【流畅的Python学习笔记】2023.4.21

此栏目记录我学习《流畅的Python》一书的学习笔记,这是一个自用笔记,所以写的比较随意
特殊方法(魔术方法)
不管在哪种框架下写程序,都会花费大量时间去实现那些会被框架本身调用的方法,Python 也不例外。Python 解释器碰到特殊的句法时,会使用特殊方法去激活一些基本的对象操作,这些特殊方法的名字以两个下划线开头,以两个下划线结尾(例如 __getitem__)
命名元组
Python中有一种特殊的元组叫做命名元组,英文名叫namedtuple,按我的理解就是一个轻量级的“类”,它在collections库中,我将它类比为C语言的结构体,但是和结构体不同的是,它里面的元素可以按索引访问,自 Python 2.6开始,namedtuple 就加入到 Python 里,用以构建只有少数属性但是没有方法的对象,具体用法如下代码所示:
from collections import namedtuple# 定义一个namedtuple类型People_Info,并包含id,name和phone_number属性。
People_Info = namedtuple('People_Info', ['id', 'name', 'phone_number'])# 创建一个People_Info对象
people_info1 = People_Info(id='001', name='jack', phone_number='1333333XXXX')# 通过使用_make方法直接对命名元组整体赋值(用List)
people_info2 = People_Info._make(['002', 'tom', '122XXXXXXXX'])print(people_info1)
print(people_info2)# 通过使用_replace方法修改(原本对象不变)命名元组的元素值以此生成新命名元组
# 注意:此处生成的是新命名元组,不是真的修改对象的值
people_info3 = people_info2._replace(id='003', name="mike")
print(people_info3)# 通过.访问元组成员
print(people_info1.name)# 通过下标访问元组成员
print(people_info2[0])# 将元组转换成字典
people_info1_dict = people_info1._asdict()
print(people_info1_dict)
这段代码执行结果如下:

接下来我模仿官方示例写一段假面骑士decade卡盒的示例
__getitem__和__len__
魔术方法__getitem__支持按索引访问,即对对象做[]操作,而__len__则让对象支持Python中的len()方法,读取长度,具体用法我写了一个示例:
(Python 已经内置了从一个序列中随机选出一个元素的函数 random.choice)
from collections import namedtuple
from random import choice# 骑士元组,骑士名字,模式列表,攻击方式列表
KamenRider = namedtuple('KamenRider', ['name', 'form_list', 'attack_list'])
# 将旧10年骑士的名字和其他信息录入到卡盒列表中
cards_list = [KamenRider(name='Kuuga', form_list=['Titan', 'Dragon', 'Pegasus'], attack_list=None),KamenRider(name='Agito', form_list=['Flame', 'Storm'], attack_list=['Gigant']),KamenRider(name='Ryuki', form_list=None, attack_list=['Advent', 'StrikeVent']),KamenRider(name='Faiz', form_list=['Axel'], attack_list=['AutoVajin', 'SideBasshar']),KamenRider(name='Blade', form_list=None, attack_list=['Metal', 'Mach']),KamenRider(name='Hibiki', form_list=None, attack_list=['OngekibouRekka', 'Onibi']),KamenRider(name='Kabuto', form_list=None, attack_list=['ClockUp']),KamenRider(name='Den-o', form_list=['Gun', 'Ax', 'Rod'],attack_list=['Ore Sanjou!', 'Bokuni Tsurarete Miru?', 'Kotaewa Kiite Nai', 'Nakerude','Utchari']),KamenRider(name='Kiva', form_list=['Garulu', 'Dogga', 'Basshaa'], attack_list=None),KamenRider(name='Decade', form_list=None, attack_list=['Slash', 'Blast', 'Illusion', 'Invisible'])]# 卡面来打decade类
class Decade:# 当前是哪一个骑士(下标)now_index = 9# cards_list是卡盒列表def __init__(self, cards):self.cards = cards# len方法返回卡牌数量def __len__(self):return len(self.cards)# 变身方法def henshin(self):print("Henshin!")# 找到decade卡牌for item in self.cards:if item.name == 'Decade':print("Kamen Ride Decade!")returnprint("error!")return# __getitem__方法获取新的骑士驾驭def __getitem__(self, position):self.now_index = positionreturn self.cards[position].name# 随机当前骑士的攻击驾驭def attack_ride(self):if self.cards[self.now_index].attack_list is not None:print("Attack Ride " + choice(self.cards[self.now_index].attack_list))# 随机当前骑士的模式驾驭def form_ride(self):if self.cards[self.now_index].form_list is not None:print("Form Ride " + self.cards[self.now_index].name + " " + choice(self.cards[self.now_index].form_list))# 当前骑士的终极攻击驾驭def final_attck_ride(self):str_f = ""# 循环几次,模仿腰带提示的结巴声音for i in range(0, 5):str_f = str_f + self.cards[self.now_index].name[0]print("Fianl Attack Ride " + str_f + self.cards[self.now_index].name + "!")# 写在类成员函数的随机假面驾驭def kamen_ride(self):print("Kamen Ride " + str(choice(self)) + "!")# 一次模式驾驭,一次攻击驾驭,一次终极攻击驾驭def do_attack(self):self.form_ride()self.attack_ride()self.final_attck_ride()# 神主牌模式,使用__getitem__方法,骑士卡牌可以迭代,故可以模拟出神主牌模式def complete_form(self):for card_name in self:print(card_name+" ", end='')print("\\nFinal Kamen Ride Decade!")player = Decade(cards_list)
player.henshin()
player.attack_ride()
player.attack_ride()
player.attack_ride()
player.final_attck_ride()
# 随机假面驾驭
print("Kamen Ride " + str(choice(player)) + "!")
player.form_ride()
player.attack_ride()
player.final_attck_ride()
player.kamen_ride()
player.do_attack()
player.complete_form()效果:
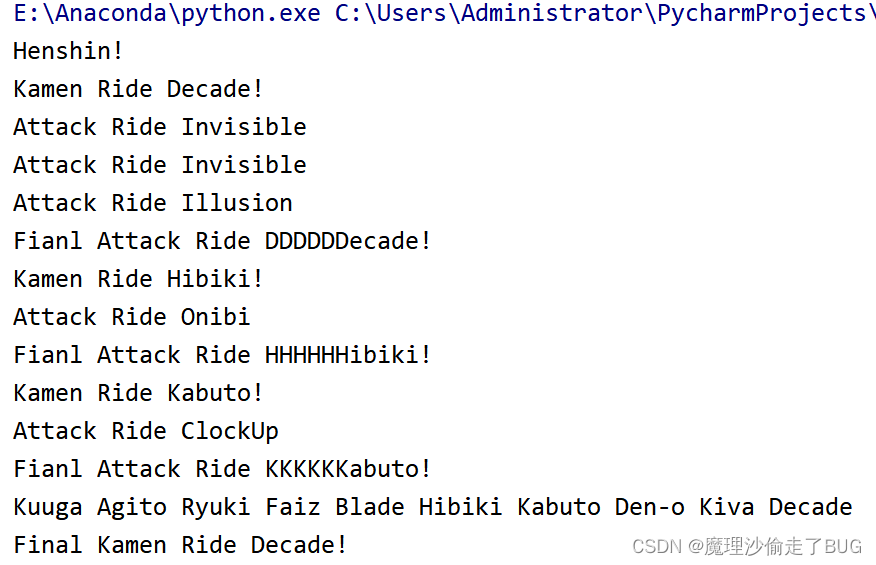
倒数第三行到倒数第五行的输出也符合官方原作了(笑)


__contains__方法和排序
__contains__方法是⽤来判断集合中是否包含某个元素的⽅法,一个集合类型没有实现__contains__方法,那么 in 运算符就会按顺序做一次迭代搜索,由于Decade类是可以迭代的(有len和getitem魔术方法),所以可以直接用关键字in来判断,继续以刚才的例子做演示:
print('Decade' in player)
这里会显示True
再举一个人员信息的例子:
from collections import namedtuple# 命名元组构造人员类
# 人员id,人员名字,人员年龄,人员工资
People = namedtuple("People", ['id', 'name', 'age', 'salary'])
peo_list = [People(1, 'Tom', 34, 6000), People(2, 'Jack', 3, 0), People(3, 'Mary', 21, 3000),People(4, 'Bob', 16, 1000), People(5, 'Sim', 61, 10000), People(6, 'Black', 50, 30000)]# 人员信息类
class PeopleInfo:# people_list是人员列表# number是总人数def __init__(self, people_list):self.people_list = people_listself.number = len(people_list)def __getitem__(self, position):return self.people_list[position]def __len__(self):return self.number# __contains__方法用来查找人员信息中是否有幼儿,儿童,少年,青年,中年,老年def __contains__(self, item):# 用字典保存年龄范围# ()是元组age_range = {'幼儿': (0, 6),'儿童': (7, 14),'少年': (15, 18),'青年': (19, 39),'中年': (40, 59),'老年': (60, 200)}for people_item in self:if age_range[item][0] < people_item.age <= age_range[item][1]:return Truereturn False# score_high函数对人进行升序排序,按年龄占30%,工资占70%的顺序排序
def score_high(people_name):return people_name.age * 0.3 + people_name.salary * 0.7people_info = PeopleInfo(peo_list)
# 迭代打印人员信息列表
for people in people_info:print(people)print("\\n")
# 按socre_high规则排序
for p in sorted(people_info, key=score_high):print(p)# 查看人群里是否有幼儿,儿童,少年,青年,中年,老年
print('青年' in people_info)
print('老年' in people_info)
print('儿童' in people_info)
运行结果:
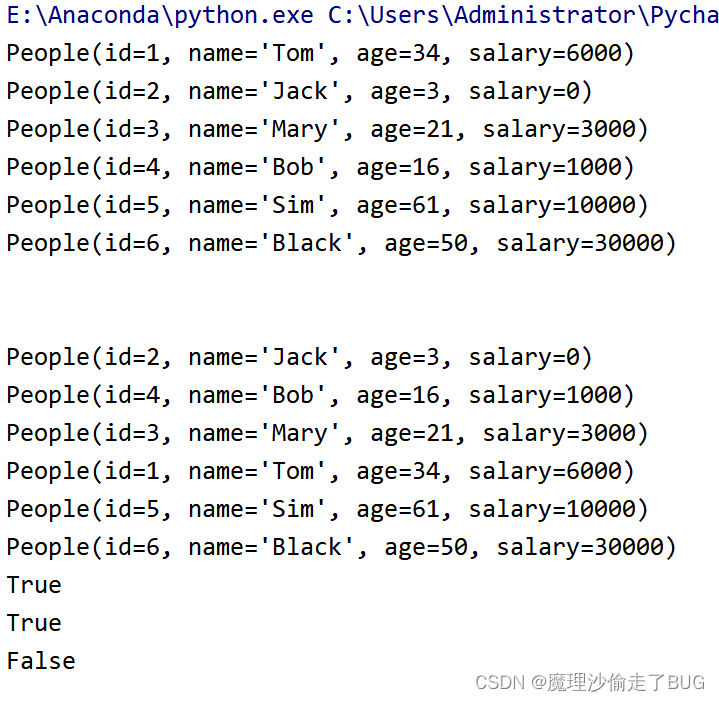
模拟数值类型、列表表达式和lambda表达式
lambda表达式
Lambda 表达式(lambda expression)是一个匿名函数,Lambda表达式基于数学中的λ演算得名,直接对应于其中的lambda抽象(lambda abstraction),是一个匿名函数,即没有函数名的函数。
lambda 参数:操作(参数)
lambda [arg1[,arg2,arg3....argN]]:expression
列表表达式(列表推导)
[ 表达式 for 迭代变量 in 可迭代对象 if 条件表达式 ]
这样迭代遍历效率更高一些
模拟数值类型
模仿书中例子,写了一个多维度的欧几里得空间下的向量类,重载了加减乘除运算符,并且加了一些错误提示,实现了任意多维度向量的加减
import math# 欧几里得空间下的向量类
class Vector:# 初始化一个多维欧几里得空间向量def __init__(self, *x):# 存储向量的列表self.vec_list = list(x)# 向量的维度self.dim = len(self.vec_list)# __repr__方便打印自我描述信息def __repr__(self):# 打印的时候中间用一个列表表达式对每一个元素打印并加逗号,显示出向量return f"Vector({', '.join(str(x) for x in self.vec_list)})"# __abs__方法,求向量模长def __abs__(self):# 使用列表表达式并不遍历列表,更加高效return math.sqrt(sum(i 2 for i in self.vec_list))# __len__方法,求向量的维度def __len__(self):return self.dim# __add__方法,向量加法,要求两个向量必须维度一致(原向量在左侧)def __add__(self, other):# 先检测加的是不是向量if isinstance(other, Vector):# 首先检测向量的维度是否相同,不同则抛出异常if self.dim != other.dim:raise ValueError("向量维度不同!\\n")# 用*解包数组,让它们变成一个个参数return Vector(*[x + y for x, y in zip(self.vec_list, other.vec_list)])else:raise TypeError("向量只能和向量相加!")# __radd__方法,向量加法,要求两个向量必须维度一致(原向量在右侧)def __radd__(self, other):# 先检测加的是不是向量if isinstance(other, Vector):# 首先检测向量的维度是否相同,不同则抛出异常if self.dim != other.dim:raise ValueError("向量维度不同!\\n")# 用*解包数组,让它们变成一个个参数return Vector(*[x + y for x, y in zip(self.vec_list, other.vec_list)])else:raise TypeError("向量只能和向量相加!")# __mul__实现向量的标量乘法和向量的点乘(原向量在左侧)def __mul__(self, other):# 如果other是整型或浮点型的数字类型,就执行向量标量乘法if isinstance(other, (int, float)):return Vector(*[i * other for i in self.vec_list])elif isinstance(other, Vector):# 首先检测向量的维度是否相同,不同则抛出异常if self.dim != other.dim:raise ValueError("向量维度不同!\\n")return sum(x * y for x, y in zip(self.vec_list, other.vec_list))raise TypeError("无法计算给定类型的向量")# __rmul__实现向量的标量乘法和向量的点乘(原向量在右侧)def __rmul__(self, other):# 如果other是整型或浮点型的数字类型,就执行向量标量乘法if isinstance(other, (int, float)):return Vector(*[i * other for i in self.vec_list])elif isinstance(other, Vector):# 首先检测向量的维度是否相同,不同则抛出异常if self.dim != other.dim:raise ValueError("向量维度不同!\\n")return sum(x * y for x, y in zip(self.vec_list, other.vec_list))raise TypeError("无法计算给定类型的向量")# __truediv__实现向量除一个标量def __truediv__(self, other):if isinstance(other, (int, float)):if other == 0:raise ValueError("不能除0!")return Vector(*[i / other for i in self.vec_list])raise TypeError("无法计算给定类型的向量")# __rtruediv__告诉用户向量无法做除数def __rtruediv__(self, other):raise TypeError("向量无法做除数")# __bool__如果一个向量的模是 0,那么就返回 False,其他情况则# 返回 True。def __bool__(self):return bool(abs(self))vec1 = Vector(3, 3, 3, 3)
vec2 = Vector(2, 2, 2, 2)
print(vec1)
print(abs(vec1))
print(len(vec1))
print(vec2 + vec1)
print(3 * vec1)
print(vec2 * 10)
vec3 = Vector(1, 1, 1)
print(len(vec3))
print(bool(vec3))
vec4 = Vector(0, 0, 0)
print(bool(vec4))运行结果:

ord方法和列表表达式,map,filter等的练习
ord方法返回一个字符的ascii码,fliter(过滤条件函数,迭代器)
symbols = 'abcdef'
codes = [ord(symbol) for symbol in symbols]
print(codes)

P.S Python 会忽略代码里 []、{} 和 () 中的换行,因此如果你的代码里有多行的列表、列表推导、生成器表达式、字典这一类的,可以省略不太好看的续行符 \\。
symbols = 'abcdef'
codes = [ord(symbol) for symbol in symbols if ord(symbol)>100]
print(codes)

symbols = 'abcdef'
codes = list(filter(lambda c: c > 100, map(ord, symbols)))
print(codes)
笛卡尔积
笛卡尔积的具体作用如图

集合X={red,green,yellow},集合Y={A,B}
X与Y做笛卡尔积就是上面这个结果
from collections import namedtuple
Tshirts = namedtuple("Tshirts",['color', 'type'])
# 笛卡尔积测试代码
color_list = ["red", "green", "yellow"]
type_list = ['A', 'B']
result_list = [Tshirts(color,type) for color in color_list for type in type_list]
for item in result_list:print(item)

生成器表达式
生成器表达式的语法跟列表推导差不多,只不过把方括号换成圆括号而已。
symbols = 'abcdef'
codes = list(ord(symbol) for symbol in symbols)
number = sum(ord(symbol) for symbol in symbols)
print(codes)
print(number)
生成器表达式比较节省内存
from collections import namedtuple
Tshirts = namedtuple("Tshirts",['color', 'type'])
# 生成式表达器生成笛卡尔积测试代码
color_list = ["red", "green", "yellow"]
type_list = ['A', 'B']
result_list = (Tshirts(color,type) for color in color_list for type in type_list)
for item in result_list:print(item)

实际上还能使用 %符号来给字符串做格式化输出
from collections import namedtupleTshirts = namedtuple("Tshirts", ['color', 'type'])
# 生成式表达器生成笛卡尔积测试代码
color_list = ["red", "green", "yellow"]
type_list = ['A', 'B']
result_list = ('%s %s' % Tshirts(color, type) for color in color_list for type in type_list)
for item in result_list:print(item)
用到生成器表达式之后,内存里不会留下一个有 6 个组合的列表,因为生成器表达式会在每次 for 循环运行时才生成一个组合。如果要计算两个各有 1000 个元素的列表的笛卡儿积,生成器表达式就可以帮忙省掉运行 for 循环的开销,即一个含有 100 万个元素的列表。