自然语言处理实战项目4-文本相似度的搜索功能,搜索文本内容

大家好,我是微学AI,今天给大家带来自然语言处理实战项目4-文本相似度的搜索功能,搜索文本内容。文本相似度搜索是一种基于自然语言处理技术,用于搜索和匹配文本内容的方法。其主要目的是将用户输入的查询内容与已有的文本数据进行比较,并找到最相似的文本数据。
本文本以目标实现为导向,实战让大家跑通文本相似度的搜索功能。
一、实现文本相似度的搜索功能步骤:
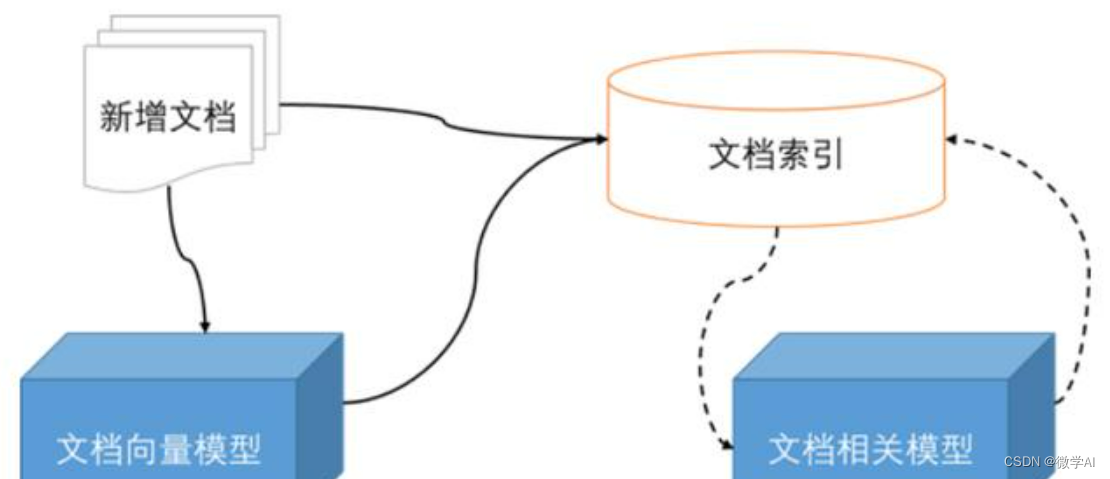
1.首先加载与处理文件夹数据,本文以txt文件为例子,批量处理。
2.然后构建文件名和文件内容的索引文件。
3.在进行文档向量化与模型构建,生成向量模型
4.加载模型进行相似度的计算并返回。
5.后续可以新增文档到向量模型,可搜索到新加的文件
二、文本相似度的搜索功能代码:
1.构建文件搜索引擎类
mport os
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
import pickle
from settings.app_config import project_config as fileconfig
import PyPDF2
import csvindex_file = 'index.pkl'
vectorizer_file = 'vectorizer.pkl'
index_file_path = 'file_path.pickle'# 构建文件搜索引擎类
class FileSearchManage():def __init__(self):self.index_file_path = index_file_pathself.index_file = index_file self.vectorizer_file = vectorizer_file#读取文件def read_files(self,folder_path):files_data = {}for file_name in os.listdir(folder_path):if file_name.endswith(".txt"):with open(os.path.join(folder_path, file_name), 'r', encoding='utf-8') as f:files_data[file_name] = f.read().replace('\\n', '')return files_data# 保存 csv 文件def save_csv_files(self, folder_path,csv_path):# 将信息写入csv文件with open(csv_path, 'w', newline='', encoding='utf-8') as csvfile:fieldnames = ['file_name', 'paragraph', 'content']writer = csv.DictWriter(csvfile, fieldnames=fieldnames)writer.writeheader()for file_name in os.listdir(folder_path):if file_name.endswith(".pdf"):path_name, paragraph = ocr_paragraph_pdf(os.path.join(folder_path, file_name))for i, pa in enumerate(paragraph):pa = pa.replace('\\n', '').replace(' ', '')if len(pa) > 4:writer.writerow({'file_name': file_name,'paragraph': i,'content': pa})# 读取pickle索引文件def read_pickle(self,index_file_path):with open(index_file_path, 'rb') as f:index = pickle.load(f)return index#分词、去除停用词 处理def preprocess_data(self,files_data):processed_data = {}for file_name, content in files_data.items():# 在这里可以对文档内容进行预处理(例如:分词、去除停用词)processed_data[file_name] = contentreturn processed_data# 创建索引文件向量def create_tfidf_index(self,processed_data):vectorizer = TfidfVectorizer()corpus = list(processed_data.values())X = vectorizer.fit_transform(corpus)return X, vectorizer# 报错文件jsondef save_file(self,index_file_path,files_data):with open(index_file_path, 'wb') as f:pickle.dump(files_data, f)# 保存索引文件向量def save_index(self,index, vectorizer, index_file, vectorizer_file):with open(index_file, 'wb') as f:pickle.dump(index, f)with open(vectorizer_file, 'wb') as f:pickle.dump(vectorizer, f)# 加载索引文件向量def load_index(self,index_file, vectorizer_file):with open(index_file, 'rb') as f:index = pickle.load(f)with open(vectorizer_file, 'rb') as f:vectorizer = pickle.load(f)return index, vectorizerdef preprocess_query(self,query):# 对查询进行预处理(例如:分词、去除停用词)return query# 文件查找函数def search(self,query, index, vectorizer, files_data,num):processed_query = self.preprocess_query(query)query_vector = vectorizer.transform([processed_query])cosine_similarities = cosine_similarity(index, query_vector)top_file_indices = cosine_similarities.ravel().argsort()[-int(num):][::-1]# print(top_file_indices)results = []for file_index in top_file_indices:file_name = list(files_data.keys())[file_index]file_content = files_data[file_name]similarity = cosine_similarities[file_index][0]results.append((file_name, file_content, similarity))return sorted(results, key=lambda x: x[-1], reverse=True)# return most_similar_file_name, most_similar_file_content# 文件相似度计算def search_similar_files(self,query,num):files_data = self.read_pickle(self.index_file_path)#processed_data = self.preprocess_data(files_data)index, vectorizer = self.load_index(self.index_file, self.vectorizer_file)result = self.search(query, index, vectorizer, files_data,num)result = [x[0]+" "+str(x[2]) for x in result]return result# print('File content:', result_file_content)# 获取文件内容def get_content(self,filename):files_data = self.read_pickle(self.index_file_path)result = files_data[filename]return result# 新增新的索引文件def add_new_file(self,file_path):index,vectorizer = self.load_index(self.index_file, self.vectorizer_file)files_data = self.read_pickle(self.index_file_path)content =''try:if file_path.split('.')[-1]=='txt':with open(file_path, 'r', encoding='utf-8') as f:file_content = f.read().replace('\\n', '')files_data[file_path.split('/')[-1]] = file_contentif file_path.split('.')[-1] == 'pdf':with open(file_path, 'rb') as f:pdf_reader = PyPDF2.PdfFileReader(f)# 获取PDF文件的页数num_pages = pdf_reader.numPages# 创建文本文件,并将PDF文件每一页的内容写入for i in range(num_pages):page = pdf_reader.getPage(i)text = page.extractText().replace(' ', '')content = content + textfile_content = content.replace('\\n', '')files_data[file_path.split('/')[-1]] = file_contentwith open(self.index_file_path, 'wb') as f:pickle.dump(files_data, f)corpus = list(files_data.values())X = vectorizer.fit_transform(corpus)with open(self.index_file, 'wb') as f:pickle.dump(X, f)with open(self.vectorizer_file, 'wb') as f:pickle.dump(vectorizer, f)return 'successful'except Exception as e:print(e)return 'fail'
2.构建文件夹导入函数
if __name__ == '__main__':folder_path = '文件夹的地址' # 例如'E:/data'def create_file(folder_path):FileSearch = FileSearchManage()files_data = FileSearch.read_files(folder_path)processed_data = FileSearch.preprocess_data(files_data)FileSearch.save_file(index_file_path,processed_data)index, vectorizer = FileSearch.create_tfidf_index(processed_data)FileSearch.save_index(index, vectorizer, index_file, vectorizer_file)def file_search(query):FileSearch = FileSearchManage()files_data = FileSearch.read_pickle(index_file_path)processed_data = FileSearch.preprocess_data(files_data)index, vectorizer = FileSearch.load_index(index_file, vectorizer_file)result_file_name = FileSearch.search(query, index, vectorizer, files_data,num=5)print('File name:', result_file_name)def file_add(folder_path):FileSearch = FileSearchManage()files_data = FileSearch.read_pdf_files(folder_path)with open(index_file_path, 'wb') as f:pickle.dump(files_data, f)processed_data = FileSearch.preprocess_data(files_data)index, vectorizer = FileSearch.create_tfidf_index(processed_data)FileSearch.save_index(index, vectorizer, index_file, vectorizer_file)index, vectorizer = FileSearch.load_index(index_file, vectorizer_file)query = '*'result_file_name = FileSearch.search(query, index, vectorizer, files_data,num=5)create_file(folder_path)#query ='搜索语句'#file_search(query)#file_add(folder_path)我们还可以根据自己的需求,添加新的文件,可以是txt,pdf的文件,pdf有的文件可以直接转文本,有的图片的需要OCR识别,这个可以接入OCR进行识别,使得系统更加的完善。欢迎大家进行关注与支持,有更多需求和合作的可以联系。