第四章(1):词向量定义与意义

第四章(1):词向量定义与意义

目录
- 第四章(1):词向量定义与意义
- 前言
- 1. 词的表示
-
- 1.1 离散表示
-
- 1.1.1 One-Hot独热编码
- 1.1.2 ngram特征表示
- 1.2 分布式表示
- 2. 意义
前言
在自然语言处理的领域中,每个单词都可以被表示为一个向量,这些向量叫做“词向量”。换句话说,每个单词都可以被用数字表示,而这些数字可以被用于机器学习模型的训练之中。这样就可以大幅缩小所需要的存储空间,同时也可以提高机器学习模型的速度和表现。
1. 词的表示
在自然语言处理任务中,首先需要考虑词如何在计算机中表示。通常,有两种表示方式:one-hot representation和distribution representation。
1.1 离散表示
离散表示的实现方法主要有两种,分别是One-Hot独热编码和ngram特征表示。
1.1.1 One-Hot独热编码
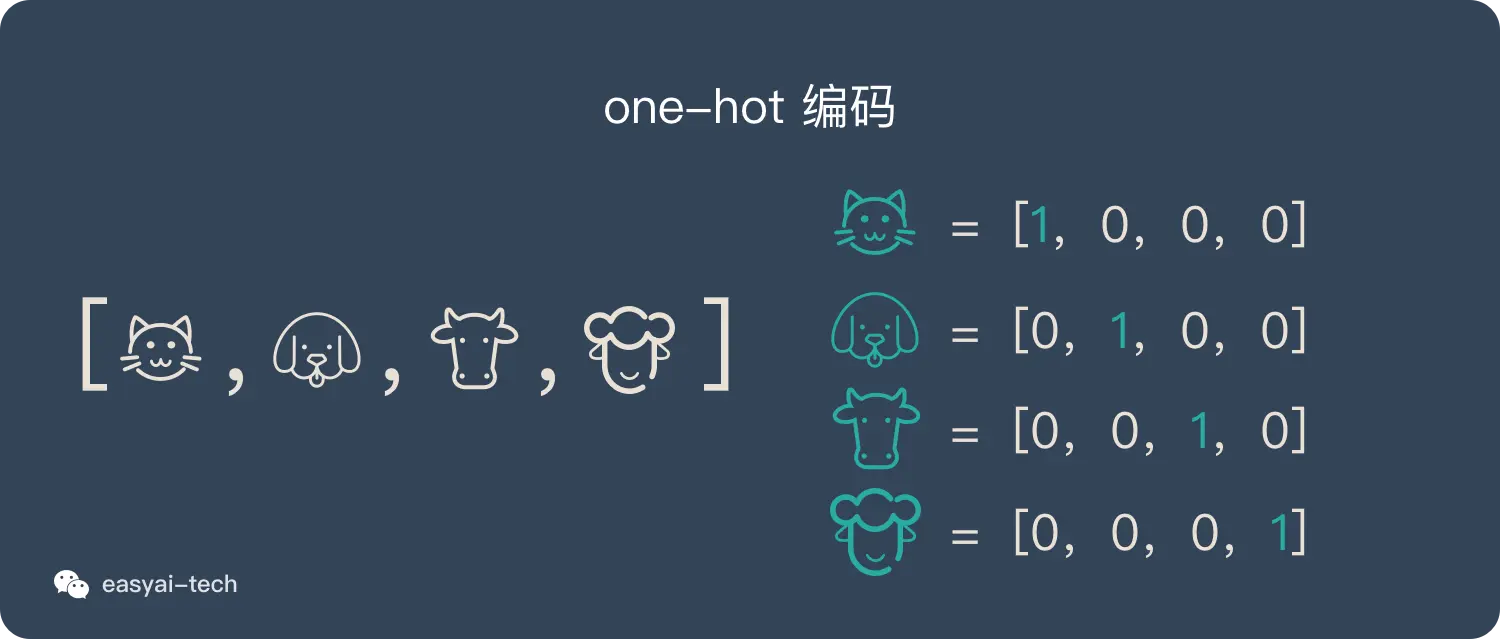
One-Hot独热编码是一种最简单的离散表示方法,也是最为常见的一种方法。它采用词表中每个词的索引作为二进制编码的位置,只有该位置上取值为1,其他位置的取值都为0。对于包含n个不同词语的词表,每个词语的离散表示的向量维数就是n。
例如,对于如下的词表:
苹果,橘子,芒果,葡萄
我们可以将其转化为如下的离散表示向量:
苹果:[1,0,0,0]
橘子:[0,1,0,0]
芒果:[0,0,1,0]
葡萄:[0,0,0,1]
通过One-Hot独热编码,我们可以得到每个词语的固定长度的离散向量,同时也可以最大限度的避免同一个词语出现多次的问题。但是这种方法也存在着一些问题,比如向量维度较高,导致存储空间的占用较大,同时也无法解决语义相似的词语之间的距离问题。
如下是一个动漫表示,生动形象~
1.1.2 ngram特征表示
ngram特征表示是一种基于n元语法的离散表示方法,它主要是基于一个句子中不同的词语之间的关系来进行的。具体来说,它是将一个句子中所有的不同词语按顺序排列,然后选取不同长度的组合作为不同的特征。
假设我们有一个包含以下四个句子的文本:
- 我们明天一起去看电影吧。
- 今天的天气真好,适合出去玩。
- 这家餐厅的菜很好吃,服务也很棒。
- 最近公司的业绩不太理想,需要加强市场营销。
我们可以使用基于词语的ngram特征表示方法,将每个句子表示成一个向量。假设我们使用二元词语级别的ngram特征表示,那么对于上述四个句子,可以得到如下的特征向量:
| 我们 明天 | 明天 一起 | 一起 去 | 去 看 | 看 电影 | 今天 天气 | 天气 真好 | 真好 适合 | 适合 出去 | 出去 玩 | 这家 餐厅 | 餐厅 的 | 的 菜 | 菜 很 | 很 好吃 | 好吃 服务 | 服务 也 | 也 很 | 很 棒 | 最近 公司 | 公司 的 | 的 业绩 | 业绩 不太 | 不太 理想 | 理想 需要 | 需要 加强 | 加强 市场 | 市场 营销 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 句子1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 句子2 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 句子3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 句子4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
在这个特征向量中,每一行代表一个句子,每一列代表一个二元词语。如果在某个句子中,存在某个二元词语,则对应的位置的值为1,否则为0。
通过基于词语的ngram特征表示,我们可以得到文本中不同词语之间的语义信息,同时也可以减少语法结构对文本表示的影响,从而更好地表达文本的重要信息。
1.2 分布式表示
词向量的分布式表示(Distributed Representation)是一种将单词表示为实数向量的方法。相对于传统的局部表示方法(如独热编码),分布式表示将单词的语义信息分散地存储在向量的各个维度中,从而实现了高效的语义处理。这种方法最早由Yoshua Bengio等人提出,后来通过神经网络模型的发展得到广泛应用。
具体地,分布式表示是将每个单词表示为一个实数向量,其中向量中每个维度都代表单词的一个特定语义。例如,在使用神经网络进行词向量训练时,我们可以选定一个窗口大小,根据输入单词周围的上下文预测该单词的向量表示。这样,语义相近的单词就会在向量空间中聚集在一起。通过这种方式,我们可以在向量空间中计算单词之间的距离和相似度,进而实现一些自然语言处理任务。
分布式表示方法已经被广泛应用于自然语言处理领域,尤其是在词向量表示和语言模型方面。目前,一些预训练的词向量模型(如word2vec、GloVe和Bert等)已经成为自然语言处理领域的重要工具。
后文将具体描述。
2. 意义
词向量是将文本中的每个单词表示为一个实数向量,它可以将自然语言处理中的文本信息转化为可以进行数学运算的形式,为自然语言处理任务提供了新的思路和方法。词向量的意义主要体现在以下几个方面:
-
表示语义信息:词向量能够将单词嵌入到低维空间中,使得具有相似语义的单词在向量空间中距离较近,从而为自然语言处理任务提供了更加有效的表示方式。例如,可以使用词向量进行词汇替换、同义词判定、情感分析等任务。
-
降低维度灾难:传统的文本表示方法往往需要采用高维稀疏的独热编码或者词袋模型,这种方法会导致维度灾难的问题,即当词表很大时,特征向量的维度会非常高,导致稀疏性问题和计算开销问题。而词向量方法则可以将单词嵌入到低维空间中,降低了特征向量的维度,解决了维度灾难的问题。
-
支持计算语义相似度:词向量支持通过向量空间距离计算语义相似度,可以进行词汇替换、短语组合等操作,从而拓展了自然语言处理的应用范围。
-
帮助解决稀疏性问题:在文本分类、聚类等任务中,传统的方法往往需要处理高维稀疏的特征向量,这会导致数据稀疏、模型容易过拟合等问题,而使用词向量则可以将文本表示为密集向量,解决稀疏性问题,提高模型性能。
综上所述,词向量作为自然语言处理领域中的一项重要技术,具有表示语义信息、降低维度灾难、支持计算语义相似度和帮助解决稀疏性问题等意义
参考
什么是词向量?(NPL入门) - 腾讯云开发者社区-腾讯云 (tencent.com)