云原生时代顶流消息中间件Apache Pulsar部署实操之Pulsar IO与Pulsar SQL

文章目录
Pulsar IO (Connector连接器)
基础定义
Pulsar IO连接器能够轻松地创建、部署和管理与外部系统(如Apache Cassandra、Aerospike等)交互的连接器。IO连接器有两种类型:源连接器和接收器连接器。

可以通过Connector Admin CLI使用源和接收器子命令管理Pulsar连接器(例如,在连接器上创建、更新、启动、停止、重新启动、重新加载、删除和执行其他操作)。有关最新和完整的信息,请参阅Pulsar管理文档。
安装Pulsar和内置连接器
在将Pulsar连接到数据库之前,需要先安装Pulsar和所需的内置连接器。要启用Pulsar连接器,您需要在下载页面上下载连接器的tarball版本。
# 下载最新版本2.11.0的pulsar-io-cassandra和pulsar-io-jdbc-postgres,需要什么连接器可以从官方查看是否支持并下载,这里举例就下载两个
https://www.apache.org/dyn/mirrors/mirrors.cgi?action=download&filename=pulsar/pulsar-2.11.0/connectors/pulsar-io-cassandra-2.11.0.nar
https://www.apache.org/dyn/mirrors/mirrors.cgi?action=download&filename=pulsar/pulsar-2.11.0/connectors/pulsar-io-jdbc-postgres-2.11.0.nar
# 在pulsar根目录下创建目录
mkdir connectors
# 将压缩文件移动connectors目录
mv pulsar-io-jdbc-postgres-2.11.0.nar pulsar-io-jdbc-postgres-2.11.0.nar connectors
# 重启pulsar
# 查看可用连接器列表
curl -w '\\n' -s http://localhost:8080/admin/v2/functions/connectors

连接Pulsar到Cassandra
安装cassandra集群
# 下载镜像并启动cassandra测试容器
docker run -d --rm --name=cassandra -p 9042:9042 cassandra
# 查看进程
docker ps
# 查看运行日志
docker logs cassandra
# 等待一小段时间后查看Cassandra集群状态
docker exec cassandra nodetool status
# 使用cqlsh连接到Cassandra集群

# 使用cqlsh连接到Cassandra集群
docker exec -ti cassandra cqlsh localhost
# 创建一个密钥空间pulsar_itxs_keyspace
CREATE KEYSPACE pulsar_itxs_keyspace WITH replication = {'class':'SimpleStrategy', 'replication_factor':1};
# 创建一个表pulsar_itxs_table
USE pulsar_itxs_keyspace;
CREATE TABLE pulsar_itxs_table (key text PRIMARY KEY, col text);

配置Cassandra接收器
现在已经有一个Cassandra集群在本地运行;要运行Cassandra接收器连接器,需要准备一个配置文件,其中包括Pulsar连接器运行时需要知道的信息,例如Pulsar连接器如何找到Cassandra集群,Pulsar连接器用于写入Pulsar消息的键空间和表是什么等等;可以使用Json或者Yaml这两种格式创建配置文件。
vim examples/cassandra-sink.json
{"roots": "192.168.3.100:9042","keyspace": "pulsar_itxs_keyspace","columnFamily": "pulsar_itxs_table","keyname": "key","columnName": "col"
}
vim examples/cassandra-sink.yml
configs:roots: "192.168.3.100:9042"keyspace: "pulsar_itxs_keyspace"columnFamily: "pulsar_itxs_table"keyname: "key"columnName: "col"
创建Cassandra Sink
可以使用Connector Admin CLI创建sink连接器和操作。运行下面命令来创建一个Cassandra接收器连接器,接收器类型为Cassandra,配置文件为上一步创建的examples/cassandra-sink.yml。
bin/pulsar-admin sinks create \\--tenant my-test \\--namespace my-namespace \\--name cassandra-itxs-sink \\--sink-type cassandra \\--sink-config-file examples/cassandra-sink.yml \\--inputs persistent://my-test/my-namespace/itxs_cassandra
命令执行后,Pulsar创建接收器连接器cassandra-itxs-sink。这个接收器连接器作为Pulsar函数运行,并将主题itxs_cassandra中产生的消息写入Cassandra表pulsar_itxs_table;

可以使用Connector Admin CLI对连接器进行监控和其他操作。
- 获取连接器的信息
bin/pulsar-admin sinks get \\--tenant my-test \\--namespace my-namespace \\--name cassandra-itxs-sink
- 检查连接器的状态
bin/pulsar-admin sinks status \\--tenant my-test \\--namespace my-namespace \\--name cassandra-itxs-sink
验证Cassandra Sink结果
生成一些消息到Cassandra接收器itxs_cassandra的输入主题
for i in {0..9}; do bin/pulsar-client produce -m "itxskey-$i" -n 1 persistent://my-test/my-namespace/itxs_cassandra; done
再次查看连接器的状态,可以有10条记录处理统计信息
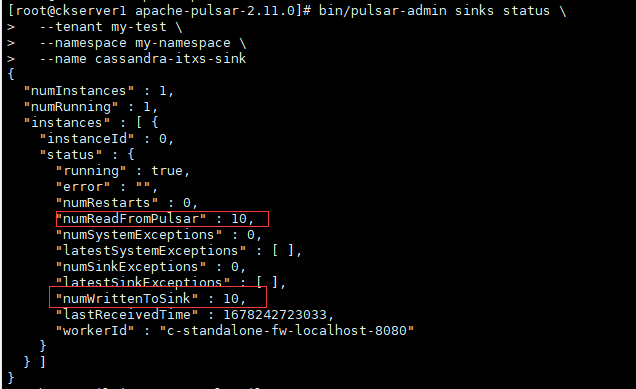
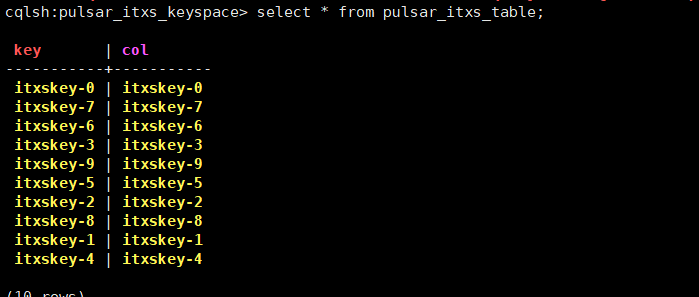
查看Cassandra的pulsar_itxs_table
USE pulsar_itxs_keyspace;
select * from pulsar_itxs_table;
删除Cassandra Sink
bin/pulsar-admin sinks delete \\--tenant my-test \\--namespace my-namespace \\--name cassandra-itxs-sink
连接Pulsar到PostgreSQL
安装PostgreSQL集群
这里使用PostgreSQL 12 docker镜像在docker中启动一个单节点PostgreSQL集群。
# 从Docker中拉取PostgreSQL 12映像
docker pull postgres:12
# 启动postgres容器
docker run -d -it --rm \\--name pulsar-postgres \\-p 5432:5432 \\-e POSTGRES_PASSWORD=password \\-e POSTGRES_USER=postgres \\postgres:12
# 查看运行日志
docker logs -f pulsar-postgres
# 进入容器
docker exec -it pulsar-postgres /bin/bash
# 使用默认用户名和密码登录PostgreSQL
psql -U postgres postgres
# 使用以下命令创建pulsar_postgres_jdbc_sink表:
create table if not exists pulsar_postgres_jdbc_sink
(
id serial PRIMARY KEY,
name VARCHAR(255) NOT NULL
);
配置JDBC接收器
现在有一个本地运行的PostgreSQ,接下来需要配置JDBC接收器连接器。
- 创建配置文件vim connectors/pulsar-postgres-jdbc-sink.yaml
configs:userName: "postgres"password: "password"jdbcUrl: "jdbc:postgresql://192.169.3.100:5432/postgres"tableName: "pulsar_postgres_jdbc_sink"
创建JDBC Sink
执行下面命令后,Pulsar将创建接收器连接器pulse -postgres-jdbc-sink。这个sink连接器作为Pulsar函数运行,并将Topic为pulsar-postgres-jdbc-sink-topic中产生的消息写入PostgreSQL表pulsar_postgres_jdbc_sink。
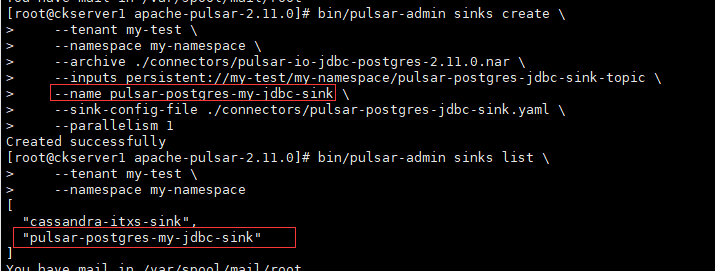
bin/pulsar-admin sinks create \\--tenant my-test \\--namespace my-namespace \\--archive ./connectors/pulsar-io-jdbc-postgres-2.11.0.nar \\--inputs persistent://my-test/my-namespace/pulsar-postgres-jdbc-sink-topic \\--name pulsar-postgres-my-jdbc-sink \\--sink-config-file ./connectors/pulsar-postgres-jdbc-sink.yaml \\--parallelism 1
列出所有的sink
bin/pulsar-admin sinks list \\--tenant my-test \\--namespace my-namespace
验证JDBC Sink结果
通过JavaAPI生成一些消息到Cassandra接收器pulsar-postgres-jdbc-sink-topic这个主题,在Java项目添加maven依赖
<properties><pulsar.version>2.11.0</pulsar.version></properties> <dependency><groupId>org.apache.pulsar</groupId><artifactId>pulsar-client</artifactId><version>${pulsar.version}</version></dependency>
这里演示实体类成员变量简单就直接使用public声明了
package sn.itxs.pulsar.io;public class User{public int id;public String name;
}
新增ClientDemo.java
package sn.itxs.pulsar.io;import org.apache.pulsar.client.api.Producer;
import org.apache.pulsar.client.api.PulsarClient;
import org.apache.pulsar.client.impl.schema.AvroSchema;public class ClientDemo {public static void main(String[] args) throws Exception {PulsarClient client = null;Producer<User> producer = null;try {client = PulsarClient.builder().serviceUrl("pulsar://192.168.5.52:6650").build();producer = client.newProducer(AvroSchema.of(User.class)).topic("persistent://my-test/my-namespace/pulsar-postgres-jdbc-sink-topic").create();User user = new User();int index = 10;while (index++ < 20) {try {user.id = index;user.name = "this is a test " + index;producer.newMessage().value(user).send();} catch (Exception e) {e.printStackTrace();}}System.out.println("send finish");} catch (Exception e) {e.printStackTrace();}finally {if (producer!=null){producer.close();}if (client!=null){client.close();}}}
}
运行程序后查看PostgreSQL表pulsar_postgres_jdbc_sink,已经有刚才
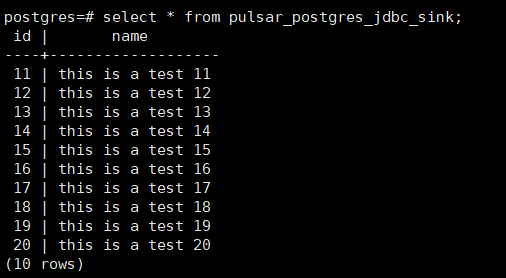
上面由于在Java中创建了Schema,因此不需要手工创建,可以查看当前persistent://my-test/my-namespace/pulsar-postgres-jdbc-sink-topic主体已生成Schema信息如下:
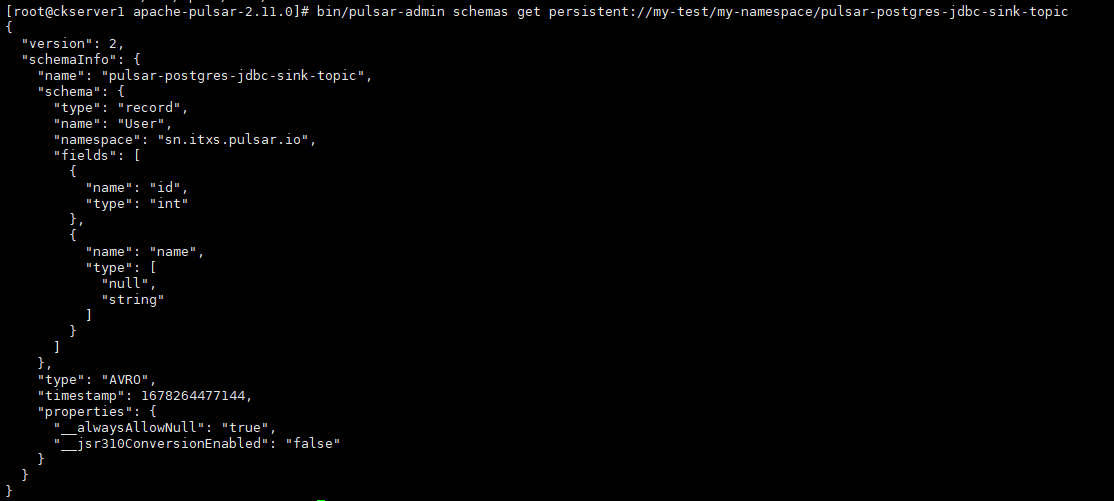
如果要从pulsar-admin命令行创建schema可以这样操作
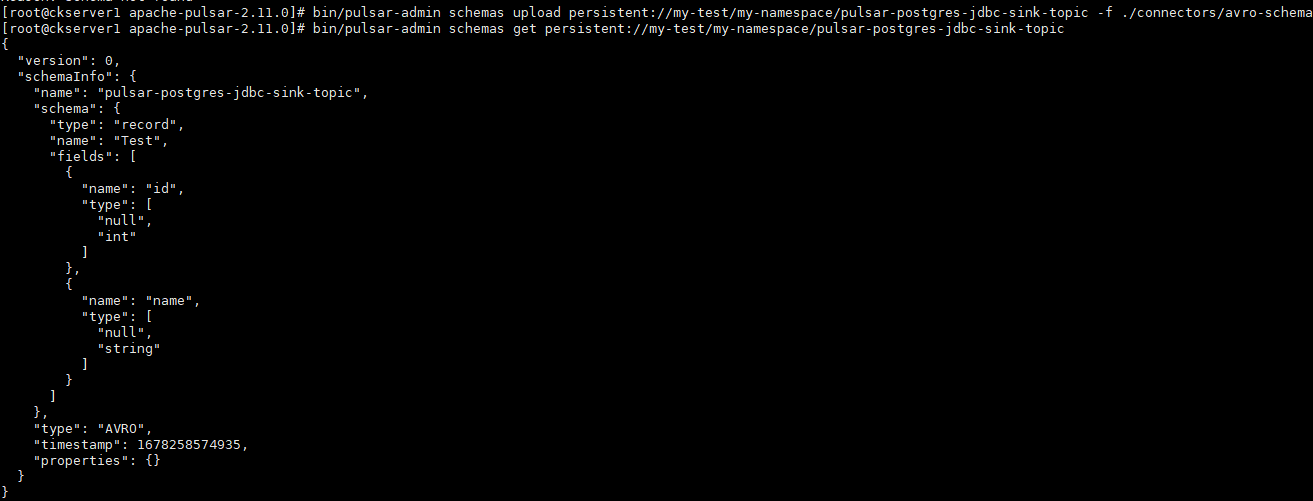
- 创建schema,创建一个avro-schema文件,将以下内容复制到该文件中,并将该文件放在pulsar/connectors文件夹中。vim connectors/avro-schema
{"type": "AVRO","schema": "{\\"type\\":\\"record\\",\\"name\\":\\"Test\\",\\"fields\\":[{\\"name\\":\\"id\\",\\"type\\":[\\"null\\",\\"int\\"]},{\\"name\\":\\"name\\",\\"type\\":[\\"null\\",\\"string\\"]}]}","properties": {}
}
- 上传schema到topic,将avro-schema模式上传到pulsar-postgres-jdbc-sink-topic主题
bin/pulsar-admin schemas upload persistent://my-test/my-namespace/pulsar-postgres-jdbc-sink-topic -f ./connectors/avro-schema
- 检查模式是否上传成功。
bin/pulsar-admin schemas get persistent://my-test/my-namespace/pulsar-postgres-jdbc-sink-topic1
如需stop停止、restart重启指定的sinks可以如下操作,当然也可以更新指定sinks,详细命令可以查阅官网
bin/pulsar-admin sinks stop \\--tenant my-test \\--namespace my-namespace \\--name pulsar-postgres-my-jdbc-sink \\
Pulsar SQL
定义
Apache Pulsar用于存储事件数据流,事件数据由预定义的字段构成。通过模式注册表的实现,可以在Pulsar中存储结构化数据,并使用Trino(以前是Presto SQL)查询数据。作为Pulsar SQL的核心,Pulsar Trino插件使Trino集群中的Trino worker能够查询来自Pulsar的数据.
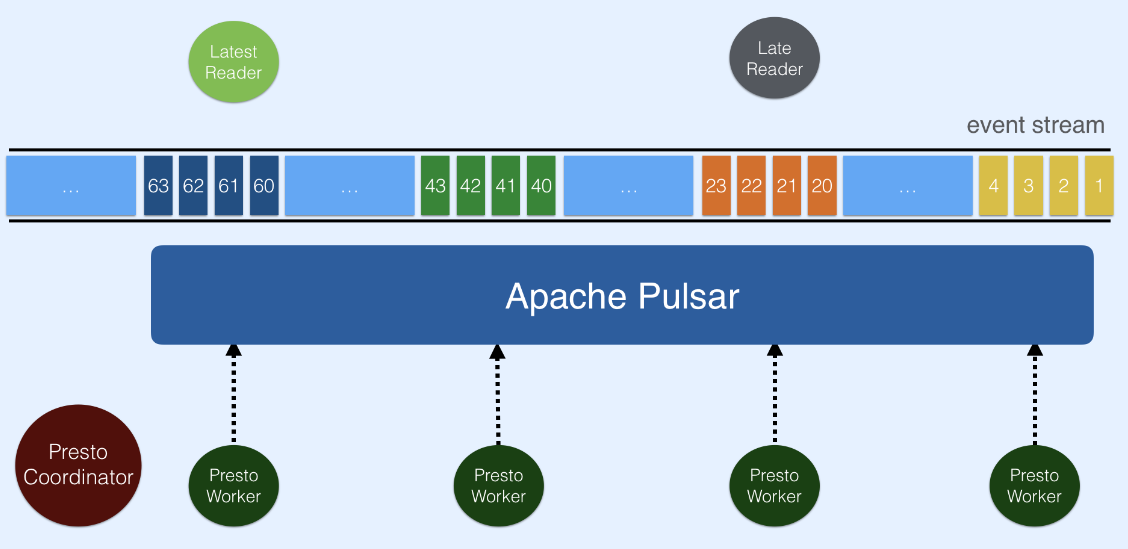
由于Pulsar采用了基于两级段的架构,因此查询性能高效且可扩展性强。Pulsar中的主题在Apache BookKeeper中存储为段。每个主题段被复制到一些BookKeeper节点上,从而支持并发读和高读吞吐量。在Pulsar Trino连接器中,数据直接从BookKeeper中读取,因此Trino worker可以同时从水平可扩展数量的BookKeeper节点中读取
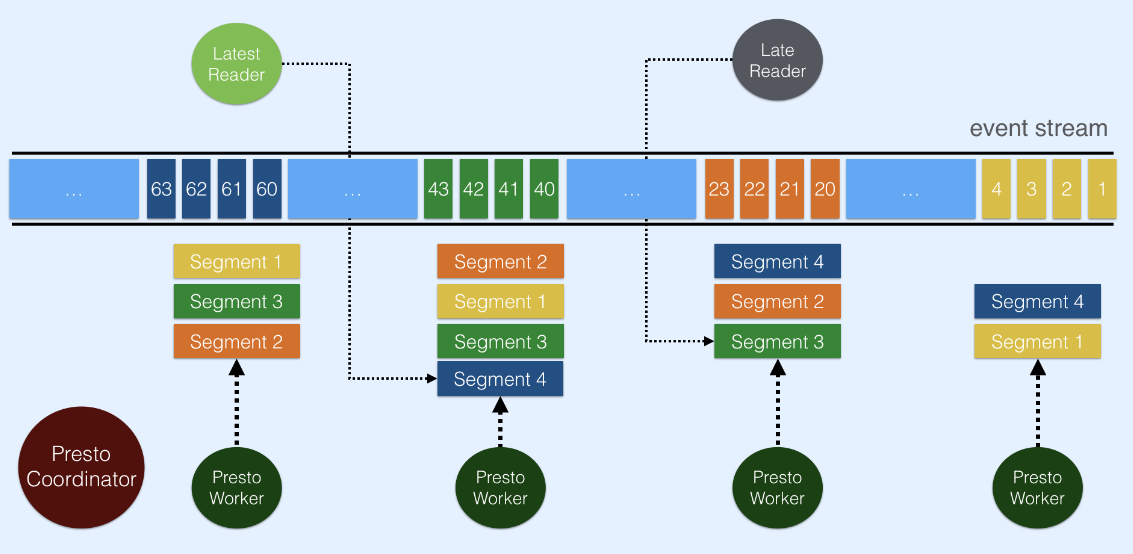
简单使用
在Pulsar中查询数据前,需要安装Pulsar和内置连接器。
# 这里演示就直接启动独立集群
PULSAR_STANDALONE_USE_ZOOKEEPER=1 ./bin/pulsar standalone
# 启动一个Pulsar SQL worker
./bin/pulsar sql-worker run
# 初始化Pulsar独立集群和SQL worker后,执行SQL CLI:
./bin/pulsar sql
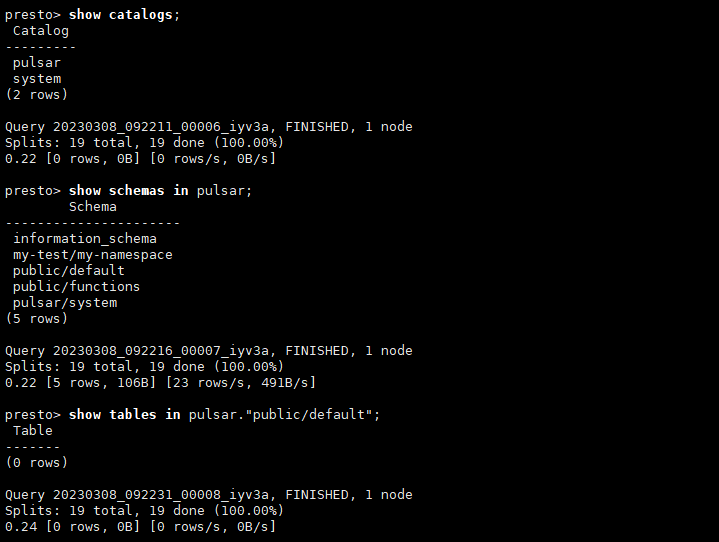
show catalogs;
show schemas in pulsar;
show tables in pulsar."public/default";
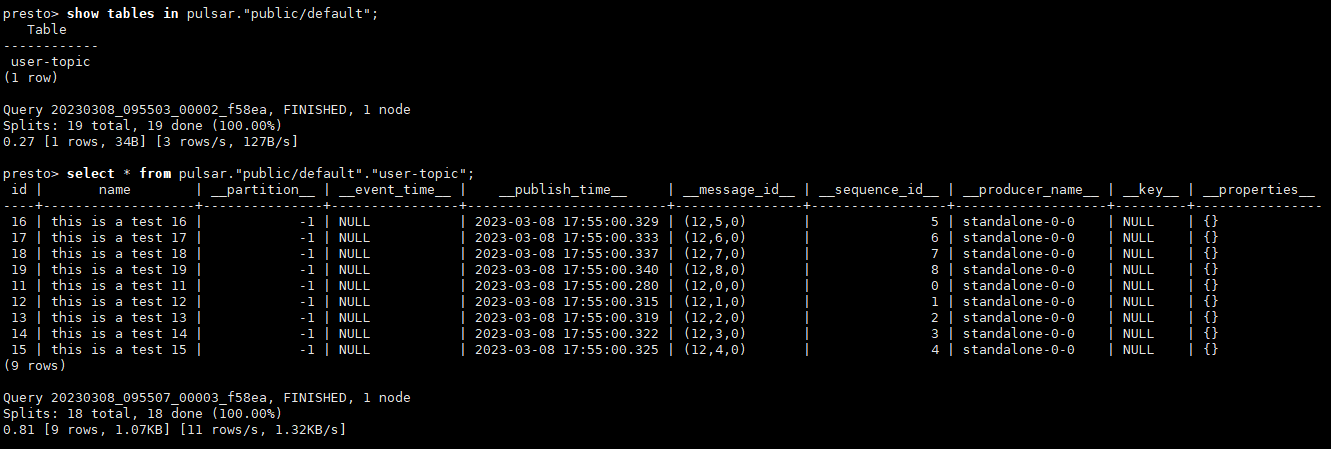
通过前面的Java示例,我们改为Json格式写入Pulsar的user-topic
package sn.itxs.pulsar.io;import org.apache.pulsar.client.api.Producer;
import org.apache.pulsar.client.api.PulsarClient;
import org.apache.pulsar.client.api.Schema;public class ClientSqlDemo {public static void main(String[] args) throws Exception {PulsarClient client = null;Producer<User> producer = null;try {client = PulsarClient.builder().serviceUrl("pulsar://192.168.5.52:6650").build();producer = client.newProducer(Schema.JSON(User.class)).topic("user-topic").create();User user = new User();int index = 10;while (index++ < 20) {try {user.id = index;user.name = "this is a test " + index;producer.newMessage().value(user).send();} catch (Exception e) {e.printStackTrace();}}System.out.println("send finish");} catch (Exception e) {e.printStackTrace();}finally {if (producer!=null){producer.close();}if (client!=null){client.close();}}}
}
运行程序后再来查询就有刚才发送的消息数据,_开头的字段为Pulsar 自带的。
select * from pulsar."public/default"."user-topic";
- 本人博客网站IT小神 www.itxiaoshen.com