人口普查数据集独热编码转换

人口普查数据集独热编码转换
描述
在机器学习中,数据的表示方式对于模型算法的性能影响很大,寻找数据最佳表示的过程被称为“特征工程”,在实际应用中许多特征并非连续的数值,比如国籍、学历、性别、肤色等,这些特征被称为离散特征(或分类特征),对于多数模型来说,需要预先对离散特征进行数字编码,独热编码(one-hot编码)是最常用的离散特征编码方式。
本任务的实践内容包括:
1、对人口普查数据集(adult)进行独热编码转换
2、对编码后的数据进行缩放预处理
3、建立逻辑回归分类模型并评估
源码下载
环境
-
操作系统:Windows 10、Ubuntu18.04
-
工具软件:Anaconda3 2019、Python3.7
-
硬件环境:无特殊要求
-
依赖库列表
scikit-learn 0.24.2 pandas 1.1.5 Ipython 7.16.3
分析
本任务采用人口普查数据集(adult),该数据集由美国1994年人口普查数据库抽取而来,可以用来预测居民收入是否超过50K$/year。该数据集包含年龄、工种、学历、职业、人种等14个特征和1个标签列(收入),14个特征中有多个分类离散特征,需要进行编码转换。
Scikit-learn和Pandas都提供了独热编码功能,Scikit-learn通过LabelEncoder和OneHotEncoder类实现,Pandas通过get_dummies函数实现。
本任务基于adult数据集建立收入预测模型,预测居民收入是否超过50K,这是一个二分类问题,任务涉及以下几个环节:
A)加载、观察adult数据
B)转换独热编码
C)抽取特征数据与标签数据
D)数据缩放预处理
E)拆分测试集与训练集
F)建立逻辑回归模型并评估
实施
1、加载、观察adult数据
import pandas as pd
from IPython.display import display # display函数可以更美观地显示数据# 读入数据集(原数据集中没有列名,我们为其加上)
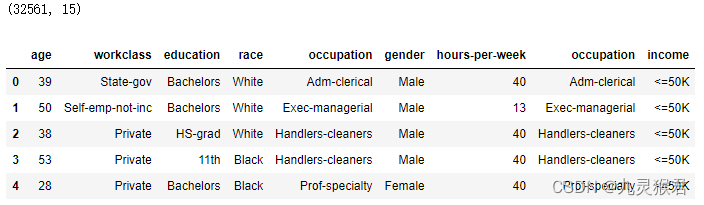
data = pd.read_csv("../dataset/adult.data",names=['age', 'workclass', 'fnlwgt', 'education', 'education-num','marital-status', 'occupation', 'relationship', 'race', 'gender','capital-gain', 'capital-loss', 'hours-per-week', 'native-country','income'])print(data.shape) # 32561个样本,14个特征+1个标签(收入)# 简单查看其中几列(便于显示)
data_t = data[['age', 'workclass', 'education', 'race', 'occupation', 'gender', 'hours-per-week','occupation', 'income']]display(data_t.head()) # 查看前5行
结果如下:
2、转换独热编码
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler# 将离散特征转为独热编码(该函数只转换非数字类型的列)
data = pd.get_dummies(data)
display(data) # 最后两列为标签
输出结果:
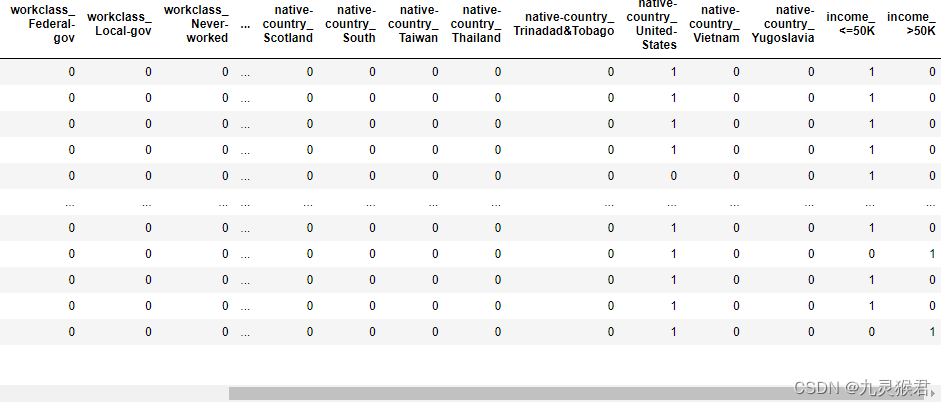
转化后,最后两列为标签,前面为特征列。
3、抽取特征与标签数据,建模并评估
X = data.iloc[:,0:-2].values # 取出特征数据(不包括最后两列)
y= data.iloc[:,-1].values # 取标签数据X = StandardScaler().fit_transform(X) # 使用StandardScaler进行数据缩放
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0) # 拆分数据model = LogisticRegression().fit(X_train, y_train) # 建里LR分类模型
score = model.score(X_test, y_test) # 评估模型
print(score)
结果如下:
分类准确率为85%。