归并排序的外排序

归并排序的外排序
我们在数据结构里面实现的排序方式都是在内存里面进行排序,而当我们要对10G的数据放到硬盘里面,要排序,怎么排呢?我们知道计算机的内存相对于外存(硬盘之类的)而言不是很大,我们要在内存使用我们数据结构里面的排序方法显然不太合适,因为内存根本放不下这组数据。
那么我们想到在硬盘里使用归并排序来实现排序10G的数据,实现思想:
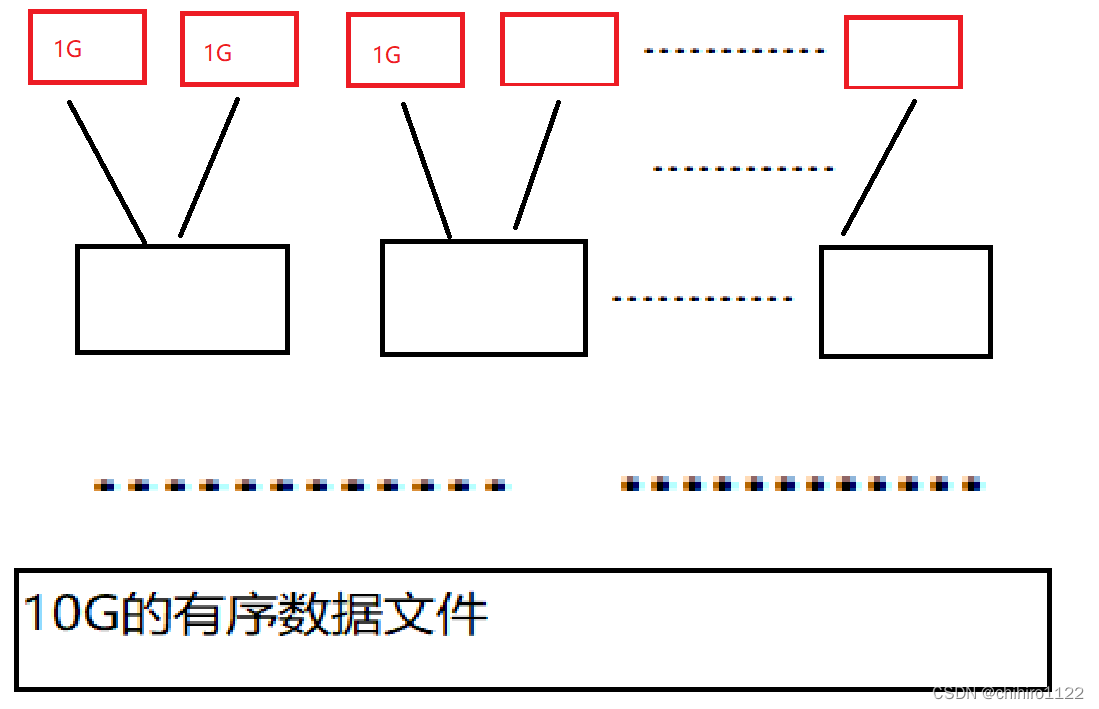
现在我们有10G的数据文件,我们把这个10G的数据文件,分成10个1G的文件,并且让10个1G的文件有序,也就是说,分成10个1G文件之后,就可以用我们原来的排序方法对这个1G的文件进行排序;一次读文件,每一次读1G到内存中用一个数组存放,利用快速排序堆这个数组进行排序,再写到一个文件里面,一次再读下一个文件,同样操作。
直到这10个文件都是有序之后,再在硬盘中对这个10个文件使用归并思想排序,就可以实现10G文件的排序。
那为什么要用归并排序呢?因为其他的排序不能实现,我们在硬盘中读取数据是依次读取数据,而除了归并排序,其他都不是依次遍历数据的,还有用下标访问数据的,文件当然不支持用下标来访问数据。所以此时就只有归并排序比较好实现外存上的排序。

把这个10个1G文件排序好之后,相邻的两个文件为一组依次用归并排序来组合。
1G和1G的文件归并成2G的文件,2G和2G的文件归并成4G的文件·············最后就是8G的和剩下的一个2G的归并10G文件,这个10G的文件就是之前的文件的有序文件。
注:具体的归并排序思想请看这篇文章中的“归并排序”和“归并排序的另一种方式”标题的内容:
数据结构-5(排序)_chihiro1122的博客-CSDN博客
但是归并排序的外排序,至少要有 O(N) 的空间复杂度,因为至少要归并一次,到新的空白里,而且磁盘相比于缓存的速度是很慢的,我们在磁盘上进行操作,这个速度会很慢。
在磁盘上海量的数据一般会是在文件中, 那么我们在磁盘上进行归并排序一般就是在文件中进行归并,如果都借助磁盘上去归并排序,那么会很慢。
我们可以把文件分为多分,一般是看内存能存多少数据,假设有10G文件,那么内存可以容纳1G内容,那么我就把这个文件分为十份:

然后再像上述一样去归并:

也就是说,把大文件平均分割为n个小文件,保证每一份小文件都可以加载到内存,那么就可以把每一个小文件加载到内存中,使用快排来把被一个小文件取出来排成有序,这是归并到大文件中的先决条件,然后再访问到小文件中,在把每一个小文件中数据,归并到大文件中去。
但是有一个问题,有n个小文件,那么取名字该如何取呢?具体该如何实现呢?我们可以这样做:
我们就直接读取大文件中的数据,读取到 EOF 就停止,也就是说直接把大文件中的数据读写完,但是我在读写的时候,假设我的每一个小文件中有10个数据,那么我在这个读大文件这个循环中,按照10个数据来进行读写,也就是说,我每读10个数据,我就对这个数据进行快速排序。那么整体实现就是,直接把大文件在大文件内部直接按10个数据大小分为多个区间,然后每一次取出就把这个区间快排为有序区间,然后再继续归并操作。
如图所示:
然后再归并。

如上图,我们就把 大文件中 以 10 个数据为小区间的 数据 读写到一个一个小文件中去了。
因为小文件要取文件名,那么我们使用sprintf()函数来写到字符串中,:
如上图所示,我们把文件名写到这个字符串数组中去,然后这个字符串数组就可以作为,open函数打开文件的文件名:
![]()
那么写入文件中,文件中只有字符,那么我们用int写入就会在编译就会乱码,这时我们需要把这个int类型转化为字符串,或者使用fpirntf()函数,这里我们就使用fprintf()函数,比较方便:

这个使用,我们的一个小文件就排序好了,也写入了,那么这个是,我们需要排序写入下一个小文件,这时我们需要关闭这个文件对象,然后把 i 置为 0 ,这样才能继续在大文件中读 10 个数据;

但是上述方法有一个bug,就是如果我先放10 个数据,那么此时num 就是这个小区间的第 10个位置,但是我们上述的循环写的是,if 放数据,else 来排序的顺序,那么每一次读数据就有一个依次循环是 拿来 排序的,但是这一次多余的排序循环中又是读数据的,这就导致每一次分割小区间都会有一个数据没有读写排序上,所以我们要这样处理:
就是在 if 中先只取 9 个数据,然后 else 排序之前,我先把第10个数据 取出 放到数组中去,再继续排序:
上述就是把大文件分割为有序的小文件,然后就是对这些个小文件进行 归并排序到大文件中:
为了考虑文件取名字问题,我们这样进行归并排序:
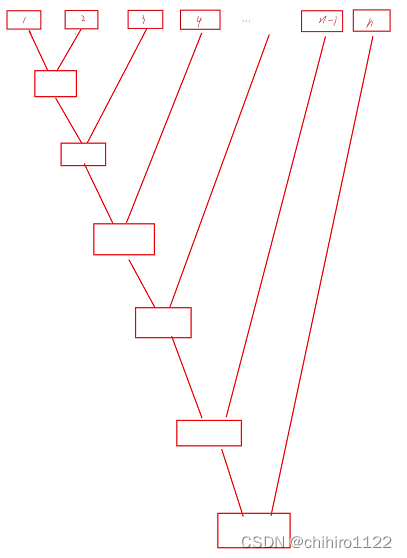
我们来先是实现一个函数,这个函数把 小文件中的两个文件中数据读取到 一个新文件中去,然后实现单趟的归并排序:
void _MergeFile(const char* file1, const char* file2, const char* mfile)
{FILE* font1 = fopen(file1, "r");if (font1 == NULL){printf("打开文件失败\\n");exit(-1);}FILE* font2 = fopen(file2, "r");if (font2 == NULL){printf("打开文件失败\\n");exit(-1);}FILE* fin = fopen(mfile, "w");if (fin == NULL){printf("打开文件失败\\n");exit(-1);}int num1, num2;int ret1 = fsacnf(font1, "%d\\n", &num1) != EOF;int ret2 = fsacnf(font1, "%d\\n", &num2) != EOF;while (ret1 != EOF && ret2 != EOF){// 谁小就把这个数据往文件中写if (num1 < num2){// 谁写入文件谁就 继续往下读fprintf(fin, "&d\\n", num1);ret1 = fsacnf(font1, "%d\\n", &num1);}else{fprintf(fin, "%d\\n", num2);ret2 = fsacnf(font1, "%d\\n", &num2);}}// 不知道哪一个文件没有读完,那就两个都写一遍,没有的会自动跳出循环while (fsacnf(font1, "%d\\n", &num1) != EOF){fpirntf(fin, "%d\\n", num1);}while (fsacnf(font2, "%d\\n", &num1) != EOF){fpirntf(fin, "%d\\n", num2);}fclose(font1);fclose(font2);fclose(fin);
}然后实现总体的归并排序:
void MergeSortFile(const char* file)
{FILE* fout = fopen(file, "r");if (fout == NULL){printf("打开文件失败\\n");exit(-1);}// 把大文件中的数据 分成一段一段的 数据,把每一段的数据写入一个个小文件中int n = 10;int a[10];int i = 0;int num = 0;char subfile[20];int filei = 0;// 初始化memset(a, 0, sizeof(int) * n);// 假设大文件中的每一个数据 通过 \\n 来区分// 读数据while (fsacnf(fout, "%d\\n", &num) != EOF){if (i < n - 1){a[i++] = num;}else{a[i] = num;// 快速排序 先对每一个小文件进行排序QuickSort(a, 0, n - 1);// 在 sub文件夹下写文件sprintf(subfile, "sub//%d", filei++);FILE* fin = fopen(subfile, "w");if (fin == NULL){printf("打开文件失败\\n");exit(-1);}for (int i = 0; i < n; i++){fprintf(fin, "%d\\n", a[i]);}fclose(fin);i = 0;memset(a, 0, sizeof(int) * n);}}// 利用互相归并到文件,实现整体有序char mfile[100] = "12";char file1[100] = "1";char file2[100] = "2";for (int i = 0; i <= n; i++){// 读取file1 和file2 归并出 mfile_MergeFile(file1, file2, mfile);strcpy(file1, mfile);spirntf(file2, "%d", i + 1);sprintf(mfile, "%s%d", mfile, i + 1);}fclose(fout);
}上述就是实现了 归并排序在 文件当中的使用。