分布式文件系统HDFS的多问多答

简述HDFS的优缺点
HDFS的优良特性:
①兼容廉价的硬件设备。在成百上千台廉价服务器中存储数据,常会出现节点失效的情况,因此HDFS设计了快速检测硬件故障和进行自动恢复的机制,可以实现持续监视、错误检查、容错处理和自动恢复,从而在硬件出错的情况下也能实现数据的完整性。
②流数据读写。普通文件系统主要用于随机读写以及与用户进行交互,HDFS则是为了满足批量数据处理的要求而设计的,因此为了提高数据吞吐率,HDFS放松了一些POSIX的要求,从而能够以流式方式来访问文件系统数据。
③大数据集。HDFS中的文件通常可以达到GB甚至TB级别,一个数百台机器组成的集群可以支持千万级别这样的文件。
④简单的文件模型。HDFS采用了“一次写入、多次读取”的简单文件模型,文件一旦完成写入,关闭后就无法再次写入,只能被读取。
⑤强大的跨平台兼容性。HDFS是采用Java语言实现的,具有很好的跨平台兼容性,支持Java虚拟机的机器都可以运行HDFS。
HDFS的局限性:
①不适合低延迟数据访问。HDFS主要是面向大规模数据批量处理而设计的,采用流式数据读取,具有很高的数据吞吐率,但是,这也意味着较高的延迟。因此,HDFS不适合用在需要较低延迟(如数十毫秒)的应用场合。对于低延时要求的应用程序而言,HBase是一个更好的选择。(注:HBase是一个高可靠、高性能、面向列、可伸缩的分布式数据库,主要用来存储非结构化和半结构化的松散数据)
②无法高效存储大量小文件。小文件是指文件大小小于一个块的文件,HDFS无法高校存储和处理大量小文件,过多小文件会给系统扩展性和性能带来诸多问题。
③不支持多用户写入及任意修改文件。HDFS只允许一个文件有一个写入者,不允许多个用户对同一个文件执行写操作,而且只允许对文件执行追加操作,不能执行随机写操作。
简述HDFS的体系结构
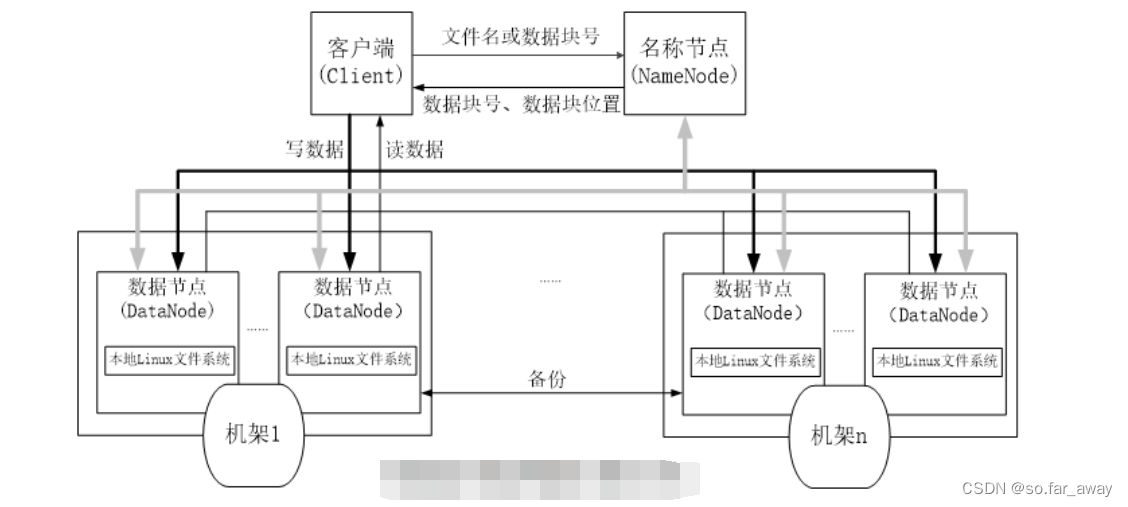
HDFS采用了主从(Master/Slave)的结构模型,一个HDFS集群包括一个名称节点(NameNode)和若干个数据结点(DataNode)。
名称节点作为中心服务器,负责管理文件系统的命名空间及客户端对文件的访问。
集群中的数据节点一般是一个节点运行一个数据节点进程,负责处理文件系统客户端的读/写请求,在名称节点的统一调度下进行数据块的创建、删除和复制等操作。
每个数据节点的数据实际上是保存在本地Linux文件系统中的。
每个数据节点会周期性地向名称节点发送“心跳”信息,报告自己的状态,没有按时发送心跳信息的数据节点会被标记为“死机”,不会再给它分配任何I/O请求。
请论述HDFS中SecondaryNameNode的作用和工作原理
第二名称节点的作用:
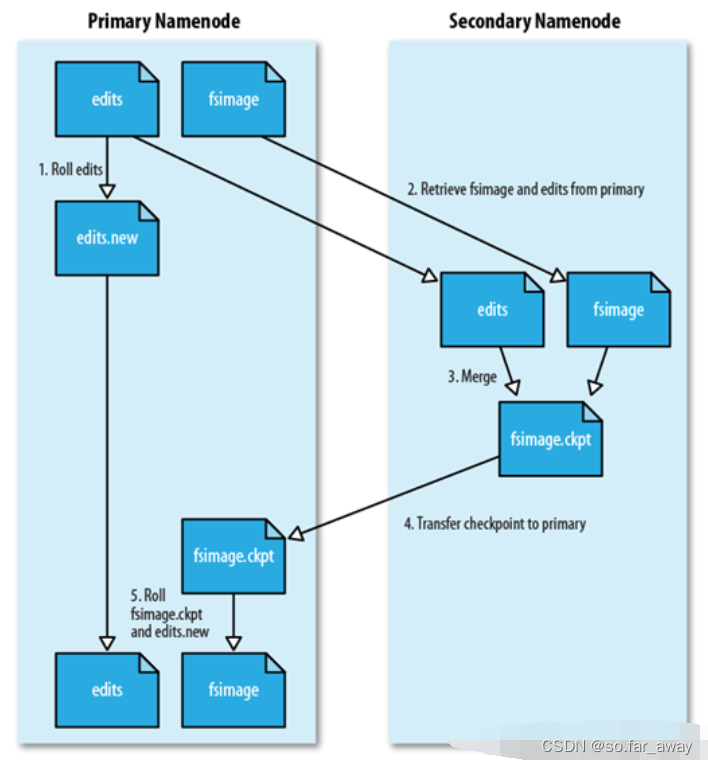
为了有效解决EditLog逐渐变大带来的问题,HDFS在设计中采用了第二名称节点(Secondary NameNode)。
①SecondaryNameNode可以完成EditLog与FsImage的合并操作。第二名称节点会定期和名称节点通信,从名称节点获取FsImage文件和EditLog文件,执行合并操作得到新的FsImage.ckpt文件。
②SecondaryNameNode可以作为名称节点的“检查点”。第二名称节点会周期性地备份名称节点中的原数据信息,当名称节点发生故障时,就可以用第二名称节点中记录的元数据信息进行系统恢复。但是需要注意的是,第二名称节点并不能起到“热备份”的作用,即使有了第二名称节点的存在,当名称节点发生故障时,系统还是有可能会丢失部分元数据信息的。
第二名称节点的工作原理:
①SecondaryNameNode会定期与NameNode通信,请求其停止使用EditLog文件,暂时将新的写操作写到一个新的文件edit.new上来,这个操作是瞬间完成的,上层写日志的函数完全感受不到差别。
②SecondaryNameNode通过HTTP GET方式从NameNode上获取到FSImage和EditLog文件,并下载到本地的相应目录下。
③SecondaryNameNode将下载下来的FSImage载入到内存,然后一条一条地执行EditLog文件中的各项更新操作,使得内存中的FSImage保持最新;这个过程就是EditLog与FsImage文件合并。
④SecondaryNameNode执行玩③操作之后,会通过post方式将新的FsImage文件发送到NameNode节点上。
⑤NameNode将从SecondaryNameNode接收到的新的FsImage替换旧的FsImage文件,同时将edit.new替换EditLog文件,通过这个过程EditLog就变小了。
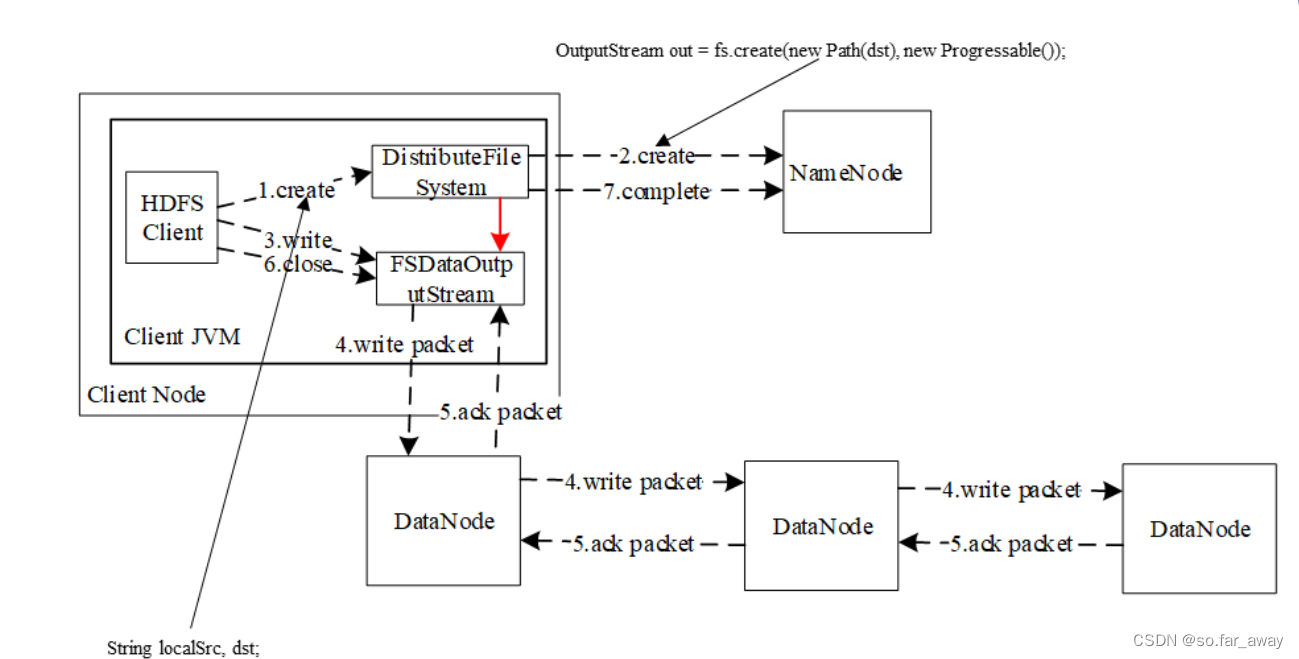
请论述HDFS写数据原理
①客户端通过FileSystem.create()创建文件,相应地,在HDFS中Distributed FileSystem具体实现了FileSystem。因此,调用create()方法后,DistributedFileSystem会创建输出流FSDataOutputStream,对于HDFS而言,具体的输出流就是DFSOutputStream。
②然后,DistributedFileSystem通过RPC远程调用名称节点,在文件系统的命名空间中创建一个新的文件。名称节点会执行一些检查,检查过后,名称节点会构造一个新文件,并添加文件信息。远程方法调用结束后,DistributedFileSystem会利用DFSOutputStream来实例化FSDataOutputStream来实例化FSDataOutputStream,并返回给客户端,客户端使用和这个输出流写入数据。
③获得输出流FSDataOutputStream以后,客户端调用输出流的write()方法向HDFS中对应的文件写入数据。
④客户端向输出流FSDataOutputStream中写入的数据会首先被分成一个个的分包,这些分包被放入DFSOutputStream对象的内部队列。
⑤因为各个数据节点位于不同的机器上,数据需要通过网络发送。
⑥客户端调用close()方法关闭输出流,此时开始,客户端不会再向输出流中写入数据,所以,当DFSOutputStream对象内部队列中的分包都收到应答以后,就可以使用ClientProtocol.complete()方法通知名称节点关闭文件,完成一次正常的写文件过程。