NeRF必读:NeuS--三维重建的milestone以及脑补的作者脑回路

前言
NeRF从2020年发展至今,仅仅三年时间,而Follow的工作已呈井喷之势,相信在不久的将来,NeRF会一举重塑三维重建这个业界,甚至重建我们的四维世界(开头先吹一波)。NeRF的发展时间虽短,有几篇工作却在我研究的领域开始呈现万精油趋势:
- PixelNeRF----泛化法宝
- MipNeRF----近远景重建
- NeRF in the wild----光线变换下的背景重建
- Neus----用NeRF重建Surface
- Instant-NGP----多尺度Hash编码实现高效渲染
Why NeuS?
基于二维图片的三维重建是计算机视觉中最核心的任务之一,传统方法的发展目前已经收敛于某种上限。从视觉中提取出物体的三维信息并将其直接用于三维重建是一项富有挑战但非常有实际意义的工作,得益于NeRF惊人的新视角合成效果,作者在NeRF的基础上提出了重建物体Surface的模型并在数据集上取得了理想的效果。NeuS打开了三维重建新方法的大门,此后有很多重量级工作都在NeuS的基础上展开,相信Follow的工作还会源源不断。

Method
输入:
给定一个序列的带位姿的图片 { I k } \\{\\mathcal{I}_k\\} {Ik},这些图片中包含了同一个物体 O \\mathcal{O} O(这也是后面论文可以改进的点)
输出:
对物体 O \\mathcal{O} O surface的重建结果
Surface Representation
原文叫做Scene Representation, 我的拙见是Surface Representation更直观些:
S = { x ∈ R 3 ∣ f ( x ) = 0 } \\mathcal{S}=\\{\\mathbf{x} \\in \\mathbb{R}^3 | f(\\mathbf{x})=0\\} S={x∈R3∣f(x)=0}
这里借用了level set的概念, f ( x ) f(\\mathbf{x}) f(x)是仅在被观测物体表面上 f ( x ) = 0 f(\\mathbf{x})=0 f(x)=0的函数,该函数可以用一个神经网络表征, 文中将其命名为SDF Network。那么问题来了,如何将这个SDF Network函数和NeRF建立关联,从而能够利用NeRF的损失函数优化surface的表征 SDF Nertwork呢?这一点是本文最核心的创新点
脑补版本作者脑回路开始
现在,我们来假想一下作者的脑回路:
- 观察经典NeRF的Volume Rendering Formula:
C ^ ( o , v ) = ∫ t n t f T ( t ) σ ( p ( t ) ) c ( p ( t ) , v ) d t where p ( t ) = o + t v \\mathbf{\\hat{C}(\\mathbf{o,v})}=\\int^{t_f}_{t_n}T(t)\\sigma(p(t))\\mathbf{c}(p(t),\\mathbf{v})dt \\\\ \\text{where} \\space p(t)=\\mathbf{o}+t\\mathbf{v} C^(o,v)=∫tntfT(t)σ(p(t))c(p(t),v)dtwhere p(t)=o+tv - 看来看去,公式里面只有 σ ( p ( t ) ) \\sigma(p(t)) σ(p(t))可以和 f ( x ) f(\\mathbf{x}) f(x)建立关联,这也符合大多数人的直觉。
- 问:怎样才能找到一个映射满足 f ( t ) → σ ^ ( t ) f(t)\\rightarrow \\hat{\\sigma}(t) f(t)→σ^(t),并且 σ ^ ( t ) \\hat{\\sigma}(t) σ^(t)还是能满足经典NeRF中 σ ( t ) \\sigma(t) σ(t)的特性使得该神经网络也能描述空间的体密度分布呢?
- 答:要使体密度描述准确,至少要满足下界: 在surface表面或者附近体密度最大(即当 f ( x ) = 0 f(\\mathbf{x})=0 f(x)=0时, σ ( x ) \\sigma(\\mathbf{x}) σ(x)同时也达到最大值,对应文中的性质Unbiased)
- 问:什么函数在x=0时,值最大,且在x<0时递增,在x>0时递减呢:Sigmoid的导数,logistic density distribution就还不错,先上图:

现在我们有了体密度函数的表达式
ϕ s ( u ) = s e − s u / ( 1 + e − s u ) u = f ( x ) \\phi_s(u)=se^{-su}/(1+e^{-su})\\\\ u=f(x) ϕs(u)=se−su/(1+e−su)u=f(x)
一顿操作猛如虎,现在将得到的这个体密度表达 ϕ s ( f ( x ) ) \\phi_s(f(x)) ϕs(f(x))命名为S-denstiy,将 S − d e n s i t y S-density S−density带入Rendering Formula得:
C ^ ( o , v ) = ∫ t n t f T ( t ) ϕ s ( f ( p ( t ) ) ) c ( p ( t ) , v ) d t where p ( t ) = o + t v \\mathbf{\\hat{C}(\\mathbf{o,v})}=\\int^{t_f}_{t_n}T(t)\\phi_s(f(p(t)))\\mathbf{c}(p(t),\\mathbf{v})dt \\\\ \\text{where} \\space p(t)=\\mathbf{o}+t\\mathbf{v} C^(o,v)=∫tntfT(t)ϕs(f(p(t)))c(p(t),v)dtwhere p(t)=o+tv
令 ω ( t ) = T ( t ) ϕ s ( f ( p ( t ) ) ) \\omega(t)=T(t)\\phi_s(f(p(t))) ω(t)=T(t)ϕs(f(p(t))),就得到了原文中Naive的solution, 为啥时Naive呢,很多读者都懵了,不是公式都推完了吗?
因为我们犯了一个致命错误:我们需要做到Unbiased的变量并非 σ ( t ) \\sigma(t) σ(t),而是 ω ( t ) = T ( t ) σ ( t ) \\omega(t)=T(t)\\sigma(t) ω(t)=T(t)σ(t)!,前面的推导我们是不考虑Occlusion-Awared的,也就是文中 ω ( t ) \\omega(t) ω(t)函数需要满足的第二个性质,体密度相同,但距离相机的距离不同时,分配给该点像素的权重是应该不一样的,否则会有歧义性。一句话:前面对Unbiased的推导没考虑 T ( t ) T(t) T(t)的影响。那么实际上 T ( t ) T(t) T(t)的加入会对Naive的分布产生影响吗,作者给出了图,确实产生了影响!Naive solution虽然带有Occlusion Awared,但是 ω ( t ) \\omega(t) ω(t)不再是unbiased的了,如左下图所示, ω ( t ) \\omega(t) ω(t)的极点并非surface所在平面,更偏左一些:
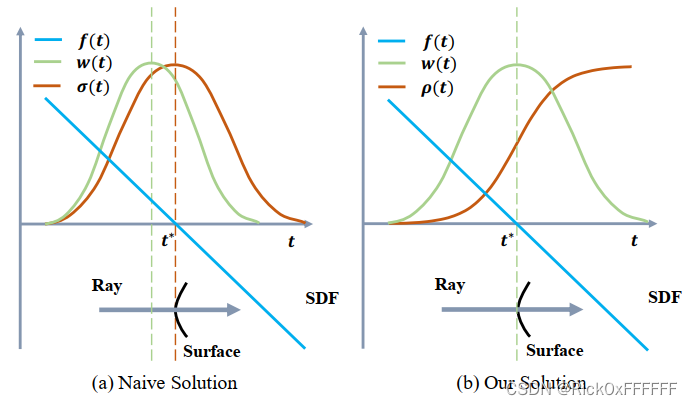
- 问:如何规避这个问题呢?我们能构造一个 ω ( t ) \\omega(t) ω(t)同时满足Unbiased 和Occulusion-Aware两个性质吗?
- 答:想个办法让 ω ( t ) = \\omega(t)= ω(t)=logistic density distribution*呗~
- 问:那Occlusion-Aware呢
- 答:直白的说就是 T ( t ) σ ( t ) = T(t)\\sigma(t)= T(t)σ(t)=logistic density distribution, T ( t ) T(t) T(t)就是Occlusion Aware了。 好家伙,这样就能做到Unbiased的同时,又能够描述Occlusion-Aware了。但是Naived logistic density distribution是不满足求和为1的,所以呢作者做了一个归一化:
ω ( t ) = ϕ s ( f ( p ( t ) ) ) ∫ 0 + ∞ ϕ s ( f ( p ( t ) ) ) d u \\omega(t)=\\frac{\\phi_s(f(\\mathbf{p}(t)))}{\\int^{+\\infty}_0 \\phi_s(f(\\mathbf{p}(t)))du} ω(t)=∫0+∞ϕs(f(p(t)))duϕs(f(p(t)))
令 ω ( t ) = T ( t ) ρ ( t ) \\omega(t)=T(t)\\rho(t) ω(t)=T(t)ρ(t),且 T ( t ) = exp ( − ∫ 0 t ρ ( u ) d u ) T(t)=\\exp(-\\int^t_0\\rho(u)du) T(t)=exp(−∫0tρ(u)du),直接根据这个公式求解出 T ( t ) T(t) T(t)和 ρ ( t ) \\rho(t) ρ(t)即可,至此作者完成了NeRF与surface reconstruction的完美结合!
脑补版本作者脑回路完毕
总结
作者为了使得 ω ( t ) \\omega(t) ω(t)无偏,将logistic density distribution硬分解成了透射率 T ( t ) T(t) T(t)和体密度 ρ ( t ) \\rho(t) ρ(t),好一个霸王硬上弓!
硬上弓还要讲究策略
本节讲述作者如何将 ω ( t ) \\omega(t) ω(t)分解为 T ( t ) T(t) T(t)和 ρ ( t ) \\rho(t) ρ(t),吃个晚饭再写。