Spring循环依赖

前言
不知道大家听过Spring的循环依赖这个问题吗,而且这个问题是面试经常问的,属于Spring的一个比较重要的话题,也比较典型,比较考验一个人对Spring的研究程度
循环依赖问题,本文会通过三个方面来简单介绍
1、什么是Spring的循环依赖
2、多种情况下的循环依赖
3、Spring如何解决循环依赖
了解Spring循环依赖
什么是循环依赖
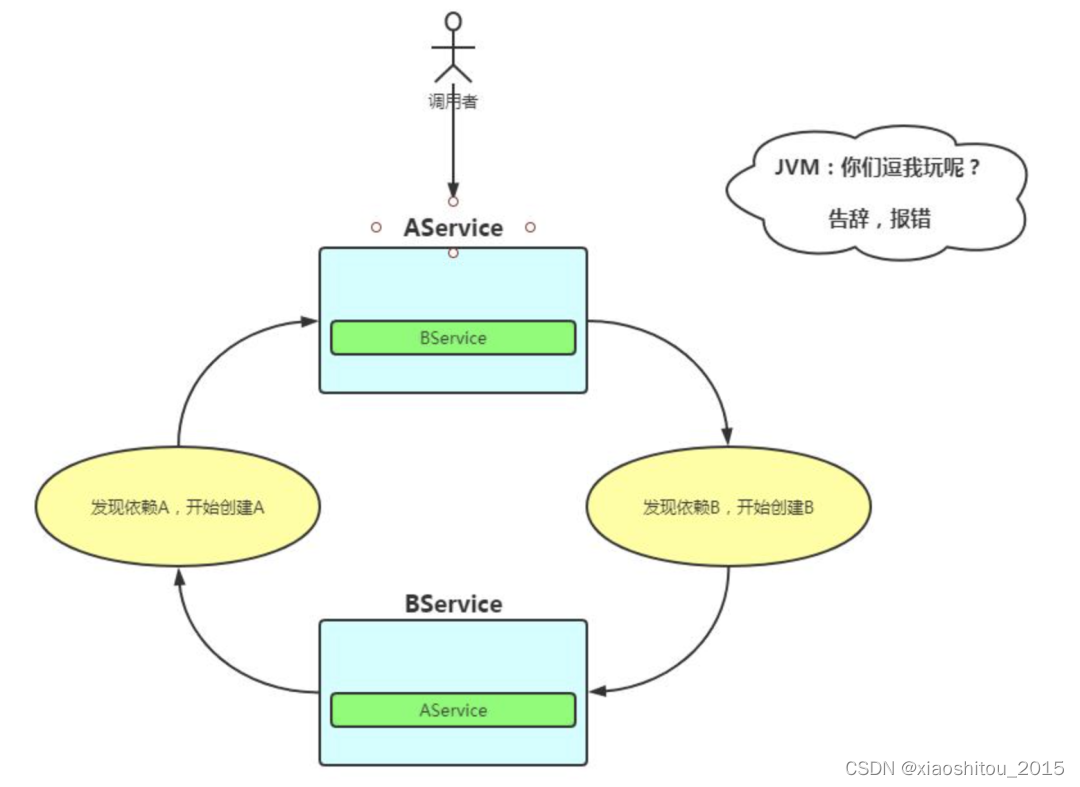
@Component
public class AService {// AService中注入了BService@Autowiredprivate BService bService;
}@Component
public class BService {// BService中也注入了AService@Autowiredprivate AService aService;
}
这是属于比较常见的一种循环依赖,还有就是更多的之间的相互依赖,比如A依赖B,B依赖C,C依赖A,类似于三角恋…
当然也有特殊的,自己的依赖自己
// 自己依赖自己
@Component
public class AService {// A中注入了A@Autowiredprivate AService aService;
}
关于上面service的Spring bean的创建,其实本质上也会一个对象的创建,既然是对象,就要明白一个对象需要完成的对象包含两个部分:当前对象的实例化和对象属性的实例化
我们如果用一个常人的思维去考虑,这肯定是做不到的啊,A需要B,B需要A,这不成死循环了,和死锁一个道理了,这就很尴尬了,该怎么解决呢,接着看下去
多种情况下的循环依赖
Spring的循环依赖也是可能出现多种情况的,比如构造器注入,setter注入等等,那什么情况下Spring可以解决循环依赖,什么情况下又不能解决呢
Spring解决循环依赖的前提条件就是:
1、出现循环依赖的bean必须是单例的
2、依赖注入的方式不能全是构造器注入
注意不能全是这几个字眼,这里需要强调一点的是,大家可能会看到很多关于Spring解决循环依赖的博客,其中只能解决setter注入的方式这种说法是错误的,只要不全是构造器注入Spring就可以解决
Spring bean的创建,其实本质上也会一个对象的创建,既然是对象,就要明白一个对象需要完成的对象包含两个部分:当前对象的实例化和对象属性的实例化,在Spring中,对象的实例化是通过反射实现的,而对象的属性则是在对象实例化之后通过后置处理器设置,知道了这一点,可以更好的帮助大家去理解
上面说的第一点必须是单例的其实很好理解,你想啊,如果是多个实例,该引入哪个实例就不知道了,Spring框架就蒙圈了(spring框架默认单例)
但是第二点呢,不能全是构造器注入呢,先看代码
@Component
public class AService {
// @Autowired
// private BService bService;public AService(BService bService) {}
}@Component
public class BService {// @Autowired
// private AService aService;public BService(AService aService){}
}
上面这个例子大家看得懂吧,别告诉我你看不懂,AService中的BService注入是通过构造器,反之也是通过构造器注入,这个时候Spring是无法解决循环依赖问题的,如果项目中出现两个这样的引用,在启动的时候就会直接抛出异常
Caused by: org.springframework.beans.factory.BeanCurrentlyInCreationException: Error creating bean with name 'a': Requested bean is currently in creation: Is there an unresolvable circular reference?
解决循环依赖
首先呢,Spring解决循环依赖依靠的就是内部维护的三个Map,也就是咱们常说的三级缓存,不知道大家听过没有
/ Cache of singleton objects: bean name to bean instance. */private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256);/ Cache of singleton factories: bean name to ObjectFactory. */private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16);/ Cache of early singleton objects: bean name to bean instance. */private final Map<String, Object> earlySingletonObjects = new HashMap<>(16);之所以被叫做三级缓存,大概是因为注释上都是用Cache,而起的作用也类似一个缓存的作用
1、singletonObjects:存放已经经历了完整生命周期的Bean对象 成员属性都是有值的
2、earlySingletonObjects:存放早期暴露出来的Bean对象,Bean的生命周期未结束(属性还未填充完整)
3、singletonFactories:存放可以生成Bean的工厂
二缓和三缓属于消耗的过程, 为了创造完整的单例bean, 暂时缓存在这里, 过后就清除掉了(不同于常规缓存理解, 一般有更新时候, 各级缓存同步, 这里是删除)
1、A找B找不到:
创建AService的过程中发现需要BService,于是AService将去寻找BService,发现找不到,寻找的路径是一级缓存、二级缓存、三级缓存,于是AService把自己放到了三级缓存中
2、B找A找到了:
实例化BService,实例化过程中发现需要AService,于是也是按照上述路径去寻找,在三级缓存中找到了AService
3、B创建完成:
然后就把三级缓存中的AService拿出来,放到了二级缓存中,并删除三级缓存中的AService,此时BService可以成功引用,顺利初始化完毕,把自己放到了一级缓存中了(而此时BService中的AService依然是创建中的状态
4、A创建完成:
继续完善AService,此时再去寻找BService,拿出来直接引用就好了,把自己放入到一级缓存中,删除二级缓存,删除在创建的状态信息
来一起简单的分析一波源码,不看太多,不用发愁
1、先将AService封装成ObjectFactory, 存入三级缓存中
boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences &&isSingletonCurrentlyInCreation(beanName));if (earlySingletonExposure) {if (logger.isTraceEnabled()) {logger.trace("Eagerly caching bean '" + beanName +"' to allow for resolving potential circular references");}addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));}执行Lambda 执行该方法:getEarlyBeanReference
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {Object exposedObject = bean;if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {for (BeanPostProcessor bp : getBeanPostProcessors()) {if (bp instanceof SmartInstantiationAwareBeanPostProcessor) {SmartInstantiationAwareBeanPostProcessor ibp = (SmartInstantiationAwareBeanPostProcessor) bp;exposedObject = ibp.getEarlyBeanReference(exposedObject, beanName);}}}return exposedObject;}将getEarlyBeanReference生成的结果存入三级缓存
protected void addSingletonFactory(String beanName, ObjectFactory<?> singletonFactory) {Assert.notNull(singletonFactory, "Singleton factory must not be null");synchronized (this.singletonObjects) {if (!this.singletonObjects.containsKey(beanName)) {this.singletonFactories.put(beanName, singletonFactory);this.earlySingletonObjects.remove(beanName);this.registeredSingletons.add(beanName);}}}2、AService中属性赋值,先实例化BService, BService又依赖AService
protected Object getSingleton(String beanName, boolean allowEarlyReference) {//根据beanName 从单例池中获取bean对象Object singletonObject = this.singletonObjects.get(beanName);if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {synchronized (this.singletonObjects) {//从二级缓存中获取bean对象singletonObject = this.earlySingletonObjects.get(beanName);if (singletonObject == null && allowEarlyReference) {// 从三级缓存中获取singletonFactoryObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);if (singletonFactory != null) {##执行三级缓存对应的..执行Lambda 执行该方法:getEarlyBeanReference// 判断如果开启了aop 则会生成代理类 AService代理类// 如果没有开启aop的情况下 则直接返回原始不完整bean对象singletonObject = singletonFactory.getObject();//将该代理类存入到二级缓存中 存入不完整对象this.earlySingletonObjects.put(beanName, singletonObject);//在删除三级缓存this.singletonFactories.remove(beanName);}}}}return singletonObject;}
说明: 可以看到, 在获取Aservice过程中, 依次从一二三级缓存中获取, 执行三级缓存的lumuda表达式, 将生成的bean存入二缓, 并删除三缓, Bservice从二缓找到Aservice, 实例化完成, 存入一缓
执行lumuda表达式的实际作用是为了判断返回的具体哪种对象
- 如果我们开启了aop的情况下 则返回aop代理对象
@Overridepublic Object getEarlyBeanReference(Object bean, String beanName) {Object cacheKey = getCacheKey(bean.getClass(), beanName);this.earlyProxyReferences.put(cacheKey, bean);return wrapIfNecessary(bean, beanName, cacheKey);}
-
如果我们没有开启aop的情况下 则返回原始对象
@Overridepublic Object getEarlyBeanReference(Object bean, String beanName) throws BeansException {return bean;}spring已经帮我们解决了循环依赖问题, 在实际开发中 注意写代码规范, 避免出现
1. 自己依赖自己
2. 开启了多例模式
3. AB同时使用构造注入
在排除以上情况, 如果di属性注入出现循环依赖, 使用@lazy解决即可