爬虫学习 例子

以新能源网为例
【10-实战课】从源码获取豆瓣电影TOP250_哔哩哔哩_bilibili
1.查看网站结构

可见结构比较简单,直接循环爬取即可
2.代码(无数据存储)
import requests
from bs4 import BeautifulSoup
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.5359.95 Safari/537.36"}for start_num in range(194120,194124,1): #194120整篇文章在网站上没有response = requests.get(f"http://www.china-nengyuan.com/news/{start_num}.html", headers=headers)soup = BeautifulSoup(response.text,"html.parser")all_titles = soup.findAll("td", attrs={"height": "60","align": "center","style": "line-height:25px;"})all_links = soup.findAll("td", attrs={"valign": "top","class": "f16 news_link", "style": "padding-left:10px;line-height:30px"})for title in all_titles:print("标题为: ",title.find("h1", attrs={"class": "f20", "style": "margin:0;"}).string.strip())for link in all_links:all_texts = link.findAll("p")print("文章内容为: ")for text in all_texts:if text.findAll("img"): #文章中的图片也是p,也是段落,这里跳过continueprint(text.string) #只输出文本
"td",attrs={"height": "60","align": "center","style": "line-height:25px;"} 对应:
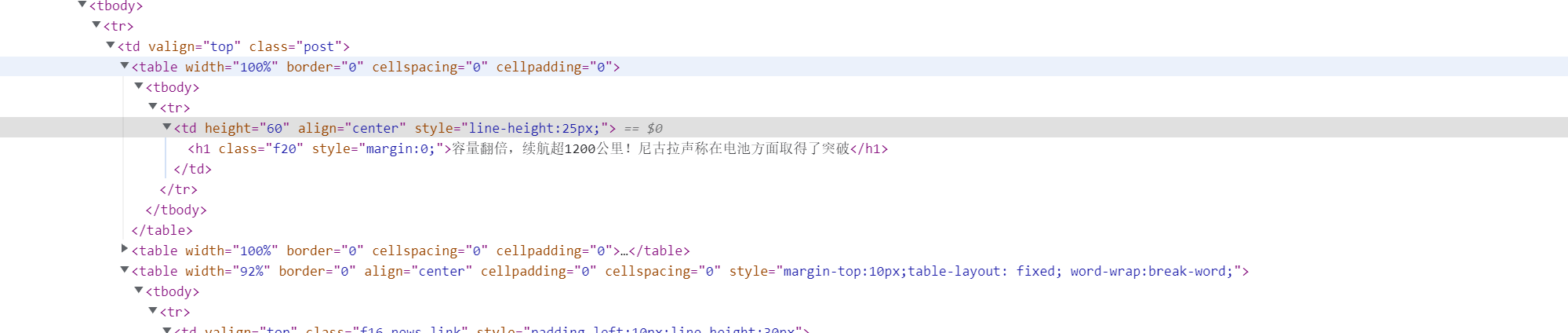
找到标题的特定属性,用attrs指定,即可输出标题信息。但现在输出的信息中有html标签。
所以输出时:
print("标题为: ",title.find("h1", attrs={"class": "f20", "style": "margin:0;"}).string.strip())
使用 find() 方法查找页面中的所有标题元素。在找到标题元素后,代码使用 string 属性获取标题文本,并使用 strip() 方法去除标题文本中的 HTML 标签和空格。最后,代码将标题文本输出到控制台。
接下来的正文都在td范围内
"td", attrs={"valign": "top","class": "f16 news_link", "style": "padding-left:10px;line-height:30px"}
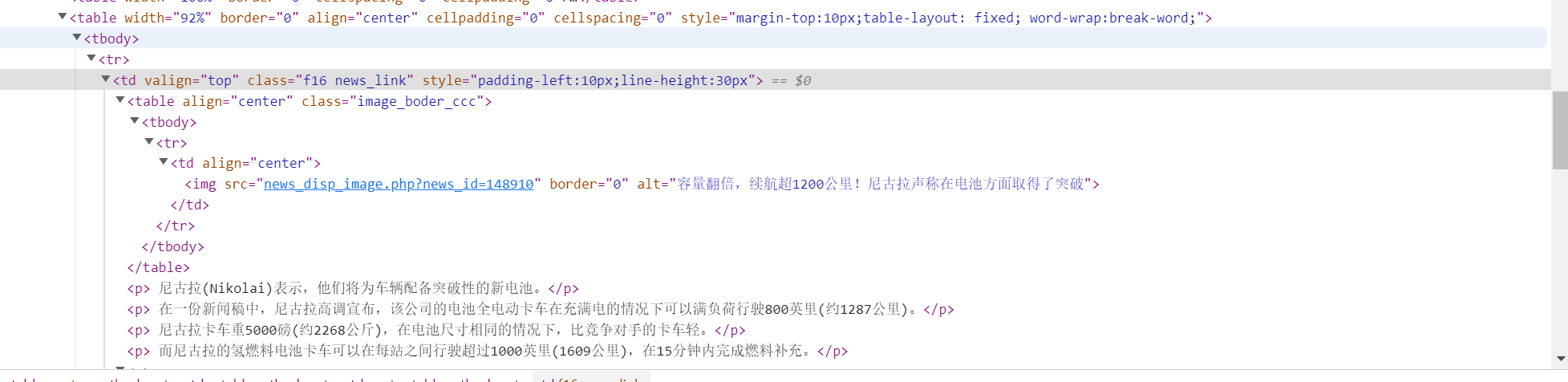
然后内容都在p范围内,直接输出文本即可
这里有个问题,在爬取文章段落时,文章中的图片也算一个段落,爬取后会在一行显示一个NONE,因为这一行没有文本信息。

所以这里用
for text in all_texts:if text.findAll("img"): #文章中的图片也是p,也是段落,这里跳过continue跳过
最后输出

2.爬取到桌面文件中
import requests
from bs4 import BeautifulSoup
import os
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.5359.95 Safari/537.36"}for start_num in range(194120,194124,1): #194120整篇文章在网站上没有response = requests.get(f"http://www.china-nengyuan.com/news/{start_num}.html", headers=headers)soup = BeautifulSoup(response.text,"html.parser")all_titles = soup.findAll("td", attrs={"height": "60","align": "center","style": "line-height:25px;"})all_links = soup.findAll("td", attrs={"valign": "top","class": "f16 news_link", "style": "padding-left:10px;line-height:30px"})for title in all_titles:print("标题为: ",title.find("h1", attrs={"class": "f20", "style": "margin:0;"}).string.strip())for link in all_links:all_texts = link.findAll("p")print("文章内容为: ")for text in all_texts:if text.findAll("img"): #文章中的图片也是p,也是段落,这里跳过continueprint(text.string) #只输出文本file_name = f"new_energy_bug.txt" #打开文件夹中的文件并写入with open(os.path.join("C:\\\\Users\\\\qjjt\\\\Desktop\\\\new_energy_bug", file_name), "a",encoding='utf-8') as f: #a表示继续写入,指定编码方式f.write(text.string)
依然存在问题
- 因为是从网站上爬取,所以文本位置在文件中间
- 这里没将标题写入
- 新闻之间未分开一定间隔
3.余下问题
改进后的代码
import requests
from bs4 import BeautifulSoup
import os
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.5359.95 Safari/537.36"}#必要准备
file_name = f"new_energy_bug.txt" #打开文件夹中的文件并写入#爬取文章并存入txt
for start_num in range(194120,194124,1): #194120整篇文章在网站上没有response = requests.get(f"http://www.china-nengyuan.com/news/{start_num}.html", headers=headers)soup = BeautifulSoup(response.text,"html.parser")all_titles = soup.findAll("td", attrs={"height": "60","align": "center","style": "line-height:25px;"})all_links = soup.findAll("td", attrs={"valign": "top","class": "f16 news_link", "style": "padding-left:10px;line-height:30px"})for title in all_titles:print("标题为: ",title.find("h1", attrs={"class": "f20", "style": "margin:0;"}).string.strip())#将标题写入TXT文件,然后立刻关闭with open(os.path.join("C:\\\\Users\\\\qjjt\\\\Desktop\\\\new_energy_bug", file_name), "a", encoding='utf-8') as f:f.write("\\n标题为: ")f.write(title.find("h1", attrs={"class": "f20", "style": "margin:0;"}).string.strip())f.close()for link in all_links:all_texts = link.findAll("p")with open(os.path.join("C:\\\\Users\\\\qjjt\\\\Desktop\\\\new_energy_bug", file_name), "a", encoding='utf-8') as f:f.write("\\n文章内容为: ")f.write("\\n")f.close()print("文章内容为: ")for text in all_texts:if text.findAll("img"): #文章中的图片也是p,也是段落,这里跳过continueprint(text.string) #只输出文本with open(os.path.join("C:\\\\Users\\\\qjjt\\\\Desktop\\\\new_energy_bug", file_name), "a",encoding='utf-8') as f: #a表示继续写入,指定编码方式f.write(text.string)#字符串靠左边file1 = open("C:\\\\Users\\\\qjjt\\\\Desktop\\\\new_energy_bug\\\\new_energy_bug.txt", 'r', encoding='utf-8') # 打开要去掉空行的文件
file2 = open("C:\\\\Users\\\\qjjt\\\\Desktop\\\\new_energy_bug\\\\new_energy_bug_new.txt", 'w+', encoding='utf-8') # 生成没有空行的文件for line in file1.readlines():line = line.lstrip() #从字符串的左边消除空格,strip()是两边同时消除if "标题" in line:file2.write("\\n\\n")file2.write(line)file1.close()
file2.close()1.标题写入
用的笨办法,在得到标题和内容后,打开TXT目标文件,写入字符串,然后自己关闭。因为with open在下面还有代码时会一直执行,所以最好手动关闭
2.消除字符串文本左边的空格
因为网页中的原始文本是在页面中间的,所以这里用lstrip()函数只去除每行文本左边的空格,strip()会去除两边,使文本都黏在一起。
3.新闻见分开一定距离
因为之前加了标题几个字,所以设置为只要检测到标题两个字在行,就先空两行,再把这行内容写入新文件中
最终效果
爬取新闻的第一个文件

经过整理的第二个文件

其中有一篇新闻只有标题,是因为网站把那篇文章删除了