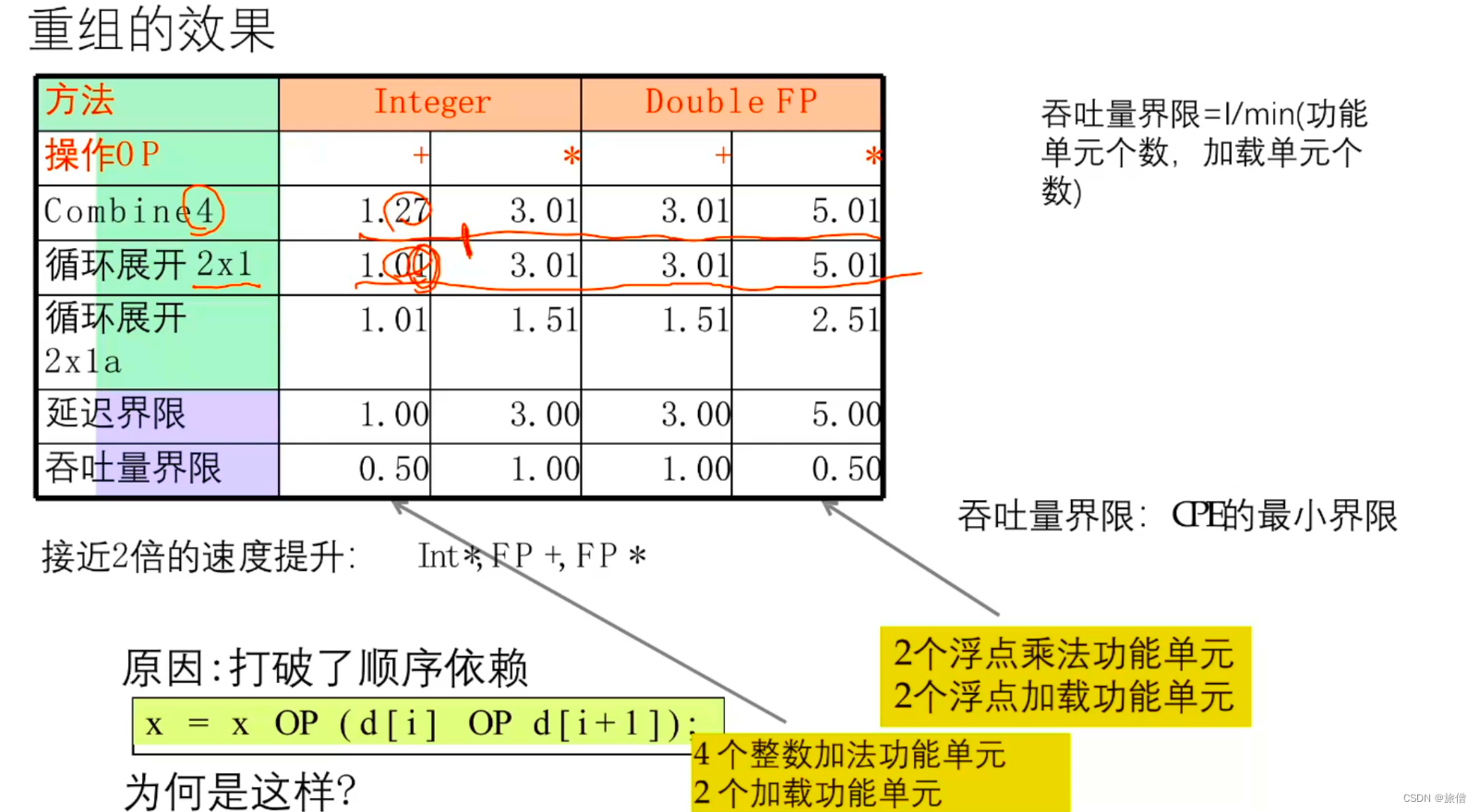
通过测试数据不难发现,加法的时间没有明显改善,其他的方法程序性能优化了一倍。已经达到了延迟界限但是没有达到吞吐量界限。
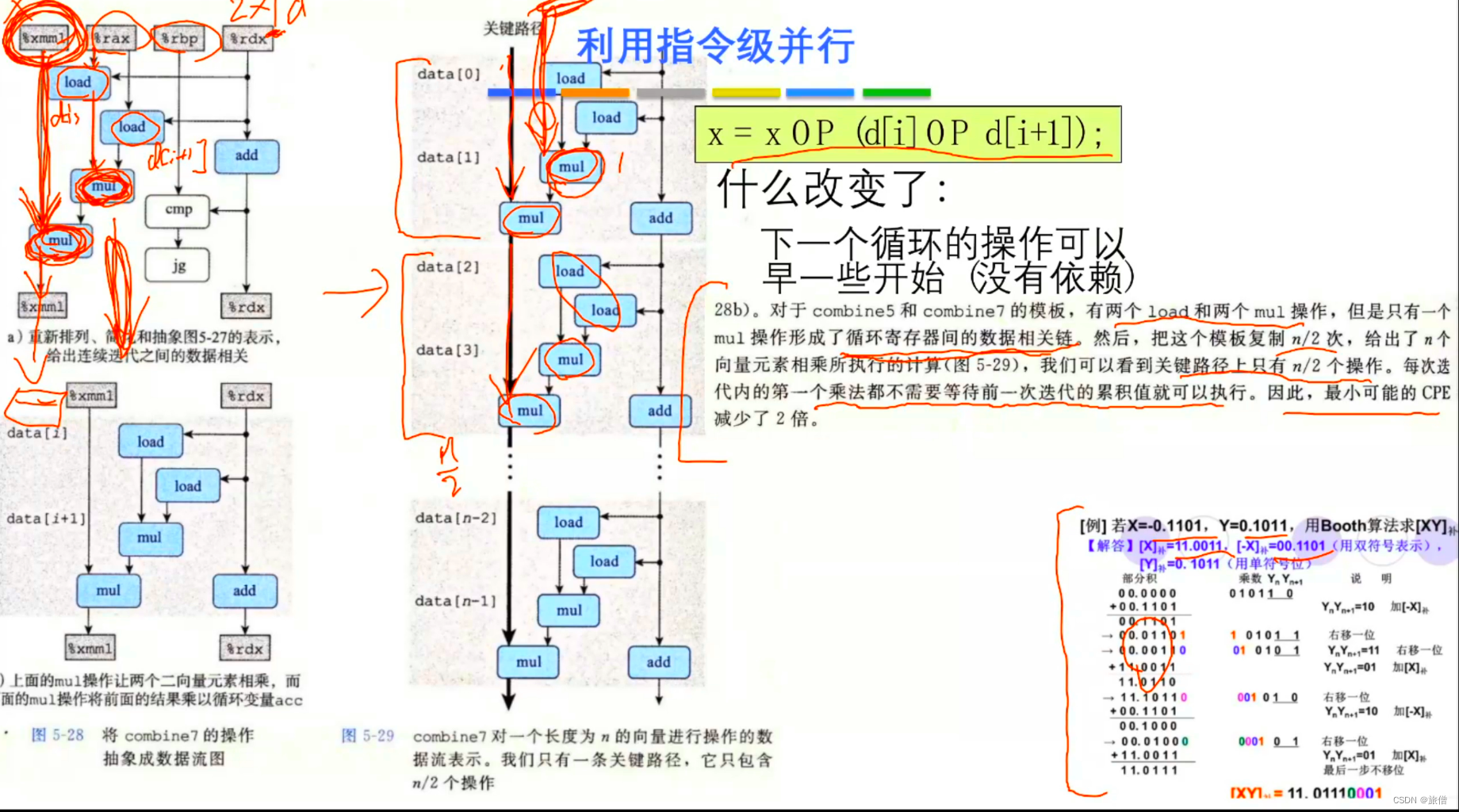
comment: 两个乘法可以在指令之前完成
例题讲解5.8

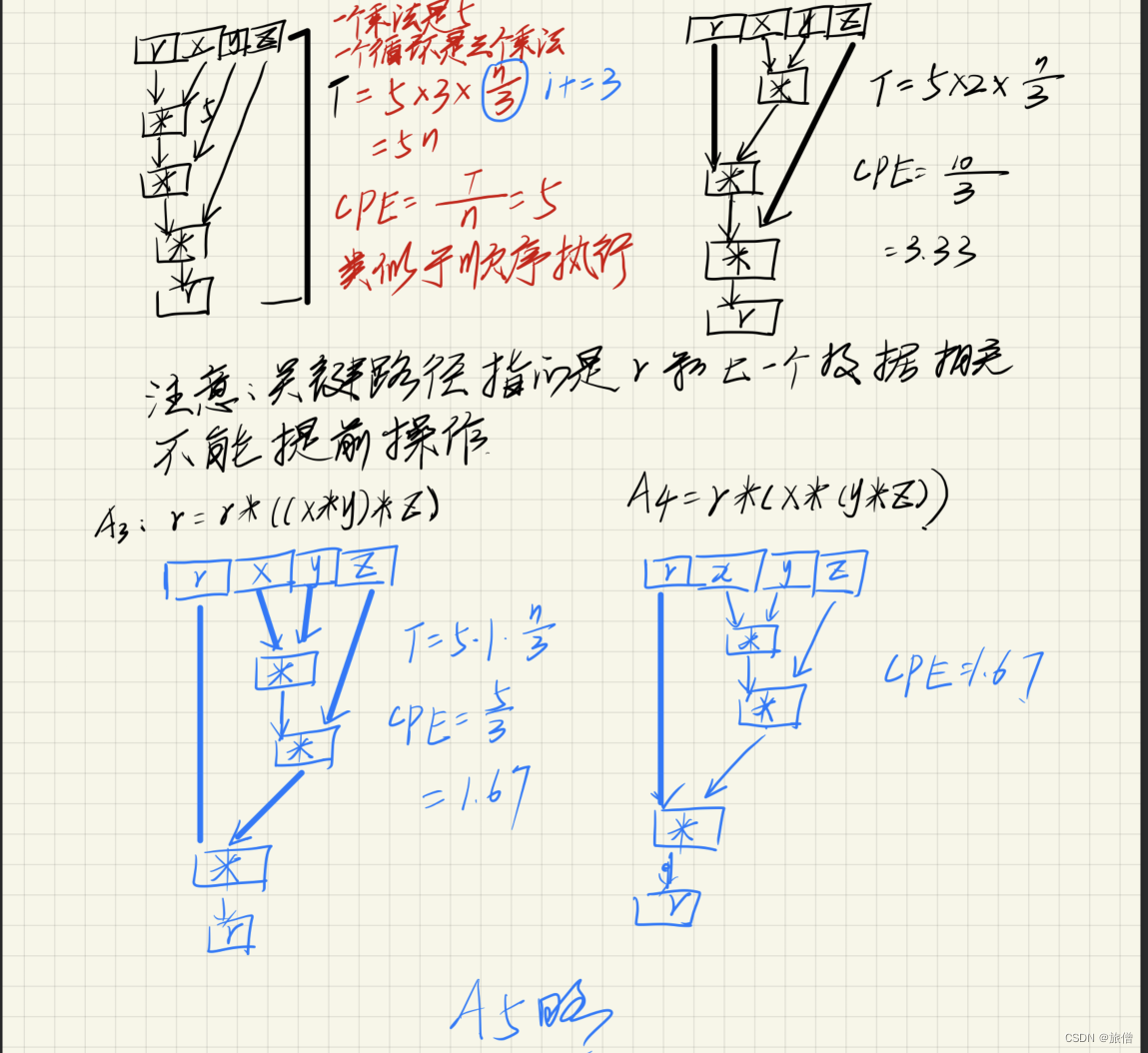
循环展开 使用分离式累加器

注意看红色笔的部分 他使用了两条关键路径。
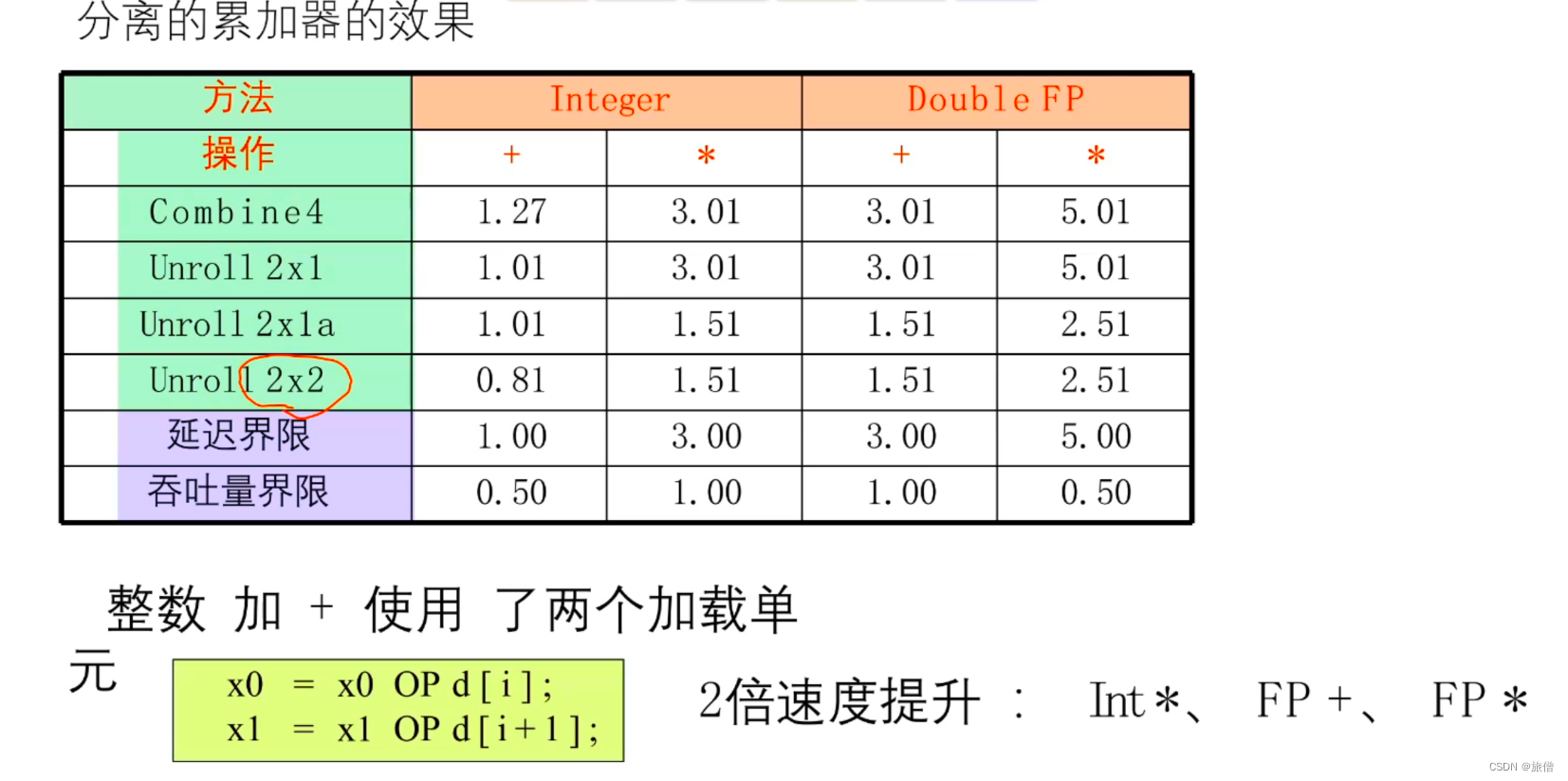 分析结果 :突破了延迟界 接近吞吐量界限
分析结果 :突破了延迟界 接近吞吐量界限
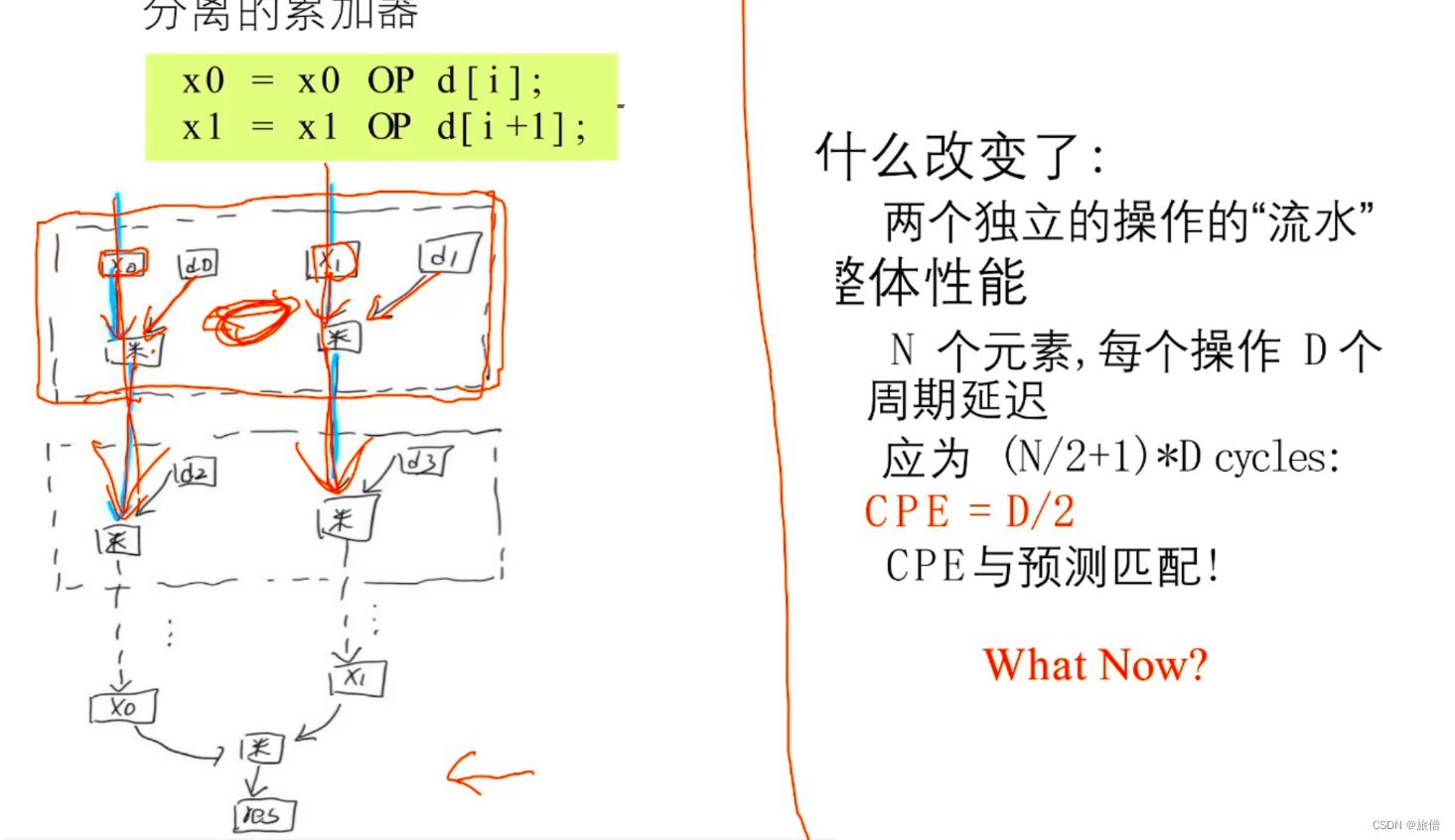
利用指令集并行处理 一个时钟周期处理两个加法 CPE = (N/2+1)*D/N = D/2
结论:我们发现采用k*K分离式加法器有利于提高程序性能。必须符合容量才可以
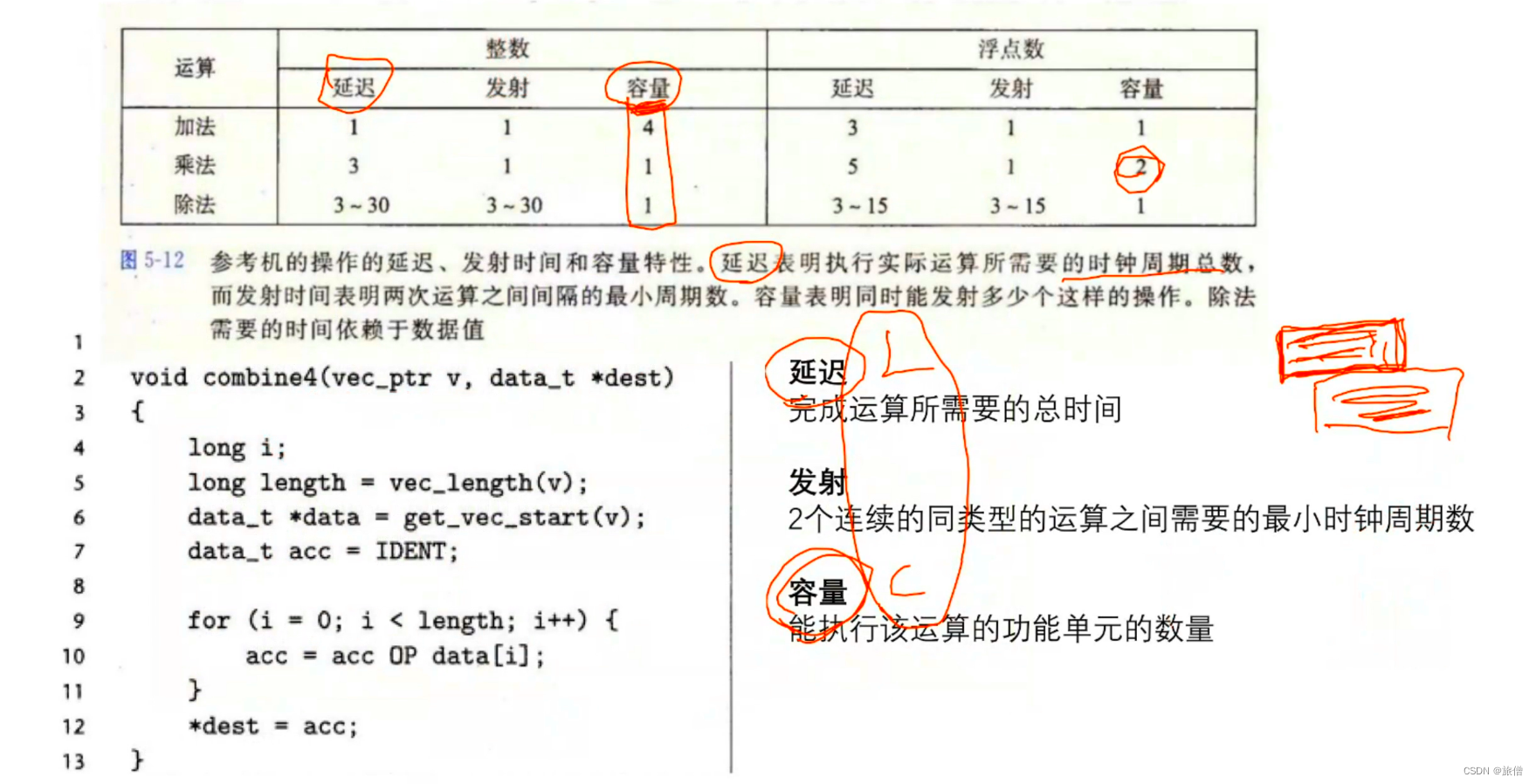

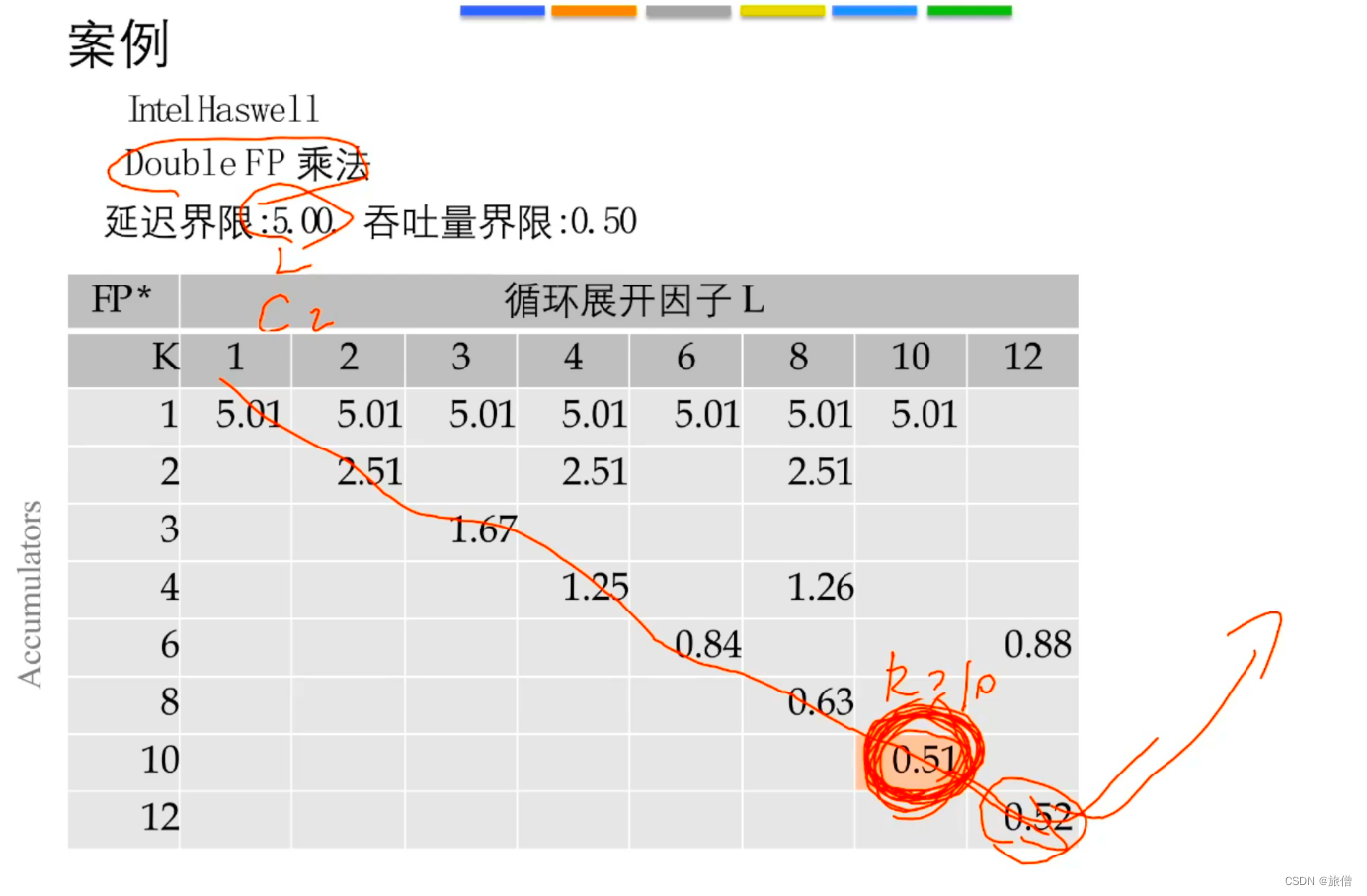
一些问题----寄存器溢出

原因是因为局部变量保存在寄存器中,当CPU所有的寄存器全被用完之后,新的局部变量,就会被存储在内存中。
今天的CSAPP就写道这里 明天继续