深度学习 - 40. N-Gram 采样与 Session 数据获取 For EGES

目录
一.引言
二.订单数据预处理
1.数据样例
2.订单数据处理
3.用户 Session 构建
三.构造 sku_id 游走序列
1.获取完整 Session List
2.统计 sku_id 转移词频
3.构建 sku_id 图
4.游走构造 sku 序列
四.商品侧信息预处理
1.读取商品信息
2.Left Join 匹配侧信息
3.Id2Index 构建
五.基于 Ngram 与 Negative Sample 的样本生成
1.自定义 Ngram 样本生成
2.keras.preprocessing.sequence.skipgrams 样本生成
3.tf.random.log_uniform_candidate_sampler 采样负样本
六.总结
一.引言
上一篇文章 EGES 与推荐系统用户冷启动 一文中我们针对 EGES 论文中提到的一些关键要素进行了分析,在 Word2vec 的基础上,其创新点主要分为两个部分:
• 通过 Session 构建用户序列代替
• 在原有数据中引入 Side Info 侧信息提高 Emb 表达能力
本文将主要基于订单数据介绍 EGES 模型的数据准备工作,后续会通过 Keras 基于该数据进行后续的 EGES 模型构建。
二.订单数据预处理
1.数据样例
数据处理前,首先看下数据的原始样式:
- 订单数据
user_id,sku_id,action_time,module_id,type
937922,357022,2018-02-04 08:28:15,8107857,1
937922,73,2018-02-04 08:27:07,8107857,1
937922,29583,2018-02-04 08:26:31,8107857,1
937922,108763,2018-02-04 08:26:10,8107857,1
1369473,331139,2018-02-03 21:55:49,3712240,1
1330642,69016,2018-02-01 12:47:23,1844129,1
1330642,211690,2018-02-01 12:48:50,1844129,1
1330642,322692,2018-02-01 12:48:15,1844129,1
1330642,19643,2018-02-01 12:47:55,1844129,1这里原始数据包含 user_id、sku_id、action_time、module_id 以及 type,后续我们主要关注
• sku_id
商品id,可以理解为后续 word2vec 里的 word,因为我们要根据 sku_id 构建用户行为序列
• action_time
订单时间,主要用于判定不同 Session 之间的间隔,从而划分不同的 Session 与 Seq
• type
行为类型,例如点击、购买等等,该值后续应用于 Session 的判断,当 type 表示付款下单时,我们可以认为是一次购买行为的结束,即 Session 的分割点
- 商品信息
sku_id,brand,shop_id,cate,market_time
226519,6302,2399,79,2015-07-02 11:19:04.0
63114,9167,4216,79,2016-07-08 14:29:12.0
372345,2748,7125,79,2016-04-07 16:21:40.0
366931,2698,10252,79,2016-09-11 15:00:22.0
174979,8368,871,79,2017-12-06 17:56:17.0
295436,6302,2399,79,2015-07-02 11:19:04.0
282251,6302,2399,79,2015-07-02 11:19:04.0
146764,6302,2399,79,2015-07-02 11:19:04.0
130851,6302,2399,79,2015-07-02 11:19:04.0这里包含 sku_id、brand、shop_id、cate 与 market_time,除去 market_time,brand-品牌、shop_id-店铺以及 cate-商品标签 都可以视作是商品的 SideInfo 即 EGES 要引入的商品侧信息,所以后续除了通过订单数据获取用户的游走序列外,我们还需要为目标词匹配其 Side Info。
2.订单数据处理
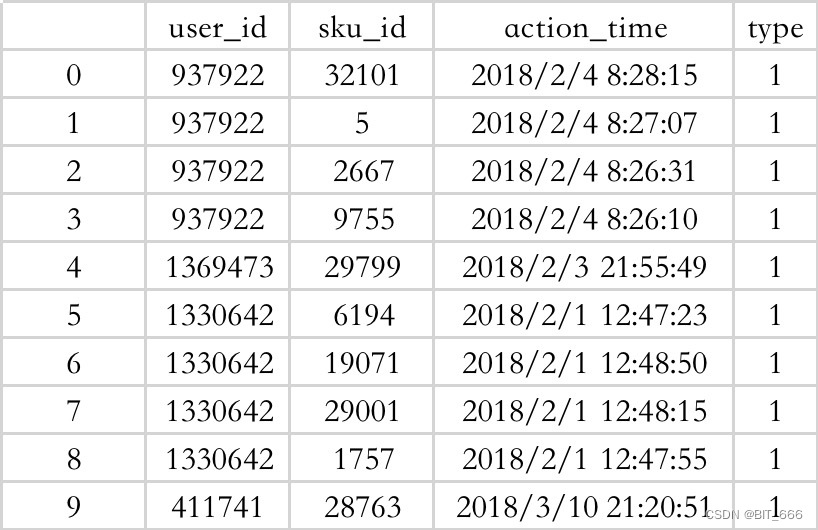
# dropna() 函数的作用是去除读入的数据中(DataFrame)含有NaN的行,这里 axis 默认为0即删除含 Nan 的行# parse_dates 解析时间列 处理后包含 user_id sku_id action_time type 信息action_data = pd.read_csv(args.data_path + 'action_head.csv', parse_dates=['action_time']) \\.drop('module_id', axis=1).dropna()# 获取全部 sku_id 销售品编码,此处共 34048 个 Skuall_skus = action_data['sku_id'].unique()sku_num = len(list(all_skus))all_skus = pd.DataFrame({'sku_id': list(all_skus)})# 将 sku 编码到 0-34047 的 idsku_lbe = LabelEncoder()all_skus['sku_id'] = sku_lbe.fit_transform(all_skus['sku_id'])action_data['sku_id'] = sku_lbe.transform(action_data['sku_id'])print('make session list\\n')订单数据逻辑比较清晰:
A.读取 csv 文件,解析订单 action_time,去除无关列 module_id 并过滤掉包含 Nan 的异常数据
B.对 sku_id 去重获取当前订单中所有 sku_id 的去重集合
C.通过 LabelEncoder 对 sku_id 编码并更新到对应的 DataFrame 列中
经过这一步数据处理,原始订单数据存储到 Python 的 DataFrame 中,其样式为:
Tips:
论文中还给出更为细节的异常数据过滤方法:
• 去除非置信正样本
点击后的停留时间小于1秒,则该点击可能是无意的,需要删除,这里其实针对的是用户误点击或者误触造成的不置信的正样本。
• 过度活跃样本
淘宝有一些 "过度活跃" 的用户,他们实际上是垃圾用户。根据我们在淘宝的长期观察,如果一个用户在不到 3 个月的时间里购买了1000 件商品或者总点击量超过 3500 次,那么这个用户很有可能是一个垃圾用户。
• 高频更新样本
淘宝上的零售商不断更新商品的详细信息。在极端的情况下,一件商品在经过长时间的更新后,在淘宝上的同一个标识符可能会变成完全不同的商品。因此,我们删除了同一个标识下不断更新的 Item,以免其语义变化对模型推理引入噪声。
上述三个条件需要端上记录更多点击时长或者商品的更新历史等,大家在实际应用场景中也可以参考并加入数据清洗的流程中。
3.用户 Session 构建
基于上面生成的订单信息 DF 我们可以结合 type 和 action_time 截取用户行为 Session,实战中 Alibaba 的 Session Gap 推荐为 1h,除此之外还需要结合 use_type 即可用订单类型:
session_list = get_session(action_data, use_type=[1, 2, 3, 5])下面详细看下 get_session 方法的实现:
def get_session(action_data, use_type=None):if use_type is None:use_type = [1, 2, 3, 5]# 选择指定 use_typeaction_data = action_data[action_data['type'].isin(use_type)]# 由低到高升序排列,按 user 用户、action_time 行为时间排列action_data = action_data.sort_values(by=['user_id', 'action_time'], ascending=True)# 按 user_id 聚合为 listgroup_action_data = action_data.groupby('user_id').agg(list)# 根据 cut_session 函数按行处理session_list = group_action_data.apply(cnt_session, axis=1)return session_list.to_numpy()这里逻辑也很清晰:
A.首先过滤原始数据中不符合的类型的 type 对应的订单
B.根据 user_id 和 action_time 为用户构建时序订单
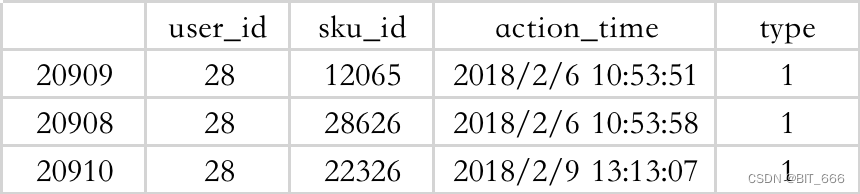
C.将 user_id 的行为聚合为 list 供后续处理

D.通过 cut_session 方法切分生成 Session
def cnt_session(data, time_cut=30, cut_type=2):# 商品、时间、类型列表sku_list = data['sku_id']time_list = data['action_time']type_list = data['type']# 构建 Sessionsession = []tmp_session = []# 遍历每一个 Item 即 sku_idfor i, item in enumerate(sku_list):# A.cut_type=2 即下单 B.Session Gap > 30min C.最后一个行为if type_list[i] == cut_type \\or (i < len(sku_list) - 1 and (time_list[i + 1] - time_list[i]).seconds / 60 > time_cut) \\or i == len(sku_list) - 1:tmp_session.append(item)session.append(tmp_session)tmp_session = []else:tmp_session.append(item)return session这里对每个用户的 sku_id list 进行处理,其中设置了 3 个截断条件用于结束 session 并添加到 session 候选集:
• cut_type=2 当前订单行为为下单
• time_cut > 30 前后订单超过预定阈值
• last_order 用户 list 最后一个订单

Tips:
通过上面的聚合与处理我们将用户原始订单信息生成为每一个用户多个 Session 的情况,论文中使用 Session 也基于如下考虑:
• 计算用户完整历史行为的计算与空间成本太高
• 用户的兴趣会随着时间的推移而变化
• 不同的 Session 内用户的兴趣可能更加相近,从而强化 item 之间的相似性
三.构造 sku_id 游走序列
通过前面划分好的 Session,后续我们就可以基于 Session 内的 item 商品序列构建 Graph 实现 GraphEmbedding 前置的游走工作,下面提供 RandomWalk 随机游走和 Node2vec 两种游走方式的实现。
1.获取完整 Session List
session_list_all = []for item_list in session_list:for session in item_list:if len(session) > 1:session_list_all.append(session)遍历全部 Session,保留 Session 内 Item 数量大于 1 的会话。
2.统计 sku_id 转移词频
node_pair = dict()for session in session_list_all:# 针对 (t,v) 统计转移频率for i in range(1, len(session)):if (session[i - 1], session[i]) not in node_pair.keys():node_pair[(session[i - 1], session[i])] = 1else:node_pair[(session[i - 1], session[i])] += 1这里对 Session 内每个 (Node, Node) 进行词频统计。
# 出节点、入节点 (t, v): weightin_node_list = list(map(lambda x: x[0], list(node_pair.keys())))out_node_list = list(map(lambda x: x[1], list(node_pair.keys())))weight_list = list(node_pair.values())graph_df = pd.DataFrame({'in_node': in_node_list, 'out_node': out_node_list, 'weight': weight_list})graph_df.to_csv('./data_cache/graph.csv', sep=' ', index=False, header=False)基于上面的词频生成节点转移表格,相当于生成节点转移的带权图的原始数据,weight 权重以节点出现的频次为准。
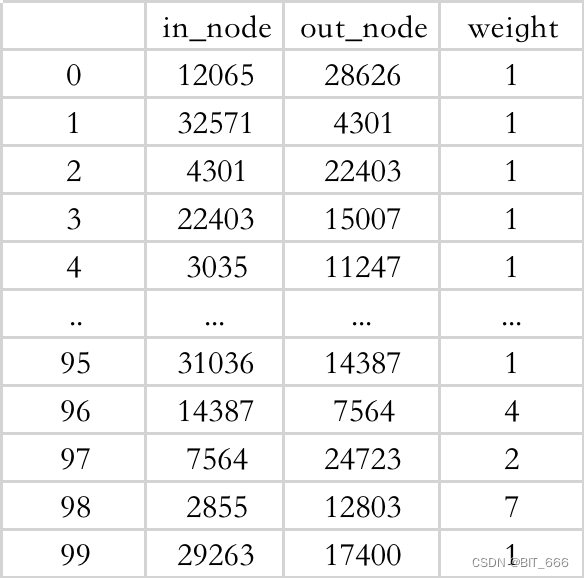
为了方便后续快速使用,这里将原始的带权图信息存储至 csv,后续可以直接加载避免多次数据预处理。
3.构建 sku_id 图
# networkx 读取生成带权图G = nx.read_edgelist('./data_cache/graph.csv', create_using=nx.DiGraph(), nodetype=None, data=[('weight', int)])walker = RandomWalker(G, p=args.p, q=args.q)# 生成 Alias 转移概率表print("Preprocess transition probs...")walker.preprocess_transition_probs()这里使用 networkx 读取上面的数据生成带权图,再定义 RandomWalker 类,其实现如下:
class RandomWalker:def __init__(self, G, p=1, q=1):""":param G::param p: Return parameter,controls the likelihood of immediately revisiting a node in the walk.:param q: In-out parameter,allows the search to differentiate between “inward” and “outward” nodes"""self.G = Gself.p = pself.q = qdef deepwalk_walk(self, walk_length, start_node):walk = [start_node]while len(walk) < walk_length:cur = walk[-1]cur_nbrs = list(self.G.neighbors(cur))if len(cur_nbrs) > 0:walk.append(random.choice(cur_nbrs))else:breakreturn walkdef node2vec_walk(self, walk_length, start_node):G = self.Galias_nodes = self.alias_nodesalias_edges = self.alias_edgeswalk = [start_node]while len(walk) < walk_length:cur = walk[-1]cur_nbrs = list(G.neighbors(cur))if len(cur_nbrs) > 0:if len(walk) == 1:walk.append(cur_nbrs[alias_sample(alias_nodes[cur][0], alias_nodes[cur][1])])else:prev = walk[-2]edge = (prev, cur)next_node = cur_nbrs[alias_sample(alias_edges[edge][0],alias_edges[edge][1])]walk.append(next_node)else:breakreturn walkdef simulate_walks(self, num_walks, walk_length, workers=1, verbose=0):G = self.Gnodes = list(G.nodes())results = Parallel(n_jobs=workers, verbose=verbose, )(delayed(self._simulate_walks)(nodes, num, walk_length) for num inpartition_num(num_walks, workers))walks = list(itertools.chain(*results))return walksdef _simulate_walks(self, nodes, num_walks, walk_length, ):walks = []for _ in range(num_walks):random.shuffle(nodes)for v in nodes:if self.p == 1 and self.q == 1:walks.append(self.deepwalk_walk(walk_length=walk_length, start_node=v))else:walks.append(self.node2vec_walk(walk_length=walk_length, start_node=v))return walksdef get_alias_edge(self, t, v):"""compute unnormalized transition probability between nodes v and its neighbors give the previous visited node t.:param t::param v::return:"""G = self.Gp = self.pq = self.qunnormalized_probs = []for x in G.neighbors(v):weight = G[v][x].get('weight', 1.0) # w_vxif x == t: # d_tx == 0unnormalized_probs.append(weight / p)elif G.has_edge(x, t): # d_tx == 1unnormalized_probs.append(weight)else: # d_tx > 1unnormalized_probs.append(weight / q)norm_const = sum(unnormalized_probs)normalized_probs = [float(u_prob) / norm_const for u_prob in unnormalized_probs]return create_alias_table(normalized_probs)def preprocess_transition_probs(self):"""Preprocessing of transition probabilities for guiding the random walks."""G = self.Galias_nodes = {}for node in G.nodes():unnormalized_probs = [G[node][nbr].get('weight', 1.0) # 保存start的邻居节点的权重for nbr in G.neighbors(node)]norm_const = sum(unnormalized_probs)normalized_probs = [float(u_prob) / norm_const for u_prob in unnormalized_probs] # 计算从node到邻居的转移矩阵alias_nodes[node] = create_alias_table(normalized_probs)alias_edges = {}for edge in G.edges():alias_edges[edge] = self.get_alias_edge(edge[0], edge[1])self.alias_nodes = alias_nodesself.alias_edges = alias_edgesreturn通过调用 RandomWalker 的 preprocess_transition_probs 方法可以生成对应 Graph 的 Node Alias 概率转移表与 Edge Alias 转移表,基于转移表与 Alias 采样就可以进行后续的游走序列生成了。这里 RandomWalker 包含了两个参数 p、q 其实是 Node2vec 中定义游走偏向 BFS 还是 DFS 的参数,如果 p=q=1 则游走退化为简单的随机游走。
4.游走构造 sku 序列
# Parallel 多线程实现 Session 内的 Item 序列游走, P=Q=1 时为 DeepWalk,反之为 Node2vecsession_reproduce = walker.simulate_walks(num_walks=args.num_walks, walk_length=args.walk_length, workers=4,verbose=1)# 保留长度大于2的游走序列session_reproduce = list(filter(lambda x: len(x) > 2, session_reproduce))这里使用了 Python 的多线程方式加速序列生成的速度并保留长度大于2的游走序列。
• simulate_walks
def simulate_walks(self, num_walks, walk_length, workers=1, verbose=0):G = self.Gnodes = list(G.nodes())results = Parallel(n_jobs=workers, verbose=verbose, )(delayed(self._simulate_walks)(nodes, num, walk_length) for num inpartition_num(num_walks, workers))walks = list(itertools.chain(*results))return walks该方法通过 Graph 获取全部 Nodes,随后使用 Parallel 多线程执行序列游走生成方法,真实调用的是 _simulate_walks,两个方法相差一个 "_" 。
• _simulate_walks
def _simulate_walks(self, nodes, num_walks, walk_length, ):walks = []for _ in range(num_walks):random.shuffle(nodes)for v in nodes:if self.p == 1 and self.q == 1:walks.append(self.deepwalk_walk(walk_length=walk_length, start_node=v))else:walks.append(self.node2vec_walk(walk_length=walk_length, start_node=v))return walks如前面所说,当 p=q=1 时,使用 deepwalk 即常规的随机游走生成序列,否则采用 node2vec 生成游走序列,最后返回全部游走结果列表 walks,下图为部分游走序列,其中 id 代表 sku_id。

四.商品侧信息预处理
1.读取商品信息
# 添加 SideInfo 侧信息# 主要包含每个 sku_id 的 brand,shop_id,cate 品牌、店铺、标签product_data = pd.read_csv(args.data_path + 'jdata_product.csv').drop('market_time', axis=1).dropna()读取商品侧信息文件,去除无关的 'market_time' 列并删除 Nan 的列,最后将 sku_id 根据前面得到的 LabelEncoder 进行编码转化,这里共有 34048 个 sku 商品。

Tips:
这里的 sku_id 还未编码,所以并不能与前面 LabelEncoder 编码过的 sku_id 一一对应。
2.Left Join 匹配侧信息
# 采用 LeftJoin 拼接 Product 信息,其中默认值填充 0all_skus['sku_id'] = sku_lbe.inverse_transform(all_skus['sku_id'])print(str(all_skus.count()))sku_side_info = pd.merge(all_skus, product_data, on='sku_id', how='left').fillna(0)为了 Left Join 为刚才的商品匹配 Side info 侧信息,这里需要首先将 all_skus 的 sku_id 通过 inverse_transform 反编码为原始状态,随后与 product_data 侧信息进行 Left Join 匹配,默认填充值为 0。
匹配后我们就可以得到样本中出现过的 sku item 的全部侧信息了。
3.Id2Index 构建
与 sku_id 同理,brand、shop_id 和 cate 也无法保证连续性,因此也需要通过 LabelEncoder 进行编码从而方便后续的模型训练。
# featNumfeat_num_list = []# id2indexfor feat in sku_side_info.columns:if feat != 'sku_id':lbe = LabelEncoder()sku_side_info[feat] = lbe.fit_transform(sku_side_info[feat])feat_num_list.append([feat, len(list(lbe.classes_))])else:sku_side_info[feat] = sku_lbe.transform(sku_side_info[feat])feat_num_list.append([feat, len(list(sku_lbe.classes_))])sku_side_info = sku_side_info.sort_values(by=['sku_id'], ascending=True)sku_side_info.to_csv('./data_cache/sku_side_info.csv', index=False, header=False, sep='\\t')最后缓存至 csv 文件中以备后续使用,可以看到编码后各个类型数据的数量:
[['sku_id', 34048], ['brand', 3663], ['shop_id', 4786], ['cate', 80]]
五.基于 Ngram 与 Negative Sample 的样本生成
1.自定义 Ngram 样本生成
all_pairs = get_graph_context_all_pairs(session_reproduce, args.window_size)np.savetxt('./data_cache/all_pairs', X=all_pairs, fmt="%d", delimiter=" ")自定义方法也很好理解,遍历每一个 Seq 的每一个 Sku,基于中心词 target sku 构建 window_size 的窗口,随后将 target sku 与 window 范围内的 context sku 构成多组 (target, context) 样本保存下来。
def get_graph_context_all_pairs(walks, window_size):all_pairs = []# 每一个序列for k in range(len(walks)):# 每一个 wordfor i in range(len(walks[k])):# 添加 Item -> Target 逻辑for j in range(i - window_size, i + window_size + 1):if i == j or j < 0 or j >= len(walks[k]):continueelse:all_pairs.append([walks[k][i], walks[k][j]])return np.array(all_pairs, dtype=np.int32)但是常规方法只生成了正样本,还需要我们基于 sku 数量进行全局的负采样,不过这里 kreas 已经提供了现成的 Ngram 带负采样的方法,下面我们尝试一下。
2.keras.preprocessing.sequence.skipgrams 样本生成
all_pairs = []labels = []num_ns = 5SEED = 99 for seq in session_reproduce[0:1000]:skip_grams, ys = tf.keras.preprocessing.sequence.skipgrams(seq,vocabulary_size=sku_num,window_size=args.window_size,negative_samples=5)all_pairs.extend(skip_grams)labels.extend(ys)all_pairs 存储所有 (target, context) 对,num_ns 代表负采样的数量,一般为 5-20,seq 为 待采样序列,window_size 为窗口大小,其关于正样本的采样思路与上面的自定义方法一致,不同的是内置了负采样机制,可以直接得到正负样本。下图为 skipgrams 采样得到的 10 个样本与其对应 label:

3.tf.random.log_uniform_candidate_sampler 采样负样本
细心的小伙伴会发现上述方法中,如果参数 negative_sampels = 0 时,得到的就全是正样本对,结合 tf.random.log_uniform_candidate_sampler 对每一个正样本进行一次负采样也未尝不可。
- 获取全部正样本
all_pairs = []
targets, contexts, labels = [], [], []positive_skip_grams, ys = tf.keras.preprocessing.sequence.skipgrams(seq,vocabulary_size=sku_num,window_size=args.window_size,negative_samples=0)与上面一致,区别是 negative_samples 参数设置为 0 即不采样负样本。
- 根据正样本获取负样本
for target_word, context_word in positive_skip_grams:context_class = tf.reshape(tf.constant(int(context_word), dtype='int64'), (1, 1))negative_sampling_candidates, _, _ = tf.random.log_uniform_candidate_sampler(true_classes=context_class,num_true=1,num_sampled=num_ns,unique=True,range_max=sku_num,seed=SEED,name="negative_sampling")根据正样本的 context_class 采样 num_ns 个负样本,词库大小由 sku 总数决定,unique 用于指定负采样样本是否可以重复。
- 构建正负样本与 Labels
# Build context and label vectors (for one target word)negative_sampling_candidates = tf.expand_dims(negative_sampling_candidates, 1)context = tf.concat([context_class, negative_sampling_candidates], 0)label = tf.constant([1] + [0] * num_ns, dtype="int64")# Append each element from the training example to global lists.targets.append(target_word)contexts.append(context)labels.append(label)一个正样本与 num_ns 个负样本,所以 labels 构建采用 1 + 0 x ns 的构造方式。
Tips:
这里第三种方法主要是介绍一种负样本采样方法,相比第二种方式其不够简洁,因此后续模型实战中,我们的正负样本与 Label 采用第二种 skipgram 的方法构建。
六.总结
本文涉及到很多细节内容并未完全展示,更详细的讲解可以参考:
根据 networkx 获取生成带权图:GraphEmbedding networks 获取图结构
DeepWalk 随机游走:GraphEmbedding DeepWalk 图文详解
Alias 采样:GraphEmbedding Alias 采样图文详解
Node2vec 序列游走:GraphEmbedding Node2vec 图文详解
EGES 算法分析:EGES 与推荐系统用户冷启动
Parallel 多线程:Python - 多线程 Parallel / Multiprocessing 示例
最后感谢 https://github.com/wangzhegeek/EGES 项目的开发者,上述数据预处理的数据以及 utils 工具类大家可以在 Github 项目中获取。本文主要对 DataProcess 的过程进行了图文的详细分析以供大家参考,后续将基于上述预处理得到的数据通过 Keras 自定义 Word2vec 与 EGES。