ETCD(四)读请求处理过程

客户端通过etcdctl执行get命令
etcdctl get name --endpoints localhost:12379,192.158.00.32:12379
client端
首先是client会解析这条命令,包括其中的get API方法,key值,请求server地址。解析完之后etcdctl会创建一个clientv3库对象,etcd clientv3会采用gRPC负载均衡机制来实现负载均衡策略向其中的一个服务端发送RPC请求。
ETCD负载均衡:默认是使用Round Robin策略。即按照server地址顺序一次次建立长连接,所有请求均匀分配到server连接中。这种算法的优点是简单易实现,能够平均分配请求到每个服务器上,但是它无法考虑服务器的实际负载情况,可能会导致某些服务器的负载过高,而其他服务器的负载过低。
除了Round Robin策略,gRPC还提供了其他负载均衡策略,如Least Connection、Random、Weighted Round Robin等。这些策略可以根据实际情况进行选择,以达到更好的负载均衡效果。在etcd clientv3中,可以通过配置选项来指定使用的负载均衡策略。
server端
服务器收到client发来的Range RPC请求后,会将请求发送到对应的handler函数上实现(根据serverName和RPC method来定位具体的handler执行函数)。在handler中,etcd通过拦截器提供了在执行请求前后的hook能力,保障数据安全。
串行读与线性读
虽然etcd能保证一致性,但是保证强一致性是需要消耗性能的,会牺牲部分吞吐量。因此当出现数据一致性问题时,这时就有串行读与线性读的区别了。数据一致性问题又是由于etcd只有leader节点能处理写请求写数据导致。
(1)当收到写请求时,leader节点先将请求内容持久化到WAL日志中,并且广播给所有follower节点;
(2)如果leader节点有收到一半以上节点的持久化成功消息,那么该请求对应的日志会被标识为已提交;
(3)各个节点的server会异步从raft模块获取已提交的日志条目,应用到状态机(boltdb)。
串行读
直接读取对应server状态机(boltdb)的数据,不会经过Raft协议与集群交互,具有低延迟、高吞吐量的特点,但是可能存在读取结果不一致的情况。
线性读
etcd默认的是线性读,在读取数据时会经过raft协议与集群交互保证数据一致,所以在延迟和吞吐量方面会比串行读有所降低。但是能保证数据的一致性。
线性读保证数据一致性的原理,离不开ReadIndex机制。
ReadIndex机制
ReadIndex机制就是实现线性读功能的重要机制,当server收到一个线性读请求时,
如果自己是leader节点,则会立即返回,如果自己是follower节点的话,则会向server节点发送一个readIndex请求来获取最新的已提交日志索引(committed index);
sever收到readIndex请求,还要向其他follower节点发送心跳来防止脑裂异常场景,一半以上节点确认leader节点身份后,leader才会把committed index返回给follower请求节点;
follower节点收到committed index后会和自己的applied index比较,如果applied index值大于committed index时,才表示自己的状态机数据是最新的,这是才会去通知读请求去状态机读取数据。
ETCD脑裂
ETCD是一个分布式键值存储系统,用于存储集群中的配置信息和元数据。ETCD脑裂是指在一个ETCD集群中,由于网络分区或其他原因,集群中的不同节点之间无法通信,导致集群分裂成两个或多个子集群的情况。这种情况下,每个子集群都认为自己是整个集群的唯一有效部分,可能会导致数据不一致和服务不可用等问题。
例如,如果一个ETCD集群由3个节点组成,其中两个节点之间的网络连接中断,这两个节点将形成一个子集群,而第三个节点将形成另一个子集群。此时,每个子集群都认为自己是整个集群的唯一有效部分,可能会导致数据不一致和服务不可用等问题。
ETCD读取旧数据
MVCC
etcd的多版本并发控制(MVCC)解决了etcd v2不支持历史版本、不支持多key事务问题。
ETCD的数据存储:
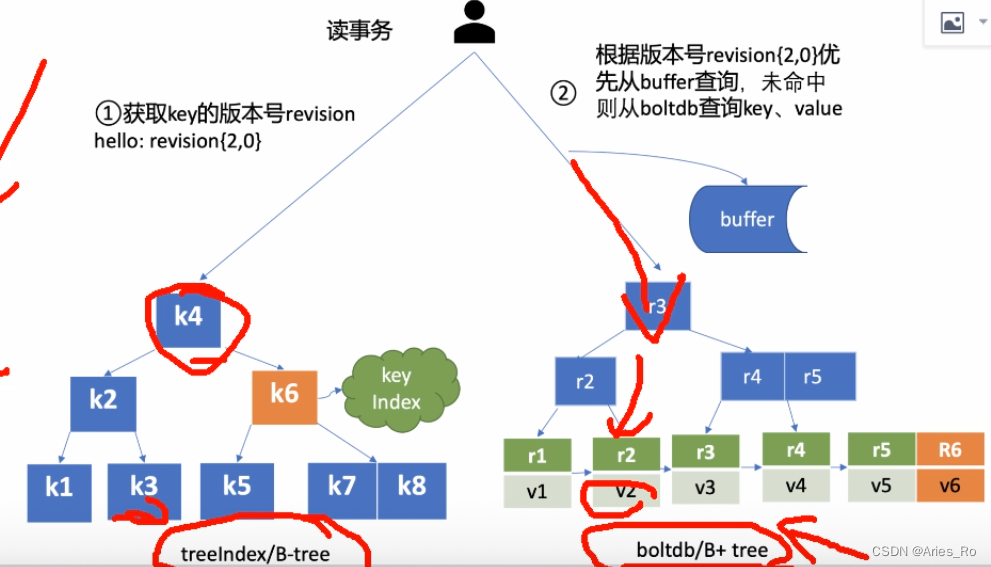
ETCD的键值存储以及版本信息涉及到一个B树treeIndex和一个B+树boltdb。
treeIndex的作用是作为辅助内存索引,加速对键的范围查询。treeIndex里面会存储key和对应的版本号。
boltdb里面保存了key的值以及历史版本信息。
读取数据时,先从treeIndex中获取key的版本号,再以版本号作为boltdb的key,从boltdb中得到具体的value的信息。
实际读取数据时,还涉及到一个buffer缓冲区,在读取数据时,并非所有请求都要经过boltdb。在访问boltdb前,ETCD会先从buffer中查找是否有key对应的值。如果有就可以直接返回而不用经过boltdb。ETCD通过buffer可以实现一部分的性能提高和数据一致性问题解决。因为buffer是将数据暂存在内存中,可以减少boltdb处理中对磁盘的读写操作;另外buffer会暂未提交的数据,此时可能boltdb里面没有,但是在buffer里面可以提前拿到。