压力测试防踩坑指南,压测中要注意的那些事儿


对于一些高频访问接口,压力测试必不可少,本文主要叙述了自己在压测过程中遇到的问题,在此分享,希望能帮助大家避免踩坑,提高效率。
1.pod数量
现象:服务器资源充足,tps上不去,检查发现只有一台服务器上有压力
原因:运维负责搭建环境,开发则负责部署代码,由于可能涉及服务器缓存,为避免影响测试,replicas一般默认写的都是1,新手极易忽略,导致压测时也只有1个pod
解决办法:修改replicas值即可
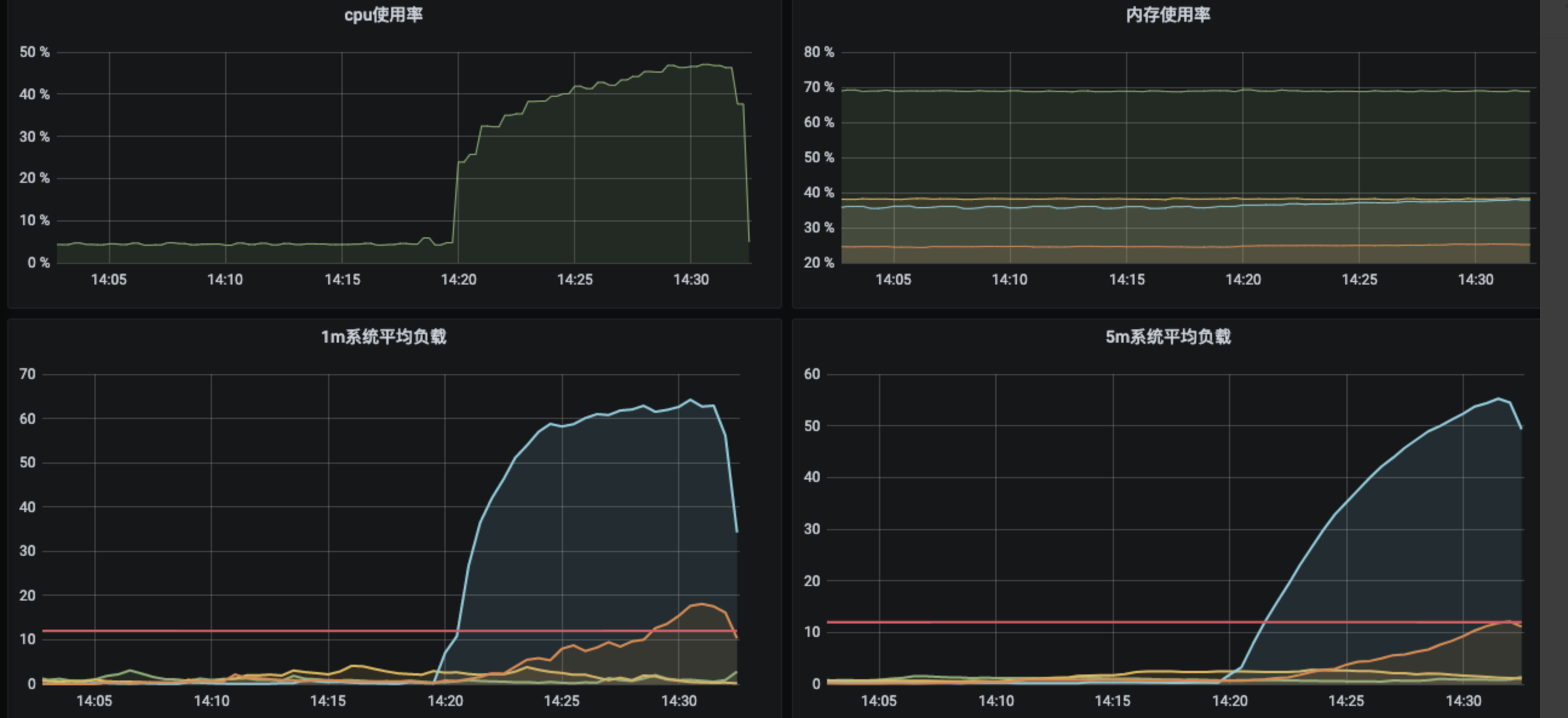
2.施压机能力不足
现象:其他都正常,tps就是达不到期望
可能原因:施压机性能不足,达不到所需并发。可以通过查看施压机cpu,memory,1分钟load,5分钟load等确定,如果cpu超过90%,5分钟load数明显大于cpu核数,基本可以断定施压机到了瓶颈
解决办法:加机器
tips:阿里云PTS工具即使达不到并发,界面上也会显示你设定的并发
3.压测脚本
现象:多接口相比单接口压测时tps并无太大提升(其他条件都满足)
背景:编写压测脚本时往往会模拟真实的用户场景,例如多个接口请求比例不同,有的很高,有的可能很低,这时可以采用if控制器来控制各接口之间的请求比例
原因:if控制器会消耗并发,即一个线程在遇到if控制器时,如果if条件不满足,该线程不会继续往下走,而是停止,如果脚本中有比例很低的接口且排序靠前,则会浪费大量的线程,因此即使并发很大,实际到达服务器的很少,导致tps上不去。测试人员需熟悉工具的使用规则。
4.场景失真
逻辑中大量使用缓存,构造数据较繁琐,偷懒使用单个用户进行压测,若有分库分表、集群等,则会导致只压到了其中一台机器且不会触发一些例如建表,存redis等逻辑,与实际场景大相径庭。
5.pod分配不均
现象:在1的基础下增加pod数,但仍可能出现pod分配不均的问题,导致压力不均衡
解决办法:可联系运维手动调整
6.keep-alive设置
现象:在5的基础上仍出现压力不均衡
原因:请求header的Connection使用了Keep-Alive,即长链接,导致请求全部到了部分服务器上
解决办法:修改Connection值为close
7.连接数
现象:压测结束上线后,发现连接数是测试时的3倍
解决办法:在header中添加x-forwarded-for构造不同的访问ip,(${__Random(0,255). ${__Random(0,255). ${__Random(0,255). ${__Random(0,255)})或者参数化模拟真实的ip访问
8.数据恢复
现象:压测使用了线上数据库,插入了很多数据(数据id和线上最大id有一段间隔),忘记删除数据了,随着时间的推移,线上用户增多,id超过了压测时的id,导致问题(具体记不太清了)
总结:尽量不用线上数据,实在要用,切记恢复数据
9.代码优化方向
- 删除无用的冗余代码
- 减少循环
- 长期不变的参数写成常量,不要写配置文件
- 减少加密操作,实在不行,减少被加密的内容
- 为列表等数据分配大小,不要动态分配,动态分配耗资源
- 提高日志级别