Python爬虫实战——下载小说

前言
使用requests库下载开源网站的小说
注意:本文仅用于学习交流,禁止用于盈利或侵权行为。
操作系统:windows10 家庭版
开发环境:Pycharm Conmunity 2022.3
解释器版本:Python3.8
第三方库:requests、bs4
第三方库的安装
需要安装 bs4 和 requests 库
你可以参考我的以下文章获取些许帮助:
Python第三方库安装——使用vscode、pycharm安装Python第三方库
Python中requests库使用方法详解
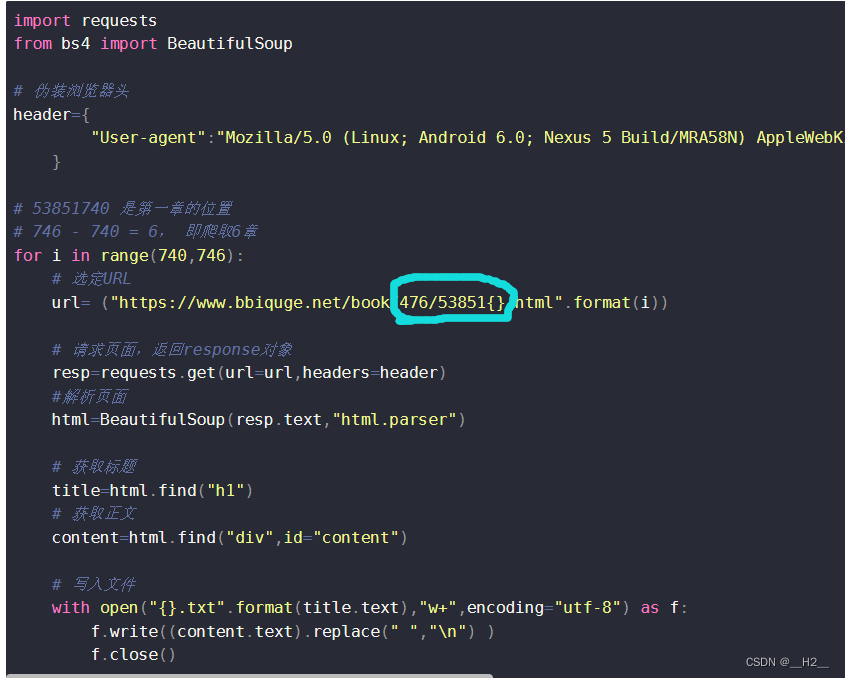
示例代码
import requests
from bs4 import BeautifulSoup# 伪装浏览器头
header={"User-agent":"Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Mobile Safari/537.36 Edg/112.0.1722.48"}# 53851740 是第一章的位置
# 746 - 740 = 6, 即爬取6章
for i in range(740,746):# 选定URLurl= ("https://www.bbiquge.net/book/476/53851{}.html".format(i))# 请求页面,返回response对象resp=requests.get(url=url,headers=header)#解析页面html=BeautifulSoup(resp.text,"html.parser")# 获取标题title=html.find("h1")# 获取正文content=html.find("div",id="content")# 写入文件with open("{}.txt".format(title.text),"w+",encoding="utf-8") as f:f.write((content.text).replace(" ","\\n") )f.close()
效果演示
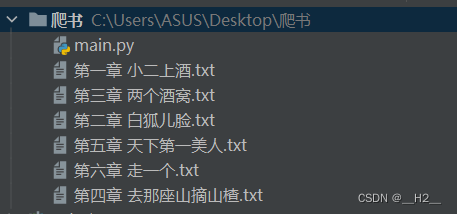

结尾
代码尚不完善,代码风格不符合标准,还有值得更改的地方,如:可以去除小说中的广告,合并到同一个txt文件中等
与爬取电影影评一样,也可以通过更改以下界面的值来达到爬取不同的小说的效果