数据保管库的数据质量错误

数据保管库的数据质量错误
在过去的几年里,数据仓库发生了巨大的变化,但这并不意味着支撑健全数据架构的基本原理需要被抛在窗外。事实上,随着GDPR等数据法规的日益严格以及对优化技术成本的重新重视,我们现在看到了“Data Vault 2.0”数据建模的复兴。
虽然数据保险库有很多好处,但它是一种复杂而复杂的方法,可能会给数据质量带来挑战。在本文中,我们将深入探讨数据保管库架构、挑战和保持数据质量的最佳实践;以及数据可观测性如何提供帮助。
什么是数据保管库模型?
对于那些不熟悉的人来说,数据保险库是由Dan Linstedt(您可能熟悉Kimball或Imon模型)创建的数据仓库建模方法,创建于2000年,并于2013年更新。数据保管库收集和组织原始数据作为底层结构,以充当馈送 Kimball 或 Inmon 维度模型的源。
数据保险库范例解决了在半永久性原始数据存储之上叠加组织的愿望。数据保管库模型有三个组件:
- 附属表:包含与特定业务概念相关的信息。
- 中心表:通过标准键关系、组合键或包含哈希的更具安全意识的方法将附属表链接在一起。
- 链接表:通过键(或等效项)将不同的中心表映射在一起。
数据保险库的优势
与其他方法(或根本不建模!)相比,数据保险库建模具有许多优势,例如它适用于审计、快速重新定义关系以及轻松添加新数据集。Pie Insurance 是一家领先的小型企业保险科技公司,利用数据保险库 2.0 架构(有一些细微的偏差)来实现其围绕可扩展性和元数据使用的数据集成目标。
“数据保险库数据模型旨在成为组织业务模型的物理实现,因此它成为从多个来源插入数据的标准位置。例如,当新数据添加到我们的数据仓库时,我们可以通过添加卫星表将数据插入到我们的模型中。或者,随着新的主题领域进入范围,我们可以根据我们的业务模型添加新的集线器和链接表,“Pie数据架构数据工程师Ken Wood说。
Pie从其数据保险库实施中获得的其他优势包括:
- 组织 – Pie 可以快速找到他们需要的数据,因为它是按照其业务模型组织的。
- 基础 – 数据保管库提供了一个坚实的基础,允许快速“快速获得见解”。当出现新问题时,他们可以在数据保管库表的下游构建维度表,甚至可以虚拟化下游内容(视图)。
- 历史记录 – 卫星表的设计允许 Pie 搜索和查询随时间推移的数据更改,本质上是提供缓慢更改维度和数据的事实历史记录视图所需的数据。
如何实现数据保管库架构?
虽然部署会有所不同,但 Pie 的数据保险库架构实施包括构成其数据管道生态系统的四个数据架构概念层:
- 摄取层 – 从源系统登陆和暂存原始数据。
- 登陆 – 源文件登陆 AWS S3 存储桶
- 暂存 – 原始源数据存储在雪花表内的 VARIANT 列中。
- 策展层 – 组织原始数据。
- 原始数据保管库 – 在 Snowflake 环境中,并按照数据保管库 2.0 方法的建议将其映射到中心、卫星和链接表进行小转换。
- 业务数据模型 – Pie的数据保险库设计是其业务数据模型的物理模型 - 而不是尝试基于每个源系统的数据进行设计。这为他们提供了一个单一的模型,无论来源如何。
- 转换层 – 使用业务逻辑转换和清理数据。
- 业务保管库 – 遵循业务转换规则的预转换数据。
- 信息仓库 – 仅此层遵循维度(或金博尔)星形(或雪花)数据模型。
- 表示层–绝大多数用户的报告层。此图层具有最少的变换规则。
- BI/报告工具 – Pie使用Looker,它有一个反映“信息仓库”(转换后的数据)的元数据层。
- 未来报告工具插件 – 这允许在不进行重大开发的情况下添加未来的报告或查询工具,因为数据已经在数据库层中转换。
- 动态规则 – 需要根据自助服务用户需要查看其信息的不同粒度或聚合视图进行更改的动态规则或计算。
“我们从左到右思考我们的架构。最左边是最原始形式的数据,最右边是已经完全转换、清理并准备供业务使用的信息,“Ken 说。
数据保管库的数据质量错误
数据保管库体系结构有很多好处,但与其他方法相比,它确实会创建更多具有更复杂的转换以及上游和下游资产之间关系的表。如果解决不当,这可能会带来数据质量挑战。
一些挑战可能包括:
- 代码维护: 集线器、卫星表和链接表的 ETL 代码必须遵循与常见列值定义(如业务和哈希键定义)相同的规则,以使它们能够独立加载。因此,对代码的任何更改可能必须在多个位置完成,以确保一致性。
- 层之间的多个复杂转换: 转换是使用任何方法的任何数据工程管道中的必要步骤,但它们可能会创建数据质量事件。当转换代码被修改(可能不正确)或输入数据与转换模型的基本预期不一致(可能是意外的架构更改或数据未按时到达)时,可能会发生这种情况。数据保管库体系结构中多个层的长转换代码块可能会加剧这些错误,并使根本原因分析更加困难。此处的最佳做法是使转换尽可能简单。
- 维护集线器、链路和附属表的完整性: 数据保管库中心、链接和附属表中的任何负载(或其他错误)都会损坏下游查询,输出显示部分数据或缺失数据。在这种情况下,最好的做法是建立自动验证检查或数据可观察性,以便在这些异常发生时检测它们。
- 了解依赖关系: 映射数据保管库体系结构中的所有依赖项可能具有挑战性,尤其是在多个层之间。在这种情况下,最好的做法是建立可观测性和监控,以便在出现问题时及时发现。
代码维护
集线器、卫星表和链接表的 ETL 代码必须遵循与常见列值定义(如业务和哈希键定义)相同的规则,以使它们能够独立加载。因此,对代码的任何更改可能必须在多个位置完成,以确保一致性。
一个提示?“我们的代码生成是元数据驱动的,因此当我们在一个地方更改元数据时,它会在使用该特定元数据的任何地方重新生成 ETL 代码,”Ken 说。
层之间的多个复杂转换
转换是使用任何方法的任何数据工程管道中的必要步骤,但它们可能会创建数据质量事件。当转换代码被修改(可能不正确)或输入数据与转换模型的基本预期不一致(可能是意外的架构更改或数据未按时到达)时,可能会发生这种情况。
数据保管库体系结构中多个层的长转换代码块可能会加剧这些错误,并使根本原因分析更加困难。此处的最佳做法是使转换尽可能简单。
“我们正在努力改进我们的设计,以便在数据管道中的一个位置(信息仓库)应用复杂的转换,”Ken 说。“随着原始数据保管库的扩展,转换逻辑变得更加复杂,因此我们正在设计降低复杂性的方法。
维护集线器、链路和附属表的完整性
数据保管库中心、链接和附属表中的任何负载(或其他错误)都会损坏下游查询,输出显示部分数据或缺失数据。
“关键是要有自动验证检查或数据可观察性,以便在这些异常发生时检测它们,”Ken说。
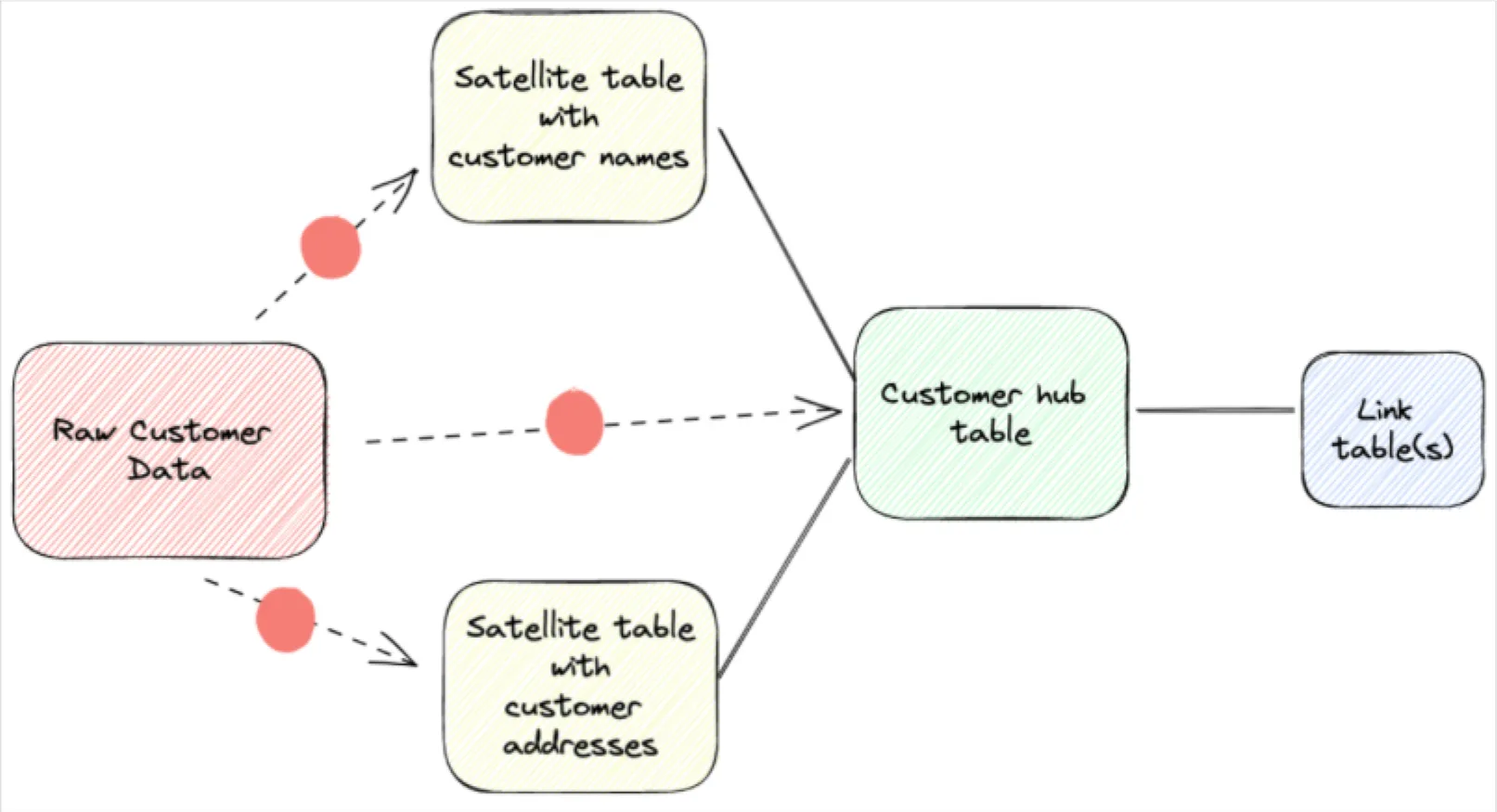
在此数据保管库图中,红点表示转换可能引入数据质量问题的位置。
了解依赖关系
映射数据保管库体系结构中的所有依赖项可能具有挑战性,尤其是在不了解源数据以将其映射到目标 Hub、Satellite 和 Link 表时,或者源系统具有目标模型中没有的其他意外业务键时。
“我们通过使用多活动卫星表来处理这个问题。这些为卫星表增加了一个键以匹配谷物,“Ken 说。或者,我们在引入新键时添加集线器和链接表,这与我们的业务模型一致。
扩展测试
跨数据仓库进行数据测试已经是一个令人头疼的问题,但对于数据保管库,这尤其困难。
这是因为没有人可以预测和编写针对数据中断的所有方式的测试,即使可以,也几乎不可能跨环境中的所有表和管道进行扩展。
在数据保险库架构方面尤其如此,因为需要覆盖 3 倍的表面积,并且多层和转换增加了更多未知的数据质量问题。
使用 ML 数据异常检测器提高数据保管库的可靠性
使用 ML 数据异常检测(在内部构建或在数据可观测性解决方案中构建)可以解决几个关键领域的数据保管库数据质量挑战:
- Data Vault 架构的标志之一是它“100% 的时间收集 100% 的数据”,这可能会使回填原始保管库中的错误数据变得很痛苦。机器学习异常检测器可缩短检测时间,使数据团队能够关闭损坏管道的龙头,并阻止不良数据流流入原始保管库,从而减轻数据回填负担。
- 从原始数据登陆区域到报告表,ML 数据异常情况检测可以确保数字范围和值类型符合预期。
- 监视跨层移动数据的转换查询,以确保它们在预期时间以预期的负载量运行,以行或字节定义。自动数据沿袭将使Pie(和其他使用数据保险库的组织)能够大大加快其根本原因分析。
- 随着数据保管库体系结构创建的表和列引用越来越多,监视架构更改(例如表或列名称更改)的需求也随之增加。
最终数据保管库建议
遵循数据保险库领域领导者的建议,如Pie,是一个很好的下一步。对于Ken来说,成功归结为与业务和商业模式的不断协调。
“避免仅对数据保险库表进行建模以轻松适应来自源系统的数据的诱惑 - 除非该源系统的数据模型是基于您企业的数据模型构建的,”他建议道。
您的团队已投入大量时间和专业知识来开发和维护数据保管库体系结构。确保每一步的数据信任将证明您辛苦赚来的劳动成果是合理的。