自定义函数 | R语言批量计算组间差值

批量字符替换、数值大小比较并重新赋值
为了处理两列或者多列以及多变量重复样本间的组合差值,编了一个函数进行批量处理。今天与大家分享
DailyTools包中我编写的一个
cal_repeat函数。
为了实现2列变量重复样本的组合差值计算,如图所示:
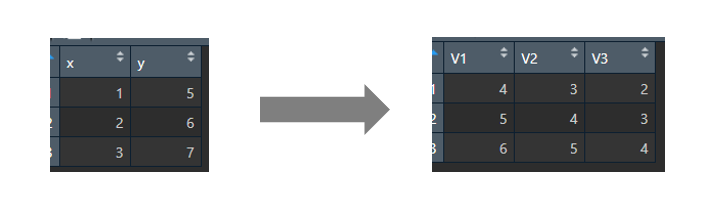
这是y的三个重复值与x的三个重复值组合做差,得出9个新的差值。如何使用R代码?R代码的实现过程:
x <- 1:3
y <- 5:7
data <- data.frame(x, y)
result <- as.data.frame(outer(y, x, FUN = "-"))
result
# V1 V2 V3
# 1 4 3 2
# 2 5 4 3
# 3 6 5 4
然而,实际情况下,数据集中可能存在实验处理甚至很多个,也可能不只一个目标变量,分组变量也不仅只有2个(也就是x和y可能还有更多需要相互进行组合运算的变量),如下图:‘’

对于上述的数据类型仅依赖outer函数想完成对应的计算也很复杂和麻烦,用excel所需时间更漫长。因此,写了一个函数来解决这个这个问题,从而实现多处理多变量下重复样本间的组合计算(可以做差值、比值及其他运算法则)。
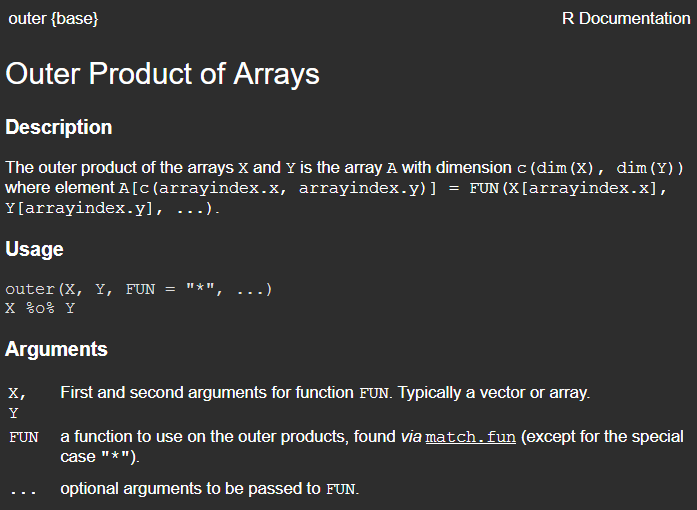
介绍完outer函数,回到今天的主题,我们先从github平台下载一下DailyTools包。
# install.packages("devtools")
# install.packages("remotes")
devtools::install_github("Jylande/DailyTools")
remotes::install_github("Jylande/DailyTools",force = TRUE)

成功下载后,并加载R包:
library(DailyTools)
然后看看对应函数的介绍:
?cal_repeat
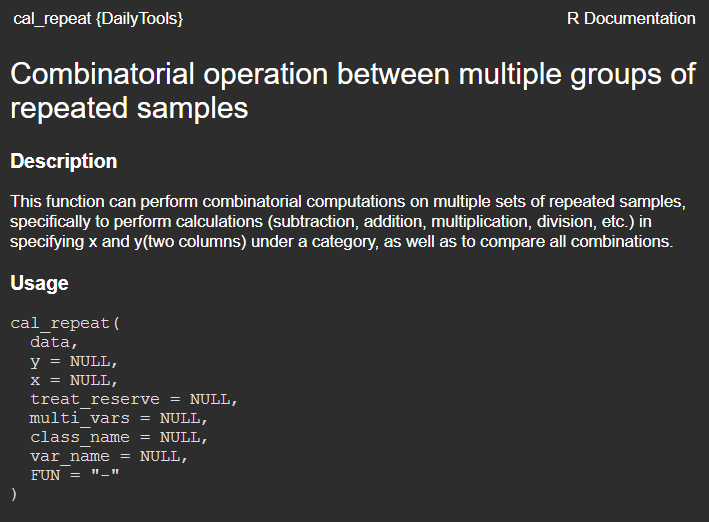
从介绍中可以看到函数主要用途。具体用法如下:
cal_repeat (data, y = NULL, x = NULL, treat_reserve = NULL, multi_vars = NULL, class_name = NULL, var_name = NULL, FUN = “-”) 。
从函数用法看,多个参数为NULL,都是交互式的,可以根据自己数据集的情况来做对应改写。
对应参数的介绍如下:

个人详细解读:
-
data: 数据为数据框结构,可以是长数据或者宽数据。 -
y: 该参数为指定2列需要做组合运算中主动的那列变量,默认不指定。 -
x: 该参数为指定2列需要做组合运算中的另外一列变量(被动),默认不指定。 -
treat_reserve: 若数据集中存在处理变量需要考虑,则指定这个参数。例如treat_reserve = c(“A”, “B”),"A"和"B"为数据集中两个处理变量,最多不超过5个处理变量(通常实验处理最多3个)。该参数设定后就可以考虑处理变量所构成分类组合的所有子集,这样就考虑所有处理组合的子集情况。如果默认则不考虑处理变量。 -
multi_vars: 数据是长数据时,该参数表明数据集中所需要计算的目标变量,如前三列为处理变量,另外一列是class_name,而第5到第10列均为目标变量,则可用multi_vars = 5:10 表示所有变量均考虑计算。数据为宽数据时,该参数的选择并不是目标变量,而是选择进行组合运算的变量数。比如例子中,X2001与X2005之间的5列变量均要考虑组合运算。 -
class_name: 这个参数仅在数据集是长数据时设定。设定对应所需要进行做差的分类变量,比如例子中主要计算"Var6"该变量中分类的组合差值,因此该参数在长数据集必须指定。而宽数据不需要使用该参数,因为宽数据以某个分类处理后的数据,已经完成了长数据转换成宽数据这一步骤。 -
var_name: 如果设定该参数,表明想指定的目标变量是单一变量,具体是某一个。在例子中,如我设定var_name = “A”, 表明在多个变量中,我只计算A这个变量,其他变量不考虑。当数据为长数据时,multi_vars参数与该参数所表达的内容相似(multi_vars可以选择多变量),因此两者不能同时存在。 -
FUN: 该参数与outer函数中FUN相同,这里主要是加减乘除四则运算,其他的一些运算可以参考outer函数中FUN参数使用。
cal_repeat()函数的实际操作
考虑到Examples内容非常详细。这里介绍几类典型且可能较为常用的例子:
# Trial data sets (Refer to the data structure of the example)
# long data
treat1 <- c("YES", "NO")
treat2 <- c("A", "B", "C")
treat3 <- c("a", "b", "c")
treat4 <- c("e", "f", "g")
treat5 <- c("D", "E")
class <- 2001:2005
vars_long <- expand.grid(treat1, treat2, treat3, treat4, treat5, class, stringsAsFactors = FALSE)set.seed(1)
data_long <- data.frame(vars_long,A = rnorm(n = nrow(vars_long), mean = 450, sd = 35),B = rnorm(n = nrow(vars_long), mean = 100, sd = 5),C = rnorm(n = nrow(vars_long), mean = 50, sd = 2)); data_long# wide data
vars_wide <- expand.grid(treat1, treat2, treat3, treat4, treat5)
vars <- rep(rep(LETTERS[1:3], each = 3), nrow(vars_wide))set.seed(1)
data_wide <- data.frame(vars, vars_wide, "2001" = rnorm(length(vars), mean = 100, sd = 10),"2002" = rnorm(length(vars), mean = 200, sd = 10),"2003" = rnorm(length(vars), mean = 300, sd = 10),"2004" = rnorm(length(vars), mean = 400, sd = 10),"2005" = rnorm(length(vars), mean = 500, sd = 10)); data_wide#1 For long data, consider multiple variables
result1 <- cal_repeat(data = data_long, multi_vars = 7:9, treat_reserve = NULL, class_name = "Var6", var_name = NULL, y = NULL, x = NULL,FUN = "-"); result1result1.1 <- cal_repeat(data = data_long, multi_vars = 7:8, treat_reserve = NULL, class_name = "Var6", var_name = NULL, y = NULL, x = NULL,FUN = "-"); result1.1#1.2 Specify a single variable
result2 <- cal_repeat(data = data_long, y = NULL, x = NULL, multi_vars = NULL, class_name = "Var6", treat_reserve = NULL, var_name = "B", FUN = "-"); result2result2.1 <- cal_repeat(data = data_long, y = NULL, x = NULL, multi_vars = NULL, class_name = "Var6", treat_reserve = NULL, var_name = "A", FUN = "-"); result2.1#1.3 Specify a single variable and specify x and y
result3 <- cal_repeat(data = data_long, y = "2005", x = "2001", multi_vars = NULL, class_name = "Var6", treat_reserve = NULL, var_name = "B", FUN = "-"); result3#1.4 Specify other categorical variable names
result4 <- cal_repeat(data = data_long, y = "E", x = "D", multi_vars = NULL,class_name = "Var5", treat_reserve = NULL, var_name = "B", FUN = "-"); result4result4.1 <- cal_repeat(data = data_long, class_name = "Var5", multi_vars = NULL,treat_reserve = NULL, y = NULL, x = NULL,var_name = "B", FUN = "-"); result4.1result4.2 <- cal_repeat(data = data_long, multi_vars = 7:8, var_name = NULL, treat_reserve = NULL, y = NULL, x = NULL,class_name = "Var5", FUN = "-"); result4.2#2.1 For wide data, consider multiple variables
result5 <- cal_repeat(data = data_wide, y = NULL, x = NULL, multi_vars = 7:9, treat_reserve = NULL, class_name = NULL, var_name = NULL, FUN = "-"); result5result5.1 <- cal_repeat(data = data_wide, y = NULL, x = NULL, multi_vars = 7:9, treat_reserve = NULL, class_name = NULL, var_name = "A", FUN = "-"); result5.1#2.2 Specify x and y
result6 <- cal_repeat(data = data_wide, y = "X2002", x = "X2001", multi_vars = NULL, treat_reserve = NULL, class_name = NULL, var_name = NULL, FUN = "-"); result6result6.1 <- cal_repeat(data = data_wide, y = "X2002", x = "X2001", multi_vars = NULL, treat_reserve = NULL, class_name = NULL, var_name = "A", FUN = "-"); result6.1#3.1 More control variables
# for long data
result7 <- cal_repeat(data = data_long, y = NULL, x = NULL, treat_reserve = c("Var1", "Var2"), var_name = NULL,multi_vars = 7:8, class_name = "Var6", FUN = "-"); result7result7.1 <- cal_repeat(data = data_long, y = NULL, x = NULL, treat_reserve = c("Var1", "Var2", "Var3"), var_name = NULL,multi_vars = 7:8, class_name = "Var6", FUN = "-"); result7.1 result7.2 <- cal_repeat(data = data_long, y = "2002", x = "2001", treat_reserve = c("Var1", "Var2", "Var3"), var_name = NULL,multi_vars = NULL, class_name = "Var6", FUN = "-"); result7.2 result7.3 <- cal_repeat(data = data_long, y = "2002", x = "2001", treat_reserve = c("Var1", "Var2", "Var3", "Var4", "Var5"),var_name = NULL, multi_vars = NULL, class_name = "Var6", FUN = "-"); result7.3 # for wide data
result8 <- cal_repeat(data = data_wide, y = NULL, x = NULL,treat_reserve = c("Var1", "Var2"), multi_vars = 7:9, class_name = NULL, var_name = NULL,FUN = "-"); result8result8.1 <- cal_repeat(data = data_wide, y = "X2002", x = "X2001",treat_reserve = c("Var1", "Var2", "Var3"), multi_vars = NULL, class_name = NULL, var_name = NULL,FUN = "-"); result8.1#4.1 Other calculation methods (such as division)
result9 <- cal_repeat(data = data_long, multi_vars = 7:8, treat_reserve = NULL, class_name = "Var6", var_name = NULL, y = NULL, x = NULL,FUN = "/"); result9
1.不考虑处理变量。考虑多变量和指定2列变量的情况(长数据):
数据如下,需要计算Var6这列变量中分类的组合运算(差值):
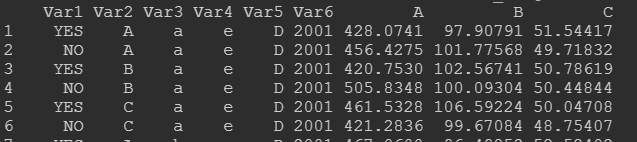
代码如下:我们考虑A-C三个变量,对应的是数据集中的7到9列,因此multi_vars = 7:9,class_name = “Var6”。
result1.1 <- cal_repeat(data = data_long, multi_vars = 7:9,
treat_reserve = NULL, class_name = "Var6", var_name = NULL,
y = NULL, x = NULL, FUN = "-"); result1.1
结果如下:
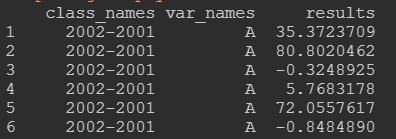
从结果来看,一共有接近35W行的数据,可想而知如果这个计算量在excel来处理得处理多久,另外还可能出错。使用这个函数只需要十秒左右就能得到结果。

可以看到,Var6所有情况都考虑了,目标变量ABC也都计算了。

如果指定y和x,对应的代码写法如下:
result1.2 <- cal_repeat(data = data_long, y = "2005", x = "2001",
multi_vars = 7:9, class_name = "Var6", treat_reserve = NULL,
var_name = NULL, FUN = "-"); result1.2
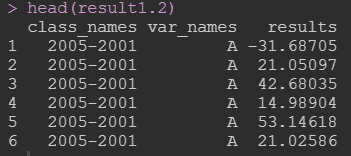

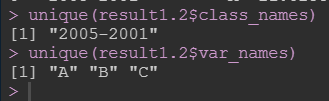
只考虑一个目标变量,并且指定x和y:
result1.3 <- cal_repeat(data = data_long, y = "2005", x = "2001",
multi_vars = NULL, class_name = "Var6", treat_reserve = NULL,
var_name = "A", FUN = "-"); result1.3
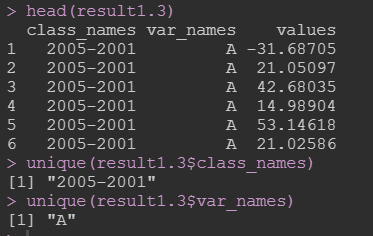
2.考虑处理变量。考虑多处理,多变量的情况(长数据):
数据如下,需要计算Var6这列变量中分类的组合运算(差值):
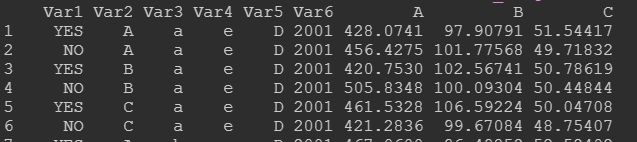
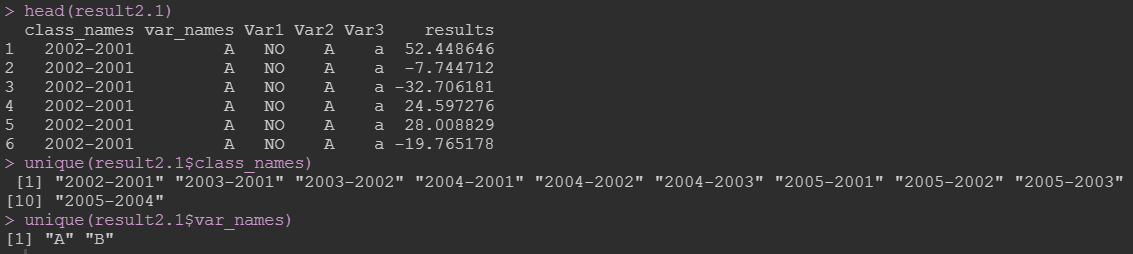
比如我们要考虑Var1-3共三个处理变量,treat_reserve 设定好即可。这里,目标变量我们只选择了7:8。
result2.1 <- cal_repeat(data = data_long, y = NULL, x = NULL,
treat_reserve = c("Var1", "Var2", "Var3"),
var_name = NULL, multi_vars = 7:8,
class_name = "Var6", FUN = "-"); result2.1

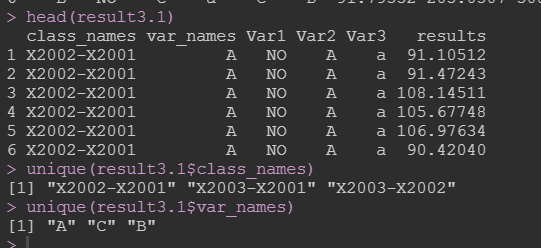
3.考虑处理变量。考虑多处理,多变量的情况(宽数据):
数据如下(差值)数据X2001-X2005应该是你所需要组合运算的变量分类:
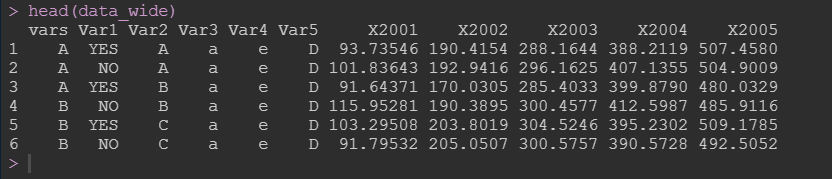
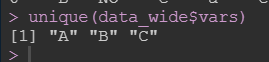
这里需要注意的是,当你的数据是宽数据时,你的目标变量的列名改为vars, 然后按行排列叠加。
result3.1 <- cal_repeat(data = data_wide, y = NULL, x = NULL,treat_reserve = c("Var1", "Var2", "Var3"),multi_vars = 7:9, class_name = NULL, var_name = NULL,FUN = "-"); result3.1
在宽数据中进行运算时,multi_vars这个参数表明你要保留的分类变量,比如只打算计算X2001-X2003之间的组合比较,即7:9。如果要考虑X2001-X2005,则7:11。结果如下:

经过参数介绍,大家应该在使用时也可以分清楚参数的差异,有问题请留言~