whisper技术导读2

1、数据处理
根据最近利用互联网上的网络规模文本来训练机器学习系统的趋势,我们采用了一种极简的方法来进行数据预处理。与语音识别方面的许多工作相比,我们训练Whisper模型在没有任何显著标准化的情况下预测转录本的原始文本,依靠序列到序列模型的表现力来学习映射话语及其转录形式。
这导致了一个非常多样化的数据集,涵盖了来自许多不同环境、录音设置、说话者和语言的广泛音频分布。虽然音频质量的多样性有助于训练模型的鲁棒性,但转录质量(该音频所以对应的文本具备多种text表达)的多样性并不是同样有益的。初步检查显示原始数据集中有大量不合格的转录本。为了解决这个问题,我们开发了几种自动过滤方法来提高成绩单质量。互联网上的很多转录并不是人生成的,而是ASR自动生成的。最近的研究表明,在混合人工和机器生成的数据集上进行训练会严重损害翻译系统的性能。许多现有的ASR系统只输出有限的书面语言子集,这些子集删除或标准化了仅从音频信号中难以预测的方面,如复杂的标点符号(感叹号、逗号和问号)、格式空白(如段落)或风格方面(如大写字母)。虽然许多ASR系统包括某种程度的反向文本规范化,但它通常是简单的或基于规则的,并且仍然可以从其他未处理的方面(例如从不包含逗号)检测到。我们还使用了一个音频语言检测器,该检测器是通过微调在VoxLingua107上的数据集的原型版本上训练的原型模型(Valk & Aluma e, 2021)来创建的,以确保口语与CLD2中记录的语言相匹配。我们将音频文件分成30秒的片段,并与那段时间内出现的文本子集配对。
2、模型
由于我们的工作重点是研究语音识别的大规模监督预训练的能力,我们使用现成的架构来避免将我们的发现与模型改进相混淆。我们选择了一个编码器-解码器转换器(Vaswani等人,2017),因为该架构已经过很好的验证,可以可靠地扩展。所有的音频被重新采样到16000赫兹,一个80通道对数量级梅尔谱图表示是计算在25毫秒的窗口与10毫秒的跨步。对于特征归一化,我们将输入全局缩放到-1到1之间,在预训练数据集中近似为零均值。用与GPT- 2中相同的字节级BPE文本标记器(Sennrich等人,2015;Radford et al., 2019),并为多语言模型修改词汇表(但保持相同的大小),以避免在其他语言上过度碎片化,因为GPT-2 BPE词汇表仅为英语。
3、多任务模式
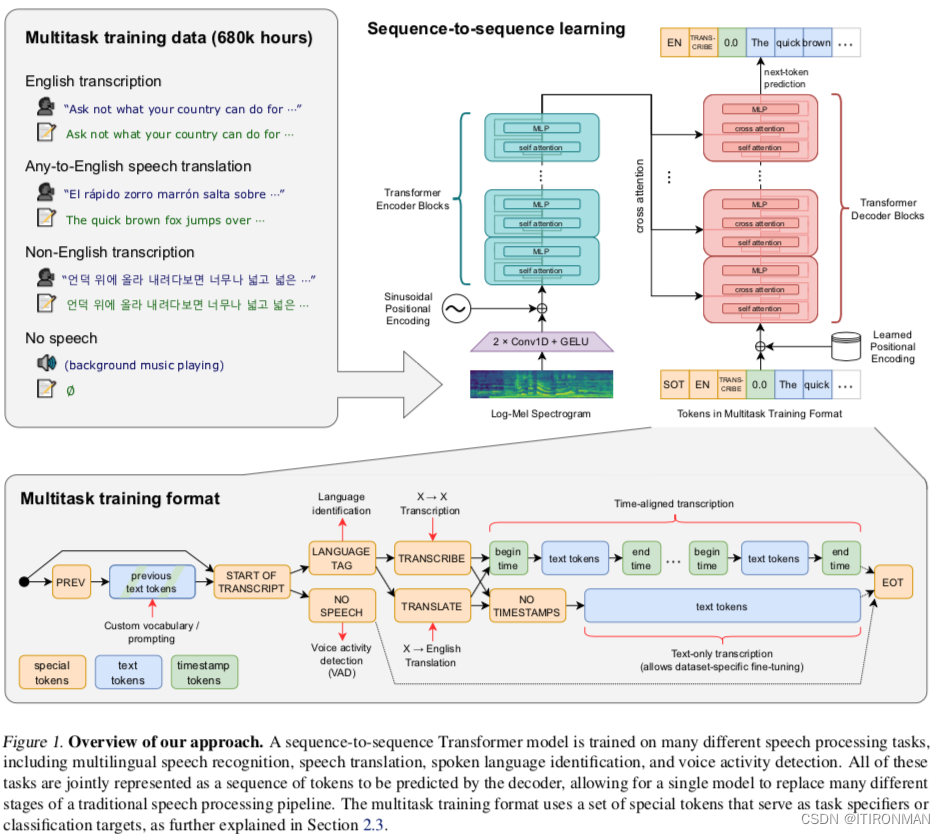
尽管预测给定音频片段中的单词是完整语音识别问题的核心部分,并且在研究中得到了广泛的研究,但它并不是唯一的部分。一个功能齐全的语音识别系统可能涉及许多额外的组件,如语音活动检测、说话人拨号和反向文本规范化。这些组件通常是单独处理的,导致围绕核心语音识别模型的相对复杂的系统。为了降低这种复杂性,我们希望有一个单一的模型来执行整个语音处理管道,而不仅仅是核心识别部分。
这里需要考虑的一个重要问题是模型的接口。在相同的输入音频信号上可以执行许多不同的任务:转录、翻译、语音活动检测、对齐和语言识别是一些例子。体地说,我们以一定的概率将当前音频片段之前的文本添加到解码器的上下文中。对于时间戳预测,我们预测相对于当前音频片段的时间,将所有时间量化到最接近的20毫秒,这与Whisper模型的原生时间分辨率相匹配,并为每个时间段添加额外的标记到我们的词汇表中。我们将它们的预测与标题标记穿插在一起:在每个标题文本之前预测开始时间标记,然后预测结束时间标记。
4、训练细节
为了研究Whisper的缩放特性,我们训练了一套不同大小的模型。在早期的开发和评估中,我们观察到Whisper模型倾向于转录对说话者姓名的合理但几乎总是错误的猜测。
5、实验
Whisper的目标是开发一个单一的健壮的语音处理系统,它可以可靠地工作,而不需要对数据集进行特定的微调,从而在特定的分布上获得高质量的结果。为了研究这种能力,我们重用了一组广泛的现有语音处理数据集来检查Whisper是否能够很好地跨领域、任务和语言进行泛化。我们没有使用这些数据集的标准评估协议,其中包括训练和测试分割,而是在零射击设置中评估Whisper,而不使用每个数据集的任何训练数据,因此我们测量的是广泛的泛化。
6、评估指标
语音识别研究通常基于单词错误率(WER)度量来评估和比较系统。然而,基于字符串编辑距离的WER会将模型输出和参考文本之间的所有差异(包括脚本风格上的无害差异)。因此,输出被人类判断为正确的转录本的系统仍然可能由于轻微的格式差异而具有较大的WER。虽然这对所有转录器来说都是一个问题,但对于像Whisper这样的零射击模型来说尤其严重,因为它没有观察到任何特定数据集转录格式的例子。
这并不是一个新发现;开发与人类判断更好相关的评估指标是一个活跃的研究领域,虽然有一些很有前途的方法,但还没有一个被广泛应用于语音识别。
耳语模型是在广泛而多样的音频分布上进行训练的,并在零射击环境下进行评估,它可能比现有的系统更能匹配人类的行为。为了研究情况是否如此(或者机器和人类表现之间的差异是否是由于尚未被理解的因素),我们可以将Whisper模型与人类表现和标准微调机器学习模型进行比较,并检查它们更接近匹配。在我们的分析中,我们使用librisspeech作为参考数据集,因为它在现代语音识别研究中的核心作用,以及许多在其上训练的发布模型的可用性,这允许表征鲁棒性行为。我们使用另外12个学术语音识别数据集来研究分布外行为。虽然最好的zero-shot的whisper模型的librisspeech清洁测试的WER相对不显著,为2.5,这大致相当于现代监督基线或2019年中期的最先进水平,但它与监督librisspeech模型具有非常不同的鲁棒性,并且在其他数据集上表现优于所有基准的Lib- riSpeech模型,因为预训练无监督所以他和wav2vec去对比是最合适的。
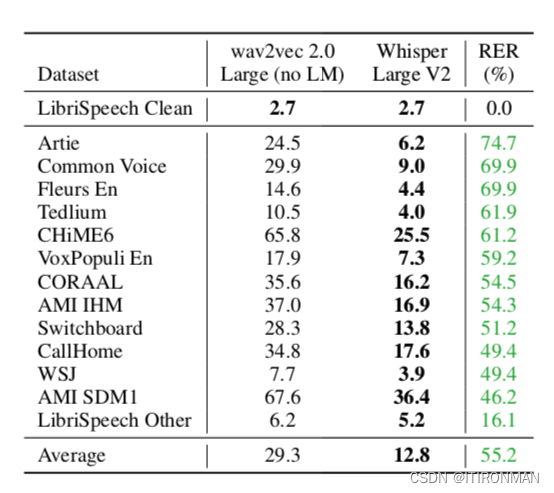
这一发现建议强调对模型的零概率和非分布评估,特别是在与人类表现进行比较时,以避免由于误导性比较而夸大机器学习系统的能力。
后面还有多语言模型、翻译等等,与技术相关弱,多于测评相关,就不细讲了。