探索数据结构之精髓:单链表解密

文章目录
1. 前言
上一篇文章说过顺序表(线性表的顺序存储)的最大缺点是,在插入和删除操作可能会移动大量元素,去保证元素之间的内存不能有空隙,而这,会导致程序的执行效率变低。
那么如何弥补这个缺点呢?这就涉及到了今天的内容:采用线性表的链式存储来保存数据元素。
线性表的链式存储也非常基础和常用,它不需要使用连续的内存空间。从名字可以得知,所谓链式存储,是通过“链(指针)”建立元素之间的关系,保证元素之间像一条线一样按顺序排列。这样,在插入和删除元素的时候,就不需要为了保证内存空间的连续性,去进行数据元素的大量迁移,只需要修改指向元素的指针即可。
用链式存储实现的线性表叫做链表,链表比顺序表稍复杂一些。它可以具体分为单链表、双链表、循环链表、静态链表这四种。今天先讲解单链表。
2. 单链表的特点
顺序表与单链表保存数据元素的区别如下:

可以看到,左侧顺序表中存储的元素在内存中紧密相连。其中,每个存储数据元素的内存空间被称为一个节点。
而右侧单链表中存储的元素在内存中并不需要紧密相连。在单链表中,每个节点不但用于存放一个数据元素(数据域),还要额外存放一个用于指向后继节点的指针也称后继指针(指针域),最后一个节点的指针域指向 nullptr。
单链表数据存储描述图如下:

在书写单链表相关代码时,有时为了更方便更统一的对链表进行操作,会在单链表的第一个节点之前再增设一个和其他节点类型相同的节点,称为头结点(也称哨兵节点)。
头结点的数据域可以不存储任何信息,也可以存储比如单链表长度等额外信息。头结点的指针域指向第一个节点。注意,头结点始终位于任何其他节点之前,就算我们需要向链表的首部插入节点,那插入的节点也要位于头结点之后。
带头结点的单链表数据存储描述图如下:

那不带头结点的单链表,和带头结点的单链表有什么不同呢?我们来对比一下。
初始化时:不带头结点的单链表(有时也称不带头链表)在初始化时不创建任何节点,而带头结点的单链表(有时也称带头链表)在初始化时要把头结点创建出来(可以把该头结点看成是第 0 个节点)。
实际元素数据的位置:带头结点的单链表中的头节点不存放实际元素数据。头节点之后的下一个节点才开始存放数据。
代码操作:不带头结点的单链表在编写基本操作代码(比如插入、删除等)时更繁琐,往往需要对第一个或者最后一个数据节点进行单独的处理。
在书写单链表的基本操作代码时,多数情况下,我们都会使用带头结点的代码实现方式。
3. 单链表的基础操作
了解整体框架之后,下面我们就来看一看单链表的具体实现代码,包括基本框架、插入、删除、获取以及其它的一些常用操作。
🍑 接口总览
单链表是由一个个的节点组成,所以,我们首先要定义出单个节点。
//单链表中每个节点的定义
template<class T> //T代表数据元素的类型
struct Node
{T _data; //数据域,存放数据元素Node<T>* _next; //指针域,指向下一个同类型(和本节点类型相同)节点
};
然后把单链表相关的类的基本框架实现出来。
//单链表的定义
template<class T>
class LinkList
{
public://构造函数LinkList(); //析构函数~LinkList();
public://在第i个位置插入指定元素ebool ListInsert(int i, const T& e); //优化插入操作bool ListInsert2(int i, const T& e);void InsertNode(Node<T>* cur, const T& e);//删除第i个位置的元素bool ListDelete(int i); //优化删除操作bool ListDelete2(int i);void DeleteNode(Node<T>* pdel);//获得第i个位置的元素值bool GetElem(int i, T& e); //按元素值查找其在单链表中第一次出现的位置int LocateElem(const T& e); //输出单链表中的所有元素void DispList(); //获取单链表的长度int ListLength(); //判断单链表是否为空bool Empty(); //翻转单链表void ReverseList(); private:Node<T>* _head; //头指针(指向链表第一个节点的指针, 如果链表有头结点则指向头结点)int _length; //单链表当前长度(当前有几个元素)
};
🍑 初始化操作
通过构造函数对单链表进行初始化
代码如下:
//通过构造函数对单链表进行初始化
template <class T>
LinkList<T>::LinkList()
{_head = new Node<T>; //先创建一个头结点_head->_next = nullptr;_length = 0; //头结点不计入单链表的长度
}
在上面的 LinkList 类模板的构造函数中,通过 new 创建了一个头结点。
在 main 主函数中,加入如下代码创建一个单链表对象。
LinkList<int> sl;
🍑 插入操作
如果我们想在单链表的第 i 个位置插入指定的元素(也可以称为插入指定的节点),那么只需要找到单链表中的第 i-1 个节点并将新节点插入该节点之后即可。
这里要注意,单链表中的位置编号从 1 开始,对于带头节点的单链表,我们不计算这个头节点的。
单看上面这段话有些绕,我们看一下把元素 a5 插入到单链表第 2 个位置前后对比图:

代码如下:
template<class T>
bool LinkList<T>::ListInsert(int i, const T& e)
{//判断插入位置i是否合法,i的合法值应该是1到length+1之间if (i < 1 || i >(_length + 1)) {cout << "元素" << e << "插入的位置" << i << "不合法,合法的位置是1到" << _length + 1 << "之间" << endl;return false; //插入失败}Node<T>* cur = _head;//整个for循环用于找到第i-1个节点for (int j = 0; j < (i - 1); ++j) //j从0开始,表示cur刚开始指向的是第0个节点(也就是头结点){ cur = cur->_next;}//当循环结束以后, cur指向插入位置的前一个位置Node<T>* node = new Node<T>; //new一个新节点node->_data = e;node->_next = cur->_next; //让新节点链上后续链表,因为cur->_next指向后续的链表节点 cur->_next = node; //让当前位置链上新节点,因为node指向新节点cout << "成功在位置为" << i << "处插入元素" << e << endl; _length++; //实际表长+1 return true; //插入成功
}
上面的代码中,新节点的创建以及修改新老节点的指向,那么这些行对应的节点指向示意图要怎么画呢?
其实很简单,如下图所示:

我们可以给出一组数据测试一下:
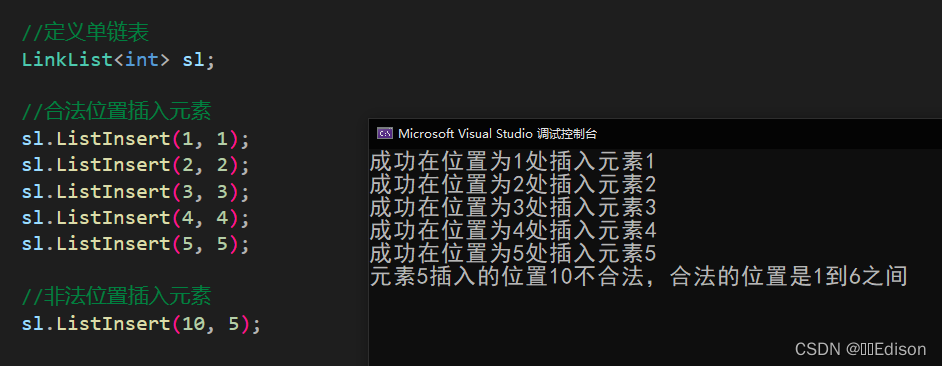
🍅 优化操作
我们分析一下插入操作的时间复杂度。这里只需要关注 for 循环的执行次数与问题规模 n 的关系,问题规模 n 在这里指的是单链表当前长度 _length。
- 如果将元素插入到单链表的开头(位置 1),则 for 循环一次都不会执行,这是最好情况时间复杂度 O(1)。
- 如果将元素插入到单链表的末尾,并且假设单链表中已经有其他元素(非空),则 for 循环会循环 n-1 次,这是最坏情况时间复杂度 O(n)。
- 平均情况时间复杂度其实在顺序表中已经做过很详细的分析,这里很类似,平均情况时间复杂度为 O(n),时间开销主要源于插入位置的寻找。
另外,在实际的应用中,往往也会涉及到向某个已知节点之前插入一个新节点的情况。传统的做法是必须要利用头指针 _head 从前向后找到该已知节点的前趋节点。
在上面的图中,要将 a5 插入到 a2 之前必须要先从前向后找到 a1 节点,算法的平均情况时间复杂度为 O(n)。
那有没有什么更好的方法呢?
- 将新节点 a5 插入到 a2 节点之后(a2 节点是已知的无需查找)。
- 将 a2 和 a5 两个节点的数据域中的元素值互换。
如下图所示:

最终也可以达到将 a5 插入到 a2 之前的效果,而且这样修改后的算法时间复杂度为 O(1)。
代码如下:
//在节点cur之前插入新节点,新节点数据域元素值为e
template<typename T>
void LinkList<T>::InsertNode(Node<T>* cur, const T& e)
{Node<T>* newNode = new Node<T>; //new一个新节点newNode->_next = cur->_next; //让新节点链上cur后面的链表cur->_next = newNode; //让cur链上新节点T tmp = cur->_data; //先保存cur节点中的数据cur->_data = e; //再把cur节点中的数据修改为enewNode->_data = tmp; //最后再把新节点中的数据修改为cur事先保存好的数据_length++; //实际表长+1
}//查找插入位置的节点
template<class T>
bool LinkList<T>::ListInsert2(int i, const T& e)
{//判断插入位置i是否合法,i的合法值应该是1到length+1之间if (i < 1 || i >(_length + 1)) {cout << "元素" << e << "插入的位置" << i << "不合法,合法的位置是1到" << _length + 1 << "之间" << endl;return false; //插入失败}Node<T>* cur = _head;//整个for循环用于找到第i个节点for (int j = 0; j < i; ++j) //j从0开始,表示cur刚开始指向的是第0个节点(也就是头结点){cur = cur->_next;}//当循环结束以后, cur指向插入位置InsertNode(cur, e);return true; //插入成功
}
我们可以给出一组数据测试一下:
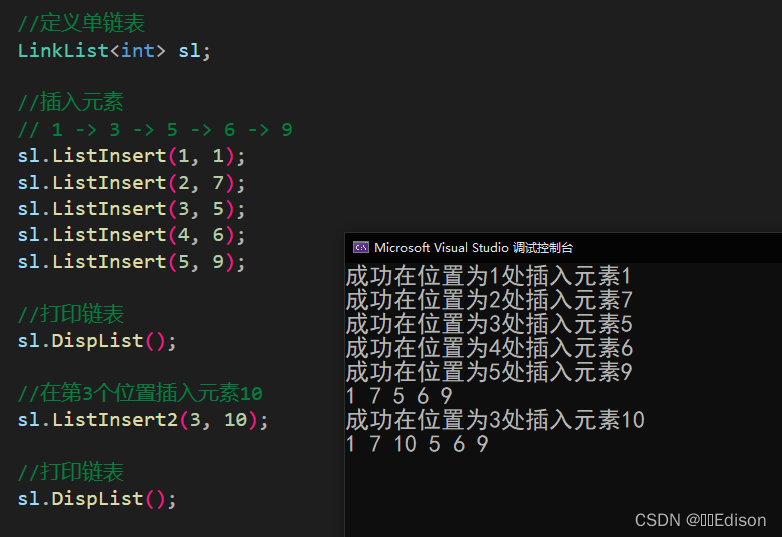
注意,上面这种方法必须提前知道插入位置节点的地址,所以重新写了一个 Insert 函数用来查找 i 位置的节点。
最后,如果需要频繁的向单链表的末尾插入新节点,从算法执行所耗费时间的角度去看,每次用 for 循环从前向后寻找插入位置的做法并不好。
我们可以考虑引入一个表尾指针,这个指针在单链表为空时,会指向头结点,在单链表非空时,要注意始终保持其指向最后一个节点。
这样,通过表尾指针在单链表的末尾插入新节点就会变得非常容易了。
🍑 删除操作
关于删除操作,如果想删除单链表的第 i 个位置的元素,那只需要找到单链表中的第 i-1 个节点,并将其指针域指向第 i+1 个节点,同时释放第 i 个节点所占的内存,就可以了。
代码如下:
//删除第i个位置的元素
template<class T>
bool LinkList<T>::ListDelete(int i)
{if (_length < 1){cout << "当前单链表为空,不能删除任何数据!" << endl;return false;}if (i < 1 || i > _length){cout << "删除的位置" << i << "不合法,合法的位置是1到" << _length << "之间" << endl;return false;}Node<T>* cur = _head; //cur指向头节点//整个for循环用于找到第i-1个节点for (int j = 0; j < (i - 1); ++j) //j从0开始,表示cur刚开始指向的是第0个节点(头结点){cur = cur->_next; //cur会找到当前要删除的位置所代表的节点的前一个节点的位置,比如要删除第2个位置的节点,cur会指向第1个位置(节点)}Node<T>* delNode = cur->_next; //delNode指向待删除的节点cur->_next = delNode->_next; //先让第i-1个节点的next指针指向第i+1个节点cout << "成功删除位置为" << i << "的元素,该元素的值为" << delNode->_data << endl;_length--; //删除节点以后,让实际表长-1delete delNode; //释放节点return true; //删除成功
}
我们可以给出一组数据测试一下:
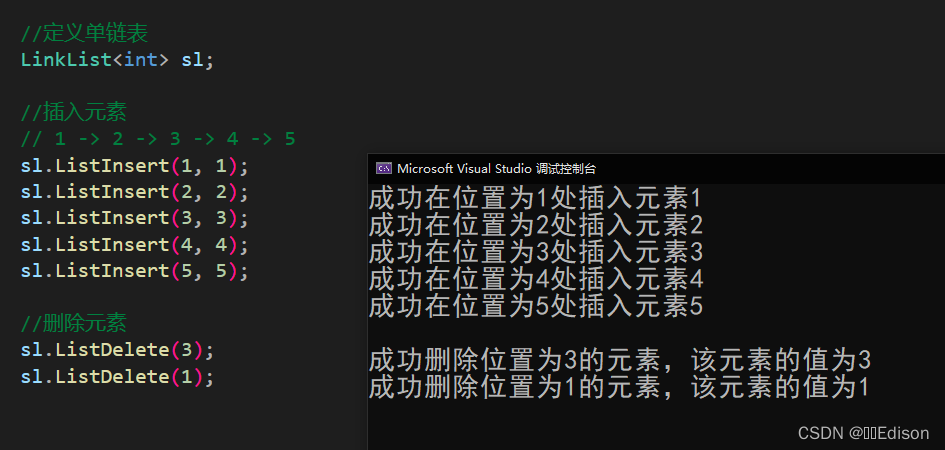
🍅 优化操作
我们分析一下删除操作的时间复杂度。
- 如果删除单链表开头位置的节点,那么 for 循环一次都不会执行,这是最好情况时间复杂度 O(1)。
- 如果删除单链表末尾位置的节点,并且假设单链表中已经有其他元素(非空),则 for 循环会循环 n-1 次,这是最坏情况时间复杂度 O(n)。
- 平均情况时间复杂度在顺序表中也做过很详细的分析,这里很类似,平均情况时间复杂度为 O(n),时间开销主要源于删除位置的寻找。
在实际的应用中,往往我们也会涉及到删除某个指定节点的情况。传统的做法是必须要利用头指针 _head 从前向后找到这个被删除节点的前趋节点。比如要将 a2 删除,就要先从前向后找到 a1 节点,算法的平均情况时间复杂度为 O(n)。
想一想,怎么才能优化这个操作呢?
- 将 a2 后继节点 a3 中数据拷贝到 a2 节点的数据域中。
- 将 a2 节点的指针域指向 a3 的后继节点 a4。
- 释放 a3 节点所占用的内存。
我们看一下这个流程的思路:

这样修改后的算法时间复杂度就是 O(1) 了。
代码如下:
//删除cur所指向的节点
template<class T>
void LinkList<T>::DeleteNode(Node<T>* cur)
{//比如:a1 -> a2 -> a3 -> a4, 现在要删除a2节点Node<T>* pNode = cur->_next;cur->_data = cur->_next->_data; //将a2后继节点a3中数据拷贝到a2节点的数据域中cur->_next = cur->_next->_next; //让a2节点的指针域指向a3的后继节点a4delete pNode; //释放a3节点所占用的内存。_length--; //长度-1
}//删除第i个位置的元素
template<class T>
bool LinkList<T>::ListDelete2(int i)
{if (_length < 1){cout << "当前单链表为空,不能删除任何数据" << endl;return false;}if (i < 1 || i > _length){cout << "删除的位置" << i << "不合法,合法的位置是1到" << _length << "之间" << endl;return false;}Node<T>* cur = _head; //cur指向头节点//整个for循环用于找到第i个节点for (int j = 0; j < i; ++j) //j从0开始,表示cur刚开始指向的是第0个节点(头结点){cur = cur->_next; }//循环结束, cur找到当前要删除的位置所代表的节点DeleteNode(cur);return true; //删除成功
}
我们可以给出一组数据测试一下:
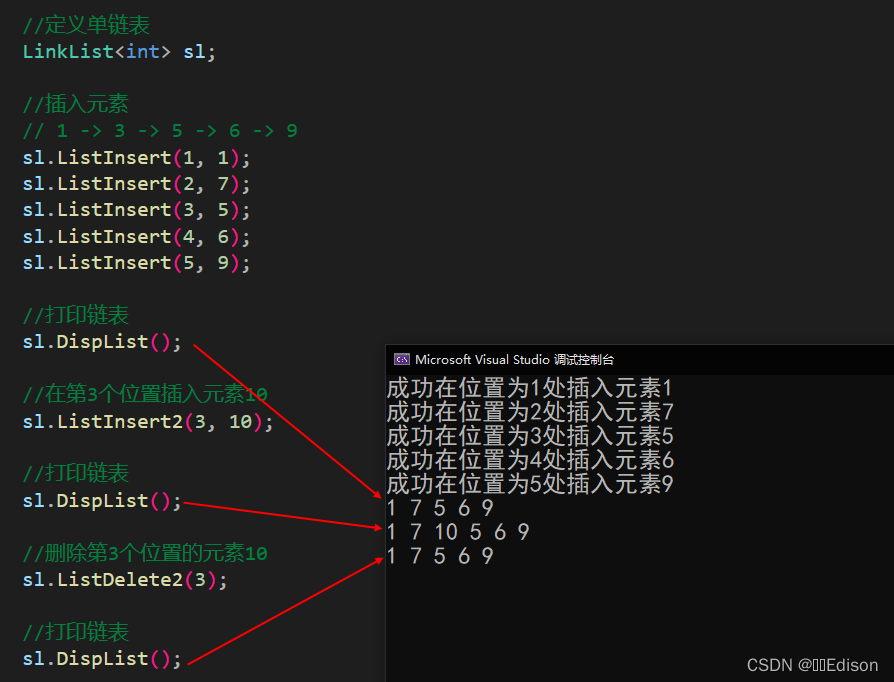
注意,上面这种方法必须提前知道删除位置节点的地址,所以重新写了一个 Delete 函数用来查找删除 i 位置的节点地址。
但要注意,如果要删除的节点正好是单链表的最后一个节点,那就没法用上述快捷高效的方式来编写代码了(代码会报错)。我们还是必须用传统做法,利用头指针找到该将被删除节点的前趋节点,来删除某个指定节点。
🍑 获取元素
在元素获取操作这里,通常分为两种情况:按位置获取和按元素值获取。
🍅 按置查找
首先是按位置获取单链表中的元素值。
代码如下:
//获得第i个位置的元素值
template<class T>
bool LinkList<T>::GetElem(int i, T& e)
{if (_length < 1){cout << "当前单链表为空,不能获取任何数据" << endl;return false;}if (i < 1 || i > _length){cout << "获取元素的位置" << i << "不合法,合法的位置是1到" << _length << "之间" << endl;return false;}Node<T>* cur = _head;for (int j = 0; j < i; ++j){cur = cur->_next;}e = cur->_data;cout << "成功获取位置为" << i << "的元素,该元素的值为" << e << endl;return true;
}
我们可以给出一组数据测试一下:
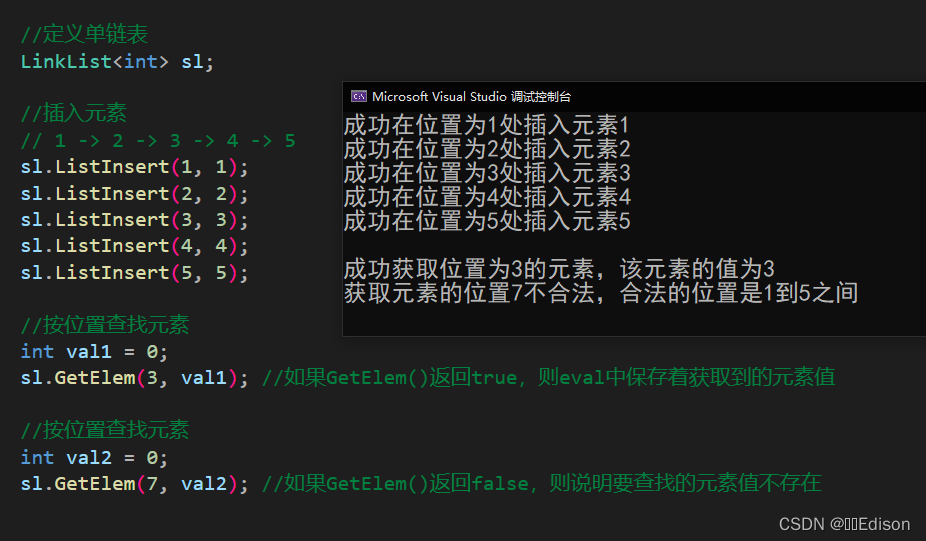
显然,按位置获取单链表元素操作的平均情况时间复杂度为 O(n)。
🍅 按值查找
按元素值查找其在单链表中第一次出现的位置
代码如下:
//按元素值查找其在单链表中第一次出现的位置
template<class T>
int LinkList<T>::LocateElem(const T& e)
{Node<T>* cur = _head; //从头节点的下一个开始依次查找for (int i = 1; i <= _length; ++i){if (cur->_next->_data == e){cout << "值为" << e << "的元素在单链表中第一次出现的位置为" << i << endl;return i;}cur = cur->_next;}cout << "值为" << e << "的元素在单链表中没有找到" << endl;return -1; //返回-1表示查找失败
}
我们可以给出一组数据测试一下:

按元素值查找其在单链表中第一次出现位置操作的平均情况时间复杂度,依旧为 O(n)。
🍑 打印操作
输出单链表中的所有元素
代码如下:
//输出单链表中的所有元素,时间复杂度为O(n)
template<class T>
void LinkList<T>::DispList()
{Node<T>* cur = _head->_next;while (cur != nullptr) //循环遍历整个链表, 直到为空{cout << cur->_data << " ";cur = cur->_next;}cout << endl;
}
我们可以给出一组数据测试一下:
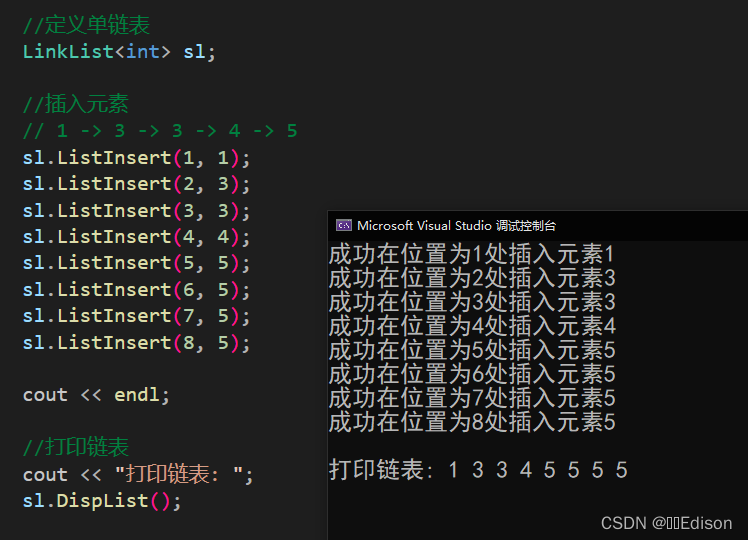
🍑 获取长度
获取单链表的长度
代码如下:
//获取单链表的长度,时间复杂度为O(1)
template<class T>
int LinkList<T>::ListLength()
{return _length; //直接返回长度即可
}
我们可以给出一组数据测试一下:
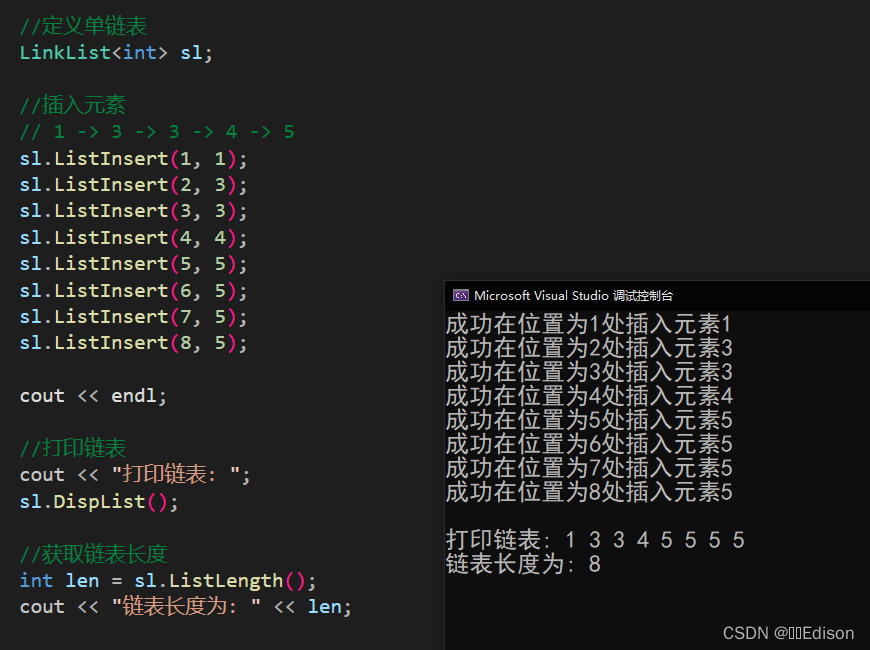
🍑 判空操作
判断单链表是否为空
代码如下:
//判断单链表是否为空,时间复杂度为O(1)
template<class T>
bool LinkList<T>::Empty()
{if (_head->_next == nullptr) //单链表为空(如果是不带头结点的单链表则用if(_head == nullptr)来判断是否为空){return true;}return false;
}
我们可以给出一组数据测试一下:
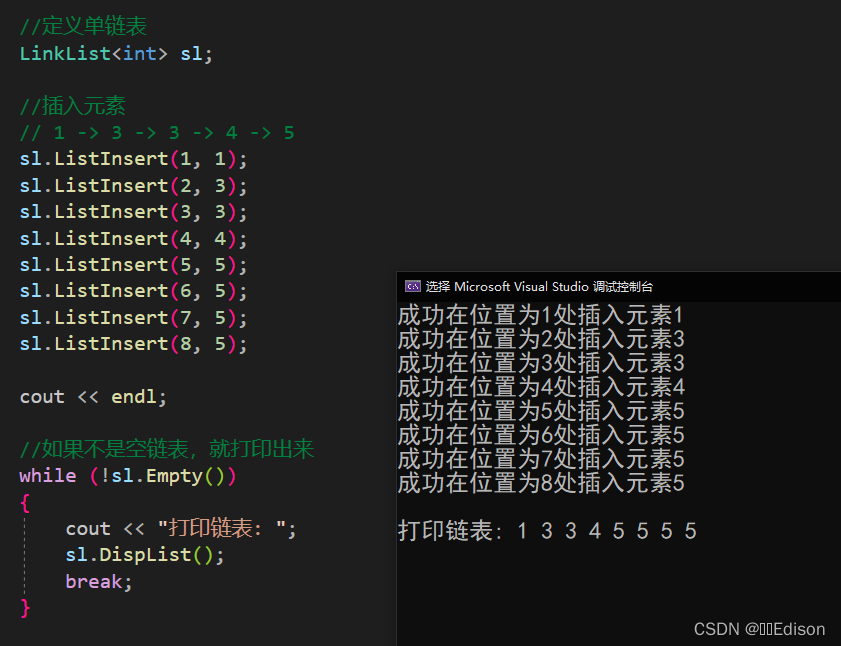
🍑 翻转链表
所谓翻转单链表,就是把单链表中节点的排列顺序反过来。
比如原来节点的排列顺序为 a1、a2、a3、a4,那么翻转后节点的排列顺序就是 a4、a3、a2、a1。
这里要注意的是,并不是针对节点数据域中的数据进行翻转,而是针对整个节点进行翻转(比如原来位于单链表尾部的节点经过翻转后排到了单链表的头部)。
先来思考一下解决思路。
- 把头节点和第一个节点分到一起作为第一部分。
- 把剩余的节点分成一部分。
- 每次从剩余的节点中的最前面拿出一个节点插入到第一部分单链表的首部。
下图展示了翻转单链表的步骤,先将头结点和 a1 分到一起作为第一部分,将 a2、a3、a4 分到一起作为第二部分,然后摘取第二部分的首部节点 a2 插到第一部分的 a1 之前,再摘取第二部分的首部节点 a3 插入到第一部分的 a2 之前……最终就可以实现整个单链表的翻转。
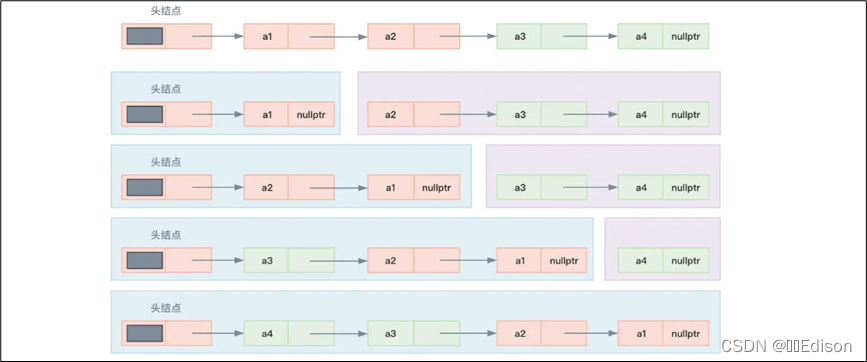
代码如下:
//翻转单链表,时间复杂度为O(n)
template<class T>
void LinkList<T>::ReverseList()
{if (_length <= 1){//如果顺序表中没有元素或者只有一个元素,那么就不用做任何操作return;}//至少有两个节点才会走到这里Node<T>* latterCur = _head->_next->_next; //指向从第二个节点开始的后续节点_head->_next->_next = nullptr; //第一个节点的指针域先置空Node<T>* ptmp;while (latterCur != nullptr){//比如a1、a2、a3、a4共4个节点,第一次执行该循环时的指向看下面代码中的注释ptmp = latterCur; //ptmp代表a2latterCur = latterCur->_next; //现在latterCur指向a3ptmp->_next = _head->_next; //a2指向a1_head->_next = ptmp; //头结点指向a2 }
}
我们可以给出一组数据测试一下:
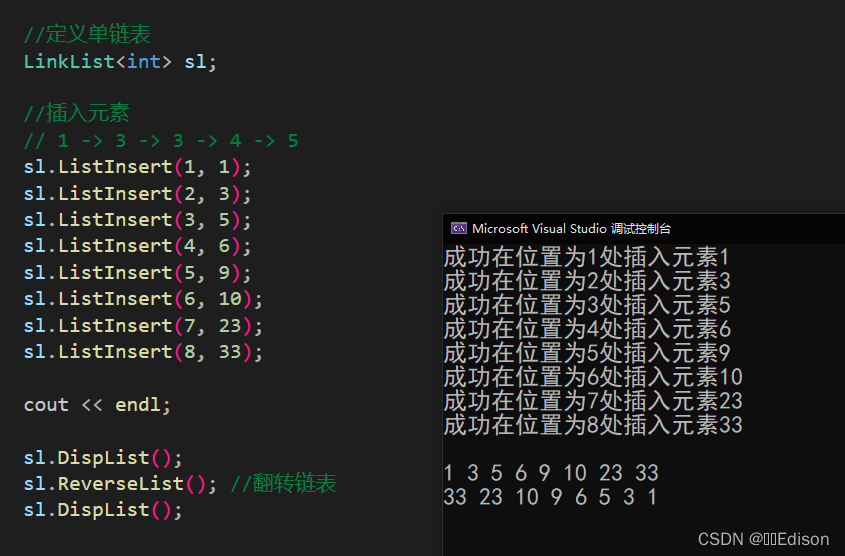
🍑 释放操作
最后,说一下对单链表的释放操作,我们不但要释放单链表中带有数据的节点,也要释放头结点。
析构函数代码如下:
//通过析构函数对单链表进行资源释放,时间复杂度为O(n)
template<class T>
LinkList<T>::~LinkList()
{Node<T>* curNode = _head->_next;Node<T>* ptmp;while (curNode != nullptr) //该循环负责释放数据节点{ptmp = curNode;curNode = curNode->_next;delete ptmp;}delete _head; //释放头结点_head = nullptr; //把头节点置为空_length = 0; //链表长度置为0
}
4. 总结
单链表特点如下:
- 并不需要大片的连续存储空间来存放数据元素,扩容很方便。
- 插入和删除节点非常方便,平均情况时间复杂度为 O(n)。当然,如果不考虑需要预先查找到插入和删除位置只单纯考虑插入和删除动作本身,那么时间复杂度仅为 O(1)。不管怎么说,与数组相比,链表更适合插入、删除操作频繁的场景。
- 存放后继指针要额外消耗存储空间,体现了利用空间换时间来提高算法效率的编程思想。但对于内存紧张的硬件设备,就要考虑单链表是否适合使用了。
- 因为内存空间不连续,无法实现随机访问链表中的元素。要查找某个位置节点中的元素只能从链表的第一个节点开始沿着指针链逐个元素找下去,平均情况时间复杂度为 O(n)。
单链表的操作代码相比于数组更加复杂,实现也更加容易出错,因此写代码时除了要有清晰的逻辑思维之外,写完以后对代码进行测试也是非常重要和必要的——尤其是对边界情况的测试。在这里给出一些代码书写和测试的建议。
- 单链表是后面学习的其他链表的基础,因此应该通过多画图的方式理清代码逻辑,边看图边写自己认为正确的逻辑代码。
- 当链表为空的时候,测试代码能否正常工作。
- 当链表只有一个数据节点时,测试代码能否正常工作。
- 分别测试在处理链表中第一个和最后一个节点时代码能否正常工作。
- 发现程序执行异常并百思不得其解时,通过设置断点对代码进行调试,逐行跟踪并观察代码的执行情况就是必须的解决问题的手段。