如何使用YOLOv5的pycocotools进行coco指标评估

使用YOLOv5进行coco指标评估
- 1. 安装pycocotools
- 2.重新排序并命名
- 3. 将txt标签转换为json格式格式
- 2. 生成json
- 3. 测试是否正确
- 4. 运行val.py
- 完整版本(一次运行所有)
1. 安装pycocotools
pip install pycocotools -i https:pypi.douban.com/simple
2.重新排序并命名
在转换之前,如果有图片和txt名字不符合要求,运行文件会报错,因此需要将文件进行重新排序,代码如下:
- 可以将文件重新排序并进行重命名
- 可以将没有标签的文件进行删除
#第一天学习
#第一天学习
#对文件名重新顺序命名
import osimgpath = r'F:\\sjh\\code\\my\\datasets\\VOC_five\\images/'
labelpath = r'F:\\sjh\\code\\my\\datasets\\VOC_five\\labels/'imglist = os.listdir(imgpath)
labellist = os.listdir(labelpath)
imgn = 00000
laben = 00000# imglist.sort(key=lambda x: int(x[:-4])) #对‘.’进行切片,并取列表的第一个值(左边的文件名)转化整数型# print(sorted(labellist))
for imaname in imglist:img_id = '%05d' %imgnimgname = imaname.strip('.jpg')oriimg= imgpath + imgname + '.jpg'newimname = str(img_id) + '.jpg'newimg = imgpath +newimname# print(oriimg,newimg)orilabel = labelpath + imgname + '.txt'newtxtname = str(img_id) + '.txt'newlabel = labelpath + newtxtname# print(orilabel,newlabel)imgn += 1if not os.path.exists(oriimg) or not os.path.exists(orilabel):print("no exists img",oriimg,orilabel)continueelif oriimg == newimg:print("Has been renamed:",oriimg,newimg)continueimg_size = os.path.getsize(oriimg)label_size = os.path.getsize(orilabel)if img_size == 0 or label_size ==0:print('文件是空的')print(orilabel,'文件已删除')os.remove(orilabel)os.remove(oriimg)continue# print(newimg,newlabel)# os.rename(oriimg, newimg)# os.rename(orilabel, newlabel)
3. 将txt标签转换为json格式格式
之后将YOLO的txt文件生成需要使用的txt文件
import os
import cv2
'''
function:可将yolo格式的数据集转换为coco格式的(1), 生成annos.txt需要准备:
labels:yolo格式的标签,是txt格式,名字为图片名
images:原始标签对应的图片,需要有序号
'''# 原始标签路径E:\\pyCharmProject\\AI\\papercode\\datasets\\GTSDB
originLabelsDir = r'F:\\sjh\\code\\my\\datasets\\VOC_five\\labels'
# 转换后的文件保存路径
saveDir = r'F:\\sjh\\code\\my\\datasets\\VOC_five/annos1.txt'
# 原始标签对应的图片路径
originImagesDir = r'F:\\sjh\\code\\my\\datasets\\VOC_five\\images'txtFileList = os.listdir(originLabelsDir)
with open(saveDir, 'w') as fw:for txtFile in txtFileList:with open(os.path.join(originLabelsDir, txtFile), 'r') as fr:labelList = fr.readlines()for label in labelList:label = label.strip().split()x = float(label[1])y = float(label[2])w = float(label[3])h = float(label[4])# convert x,y,w,h to x1,y1,x2,y2imagePath = os.path.join(originImagesDir,txtFile.replace('txt', 'jpg'))print(imagePath)image = cv2.imread(imagePath)print(image.shape)H, W, _ = image.shapex1 = (x - w / 2) * Wy1 = (y - h / 2) * Hx2 = (x + w / 2) * Wy2 = (y + h / 2) * H# 为了与coco标签方式对,标签序号从1开始计算fw.write(txtFile.replace('txt', 'jpg') + ' {} {} {} {} {}\\n'.format(int(label[0]), x1, y1, x2, y2))print('{} done'.format(txtFile))生成以下形式
2. 生成json
# -*- coding: utf-8 -*-
# @Time : 2022/9/5
# @Author : rickHan
# @Software: PyCharm
# @File : yolo2coco2.py
import json
import os
import cv2#-------------------可用-----------------------------------
'''
function:可将yolo格式的数据集转换为coco格式的(2)
需要准备:
classes.txt:一行就是一个类,不需要数字,只要类名称
annos.txt:由上一个.py文件生成
images:与annos.txt对应的图片,需要有序号生成.json文件,在annotations文件下
'''# ------------用os提取images文件夹中的图片名称,并且将BBox都读进去------------
# 根路径,里面包含images(图片文件夹),annos.txt(bbox标注),classes.txt(类别标签),
# 以及annotations文件夹(如果没有则会自动创建,用于保存最后的json)
root_path = r'F:\\sjh\\code\\my\\datasets\\VOC_five'
# 用于创建训练集或验证集
phase = 'instances_val2017' # 需要修正,保存后的json文件名# dataset用于保存所有数据的图片信息和标注信息
dataset = {'categories': [], 'annotations': [], 'images': []}# 打开类别标签
with open(os.path.join(root_path, 'classes.txt')) as f:classes = f.read().strip().split()# 建立类别标签和数字id的对应关系
for i, cls in enumerate(classes, 1):dataset['categories'].append({'id': i, 'name': cls, 'supercategory': 'mark'})# 读取images文件夹的图片名称
indexes = os.listdir(root_path+'/images/')# 统计处理图片的数量
global count
count = 0# 读取Bbox信息
with open(root_path+ '/annos1.txt') as tr:annos = tr.readlines()# ---------------接着将,以上数据转换为COCO所需要的格式---------------for k, index in enumerate(indexes):count += 1# 用opencv读取图片,得到图像的宽和高im = cv2.imread(root_path+'/images/' + index)height, width, _ = im.shapeprint(index)# 添加图像的信息到dataset中dataset['images'].append({'file_name': index.replace("\\\\", "/"),'id': int(index[:5]), # 提取文件名 里的数字标号 必须是int类型,不能是str'width': width,'height': height})for ii, anno in enumerate(annos):parts = anno.strip().split()# 如果图像的名称和标记的名称对上,则添加标记if parts[0] == index:# 类别cls_id = parts[1]# x_minx1 = float(parts[2])# y_miny1 = float(parts[3])# x_maxx2 = float(parts[4])# y_maxy2 = float(parts[5])width = max(0, x2 - x1)height = max(0, y2 - y1)dataset['annotations'].append({'area': width * height,'bbox': [x1, y1, width, height],'category_id': int(cls_id),'id': ii,'image_id': int(index[0:5]), # 提取文件名里的数字标号 必须是int类型,不能是str'iscrowd': 0,# mask, 矩形是从左上角点按顺时针的四个顶点'segmentation': [[x1, y1, x2, y1, x2, y2, x1, y2]]})print('{} images handled'.format(count))# 保存结果的文件夹
folder = os.path.join(root_path, './valid/annotations')
if not os.path.exists(folder):os.makedirs(folder)
json_name = os.path.join(root_path, './valid/annotations/{}.json'.format(phase))
with open(json_name, 'w') as f:json.dump(dataset, f, ensure_ascii=False, indent=1)
3. 测试是否正确
# -*- coding: utf-8 -*-
# @Time : 2022/9/5
# @Author : rickHan
# @Software: PyCharm
# @File : drawtest.py
import os
from pycocotools.coco import COCO
from PIL import Image, ImageDraw
import matplotlib.pyplot as plt
'''
function:绘制标注的数据集和对应图片的位置是否正确
绘制前三张,如果yoyo转换标注的json数据集没有问题,则也能在图上画出框'''
json_path = r'F:\\sjh\\code\\my\\datasets\\VOC_five\\valid\\annotations/instances_val2017.json'
# json_path = r'predictions.json'
img_path = r'F:\\sjh\\code\\my\\datasets\\VOC_five\\images' #json对应的图片# load coco data
coco = COCO(annotation_file=json_path)# get all image index info
ids = list(sorted(coco.imgs.keys()))
print("number of images: {}".format(len(ids)))# get all coco class labels
coco_classes = dict([(v["id"], v["name"]) for k, v in coco.cats.items()])# 遍历前三张图像
for img_id in ids[:3]:# 获取对应图像id的所有annotations idx信息ann_ids = coco.getAnnIds(imgIds=img_id)# 根据annotations idx信息获取所有标注信息targets = coco.loadAnns(ann_ids)# get image file namepath = coco.loadImgs(img_id)[0]['file_name']# read imageimg = Image.open(os.path.join(img_path, path)).convert('RGB')draw = ImageDraw.Draw(img)# draw box to imagefor target in targets:x, y, w, h = target["bbox"]x1, y1, x2, y2 = x, y, int(x + w), int(y + h)draw.rectangle((x1, y1, x2, y2))draw.text((x1, y1), coco_classes[target["category_id"]])# show imageplt.imshow(img)plt.show()测试没有问题,就可以使用了
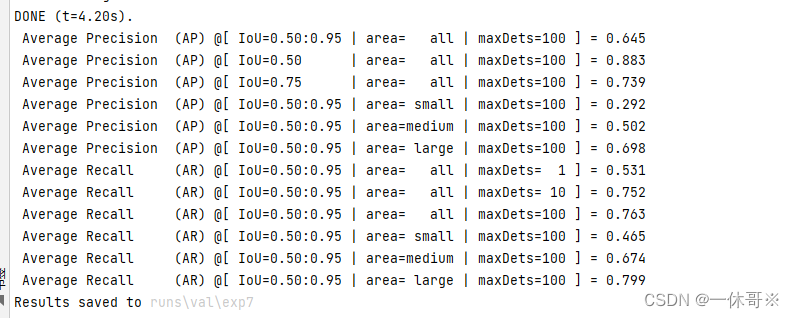
4. 运行val.py
json文件存放位置,放到测试文件总目录下
.\\annotations\\instances_val2017.json
python val.py --save-json
结果
完整版本(一次运行所有)
import os
import cv2
import json
import os
from pycocotools.coco import COCO
from PIL import Image, ImageDraw
import matplotlib.pyplot as plt
'''
first
function:可将yolo格式的数据集转换为coco格式的(1), 生成annos.txt
需要准备:
labels:yolo格式的标签,是txt格式,名字为图片名
images:原始标签对应的图片,需要有序号
'''
root_dir=r'F:\\sjh\\code\\my\\datasets\\VOC_five'
def first_to_annostxt():# 原始标签路径E:\\pyCharmProject\\AI\\papercode\\datasets\\GTSDBoriginLabelsDir = root_dir + '/labels'# 转换后的文件保存路径saveDir = root_dir + '/annos1.txt'# 原始标签对应的图片路径originImagesDir = root_dir + '/images'txtFileList = os.listdir(originLabelsDir)with open(saveDir, 'w') as fw:for txtFile in txtFileList:with open(os.path.join(originLabelsDir, txtFile), 'r') as fr:labelList = fr.readlines()for label in labelList:label = label.strip().split()x = float(label[1])y = float(label[2])w = float(label[3])h = float(label[4])# convert x,y,w,h to x1,y1,x2,y2imagePath = os.path.join(originImagesDir,txtFile.replace('txt', 'jpg'))print(imagePath)image = cv2.imread(imagePath)print(image.shape)H, W, _ = image.shapex1 = (x - w / 2) * Wy1 = (y - h / 2) * Hx2 = (x + w / 2) * Wy2 = (y + h / 2) * H# 为了与coco标签方式对,标签序号从1开始计算fw.write(txtFile.replace('txt', 'jpg') + ' {} {} {} {} {}\\n'.format(int(label[0]), x1, y1, x2, y2))print('{} done'.format(txtFile))
def secon_tojson():#-------------------可用-----------------------------------'''function:可将yolo格式的数据集转换为coco格式的(2)需要准备:classes.txt:一行就是一个类,不需要数字,只要类名称annos.txt:由上一个.py文件生成images:与annos.txt对应的图片,需要有序号生成.json文件,在annotations文件下'''# ------------用os提取images文件夹中的图片名称,并且将BBox都读进去------------# 根路径,里面包含images(图片文件夹),annos.txt(bbox标注),classes.txt(类别标签),# 以及annotations文件夹(如果没有则会自动创建,用于保存最后的json)root_path = root_dir# 用于创建训练集或验证集phase = 'instances_val2017' # 需要修正,保存后的json文件名# dataset用于保存所有数据的图片信息和标注信息dataset = {'categories': [], 'annotations': [], 'images': []}# 打开类别标签with open(os.path.join(root_path, 'classes.txt')) as f:classes = f.read().strip().split()# 建立类别标签和数字id的对应关系for i, cls in enumerate(classes, 1):dataset['categories'].append({'id': i, 'name': cls, 'supercategory': 'mark'})# 读取images文件夹的图片名称indexes = os.listdir(root_path+'/images/') #读取文件# 统计处理图片的数量global countcount = 0# 读取Bbox信息with open(root_path+ '/annos1.txt') as tr: #读取文件annos = tr.readlines()# ---------------接着将,以上数据转换为COCO所需要的格式---------------for k, index in enumerate(indexes):count += 1# 用opencv读取图片,得到图像的宽和高im = cv2.imread(root_path+'/images/' + index) #读取文件height, width, _ = im.shapeprint(index)# 添加图像的信息到dataset中dataset['images'].append({'file_name': index.replace("\\\\", "/"),'id': int(index[:5]), # 提取文件名 里的数字标号 必须是int类型,不能是str'width': width,'height': height})for ii, anno in enumerate(annos):parts = anno.strip().split()# 如果图像的名称和标记的名称对上,则添加标记if parts[0] == index:# 类别cls_id = parts[1]# x_minx1 = float(parts[2])# y_miny1 = float(parts[3])# x_maxx2 = float(parts[4])# y_maxy2 = float(parts[5])width = max(0, x2 - x1)height = max(0, y2 - y1)dataset['annotations'].append({'area': width * height,'bbox': [x1, y1, width, height],'category_id': int(cls_id),'id': ii,'image_id': int(index[0:5]), # 提取文件名里的数字标号 必须是int类型,不能是str'iscrowd': 0,# mask, 矩形是从左上角点按顺时针的四个顶点'segmentation': [[x1, y1, x2, y1, x2, y2, x1, y2]]})print('{} images handled'.format(count))# 保存结果的文件夹folder = os.path.join(root_path, './annotations')if not os.path.exists(folder):os.makedirs(folder)json_name = os.path.join(root_path, './annotations/{}.json'.format(phase))with open(json_name, 'w') as f:json.dump(dataset, f, ensure_ascii=False, indent=1)'''
function:绘制标注的数据集和对应图片的位置是否正确
绘制前三张,如果yoyo转换标注的json数据集没有问题,则也能在图上画出框'''
def third_toview():json_path = root_dir+'/annotations/instances_val2017.json'# json_path = r'predictions.json'img_path = root_dir+'/images' #json对应的图片# load coco datacoco = COCO(annotation_file=json_path)# get all image index infoids = list(sorted(coco.imgs.keys()))print("number of images: {}".format(len(ids)))# get all coco class labelscoco_classes = dict([(v["id"], v["name"]) for k, v in coco.cats.items()])# 遍历前三张图像for img_id in ids[:3]:# 获取对应图像id的所有annotations idx信息ann_ids = coco.getAnnIds(imgIds=img_id)# 根据annotations idx信息获取所有标注信息targets = coco.loadAnns(ann_ids)# get image file namepath = coco.loadImgs(img_id)[0]['file_name']# read imageimg = Image.open(os.path.join(img_path, path)).convert('RGB')draw = ImageDraw.Draw(img)# draw box to imagefor target in targets:x, y, w, h = target["bbox"]x1, y1, x2, y2 = x, y, int(x + w), int(y + h)draw.rectangle((x1, y1, x2, y2))draw.text((x1, y1), coco_classes[target["category_id"]])# show imageplt.imshow(img)plt.show()
first_to_annostxt()
secon_tojson()
third_toview()
如图所示准备数据即可

参考https://blog.csdn.net/m0_59967951/article/details/126703053