论文解读 | [CVPR2019] 基于自适应文本区域表示的任意形状场景文本检测
![论文解读 | [CVPR2019] 基于自适应文本区域表示的任意形状场景文本检测](http://pic.ttrar.cn/nice/%e8%ae%ba%e6%96%87%e8%a7%a3%e8%af%bb%7c%5bCVPR2019%5d%e5%9f%ba%e4%ba%8e%e8%87%aa%e9%80%82%e5%ba%94%e6%96%87%e6%9c%ac%e5%8c%ba%e5%9f%9f%e8%a1%a8%e7%a4%ba%e7%9a%84%e4%bb%bb%e6%84%8f%e5%bd%a2%e7%8a%b6%e5%9c%ba%e6%99%af%e6%96%87%e6%9c%ac%e6%a3%80%e6%b5%8b.jpg)
目录
1 研究背景及意义
2 总体设计
3 方法论
3.2 文本建议
3.3 建议改进
4 损失函数
5 实验及结果
1 研究背景及意义
现有的场景文本检测方法使用固定点数的多边形来 表示文本区域。例如,水平文本使用2个点(左上/右下)表示文本区域,多方向文本用4个点表示文本区域,对于弯曲文本(CTW1500)使用14个点表示文本区域。虽然使用固定点数的方式能很好的适应对应的实例,但面对复杂的场景文本时仍然不能很好的表示文本区域。例如,弯曲的长文本即使是用14个点也不足以表示出文本区域,而对于定向或多方向文本14个点右显得很浪费。
针对上面的问题,本文提出了一种针对不同形状文本使用不同点数的自适应文本区域表示方法。同时,使用RNN学习每个文本区域的自适应表示,使用该表示可以直接标记文本区域,并且不需要逐像素分割。
2 总体设计
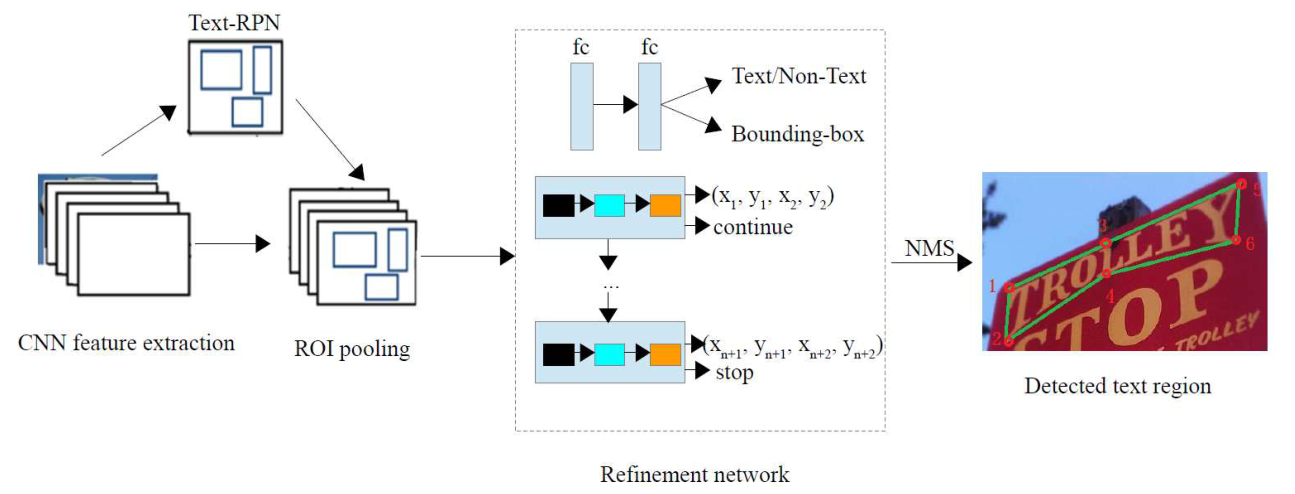
图1 本文提出的任意形状文本检测流程图,包括文本建议和建议改进两个阶段。
文本建议:Text-RPN 生成图像的文本建议,同时提取输入图像的 CNN 特征图,用于后面的操作。
建议改进:使用细化网络对文本建议进行细化和验证。其中包括文本/非文本,边界框回归和基于 RNN 的自适应文本区域表示。最后,输出标记有自适应点数的多边形的文本区域作为检测结果。
3 方法论
3.1 自适应文本区域表示
传统的使用固定点数的文本区域表示方法对于复杂的场景文本并不实用,本文使用自适应点数的多边形来表示文本区域,并且这样才是合理的。
如图2(a) 所示,文本区域边界上的角点可以用于文本区域的表示,但是这种方法对于点不是按方向排列的,可能很难学习表示,同时还可能需要人为矫正来实现精确的分割。在本文中,考虑到文本区域通常具有近似对称的上下边界。使用上下边界的成对点表示文本区域似乎更合适,如图2(b)。并且对这些成对点从一端到另一端的学习也会很容易。
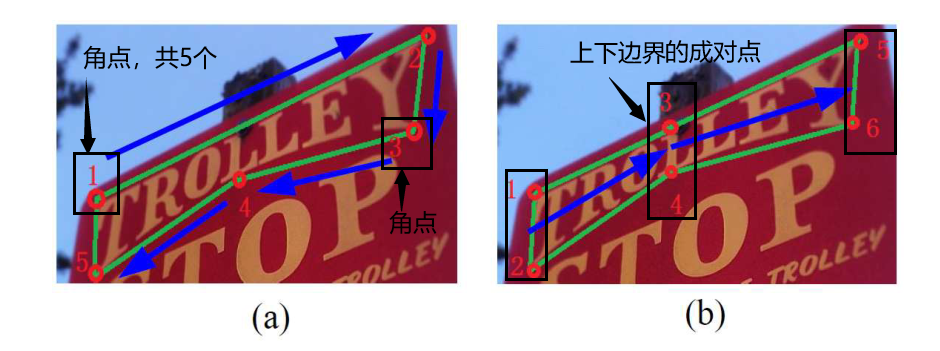
图2
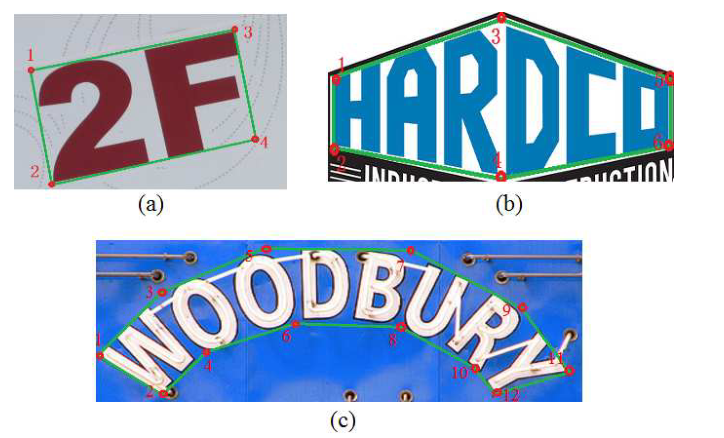
图3 (a)由4个点(2对)表示的文本区域; (b)由6个点(3对)表示的文本区域;
(c) 由12个点(6对)表示的文本区域。
3.2 文本建议
Text-RPN 生成文本区域候选。Text-RPN 与 Faster R-CNN 中的 RPN 相似,骨干网络使用 SE-VGG16,如图4所示。通过将压缩和激励块(SE)添加到 VGG16 而获得的。SE模块(图5)通过显式建模信道之间的相互依赖性,自适应地重新校准信道特性响应,这可以产生显著的性能改进。FC为全连接层,ReLU 表示矫正线性单位函数。
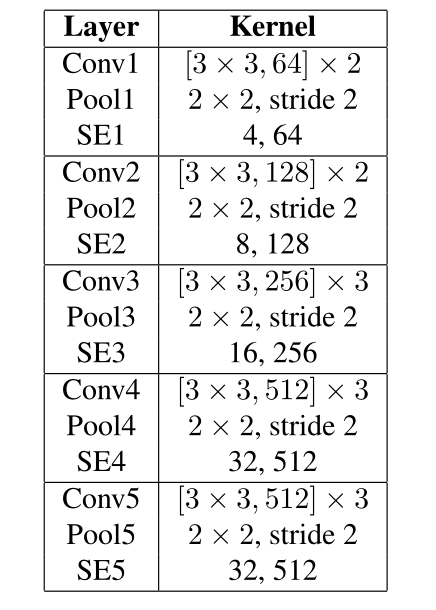
图4 SE-VGG16网络的架构
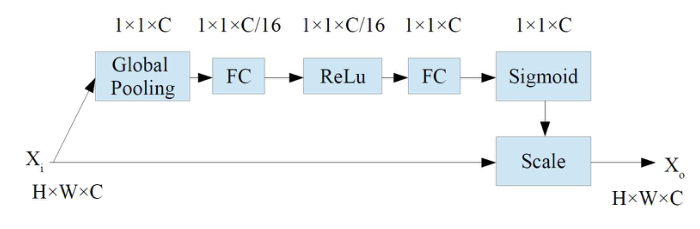
图5 SE模块的架构
3.3 建议改进
将文本建议模块中生成的文本区域候选进行验证和细化。如图6所示,一个细化网络用于提案细化,它由几个分支组成:文本/非文本分类、边界框回归和基于RNN的自适应文本区域表示。这里,文本/非文本分类和边界框回归与其他两阶段文本检测方法相似,而最后一个分支被提出用于任意形状的文本表示。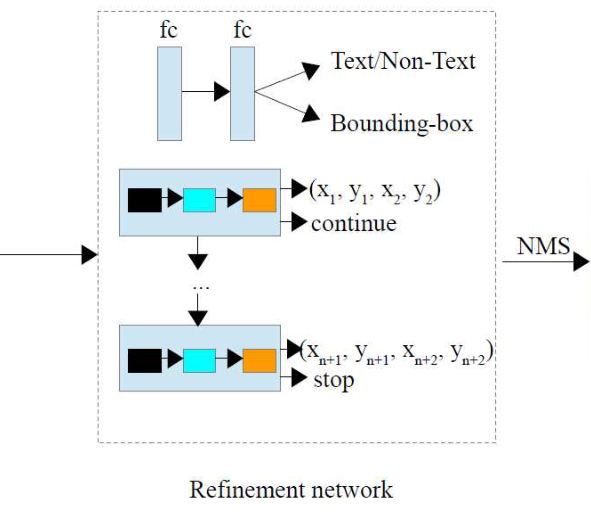
图6 细化网络
该分支输入的是文本提议的特征,输出的是每个文本区域边界上自适应成对点数量和坐标。文本提议的特征是通过使用 ROI 池和 SE-VGG16 生成的 CNN 特征图获得的。使用长短期存储(LSTM)学习文本区域表示。LSTM 中每个时间步骤的输入是相应文本提案的 ROI 池特征。
由于不同的文本区域点数不同,因此需要停止标签来表示预测网络何时停止。停止标签预测是分类问题,坐标预测是回归问题。所以一个 LSTM 有两个分支:一个用于坐标回归,一个用于停止标签预测。如果标签继续,则在下一时间步骤中预测另两个点的坐标和新坐标。否则,停止预测,文本区域用之前预测的所以成对点表示。
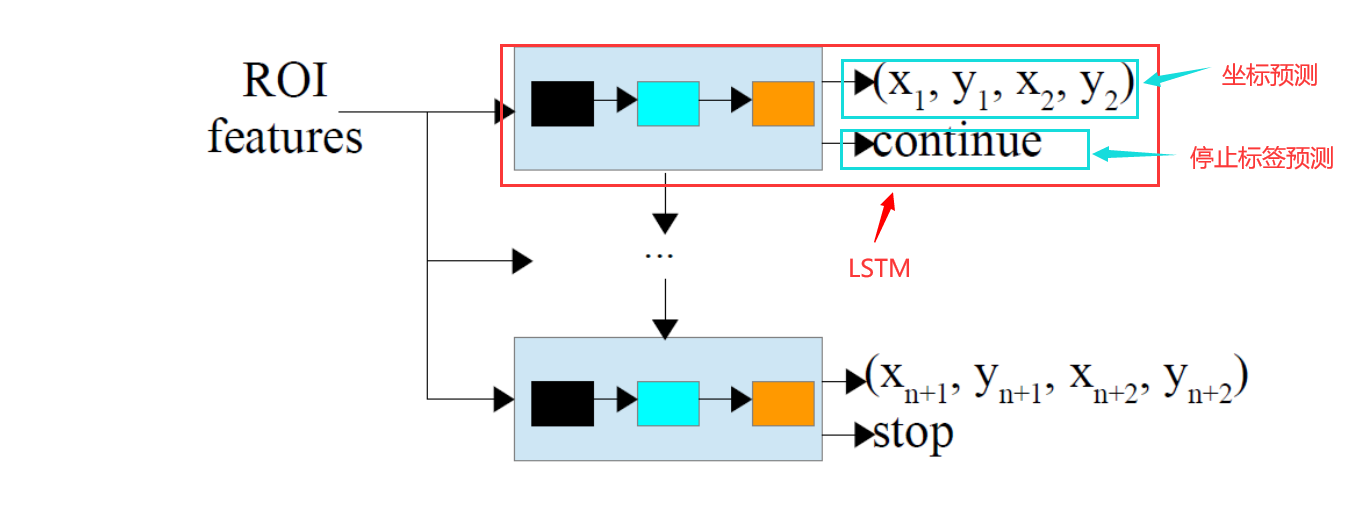
图7
成对边界点的两种表示方式:
。通过这种方式,成对点的坐标被用作回归目标,如图7所示。
、
和
。
为成对边界点的中心坐标,
是到它们的距离,
为方向(角度)。
方法2中,角度在某些特殊情况下并不稳定,这就使得网络很难很好的学习角度目标。所以,该方法使用点 的坐标作为回归目标。
4 损失函数
Text-RPN 与 Faster R-CNN 中的 RPN 相似,因此 Text-RPN 的训练损失也以与之相似的方式计算。本文关注细化网络的损失:文本/非文本损失、边界框回归损失、边界点回归损失和停止/继续标签分类损失的总和。 、
和
是控制这些项之间权衡的平衡参数,被设置为1。
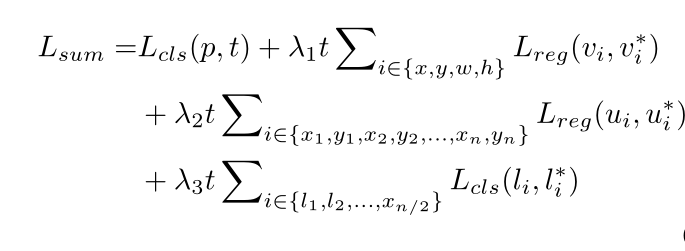
文本/非文本损失: t 是类别标签的指示符。文本: t=1; 非文本: t=0。p = () 是 softmax 之后计算的文本和背景类的概率。
边界框回归损失:v = () 是包含中心点坐标、宽度和高度的真实边界框回归目标的元组,
= (
) 是每个文本提案的预测元组。本文使用 Faster R-CNN 中给出的 v 和
的参数化,其中 v 和
指定了相对于对象建议的比例不变平移和对数空间高度/宽度偏移。
边界点回归损失: 真实边界点坐标的元组;
文本标签的预测点的元组。为了使所学习的点适用于不同尺度的文本,还应该处理学习目标以使它们尺度不变。参数
处理如下:
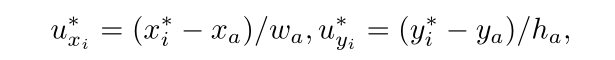
其中, 和
表示边界点的坐标,
和
表示相应文本提案的中心点坐标,
和
表示该提案的宽度和高度。
停止/继续标签分类损失:设 表示
或者
,
定义为平滑
损耗,如 Faster R-CNN所示:
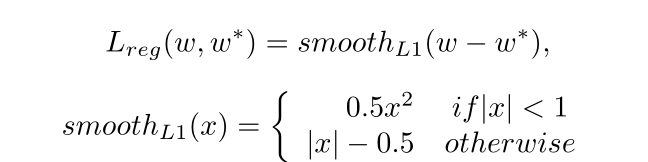
对于停止/继续标签分类损失术语,它也是一种二进制分类,其损失的格式类似于文本/非文本分类损失。
5 实验及结果
略