大数据之Spark入门案例

文章目录
- 前言
- 一、案例简介
- 二、前期准备
- 三、代码开发
- 四、运行结果
- 总结
前言
#博学谷IT学习技术支持#
上篇文章主要介绍了PySpark开发环境的搭建,接下来就是Spark的入门案例,通过入门案例进一步了解Spark的运行逻辑,开发环境的搭建可以参考文章:Spark开发环境准备、Spark环境搭建
一、案例简介
PySpark入门案例读取HDFS上的csv文件,csv文件中有很多单词,每个单词以空格隔开,运行PySpark程序,计算出csv文件中每个单词的数量。
二、前期准备
本次演示的代码计算部分由Spark负责,资源调度由Hadoop的Yarn负责,代码开发之前需要保证:
-
Hadoop集群的正常运行
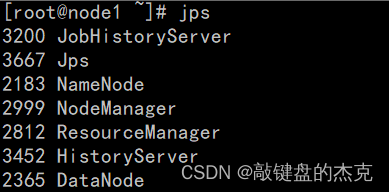
-
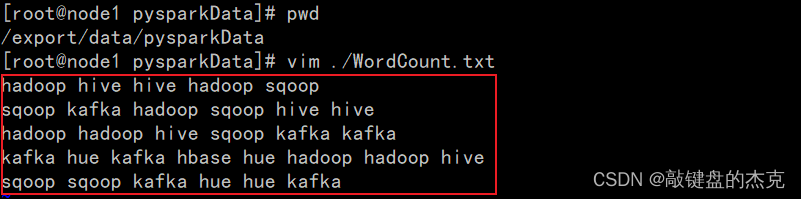
将需要读取的txt文件上传到HDFS上,
(1)WordCount文件内容
(2)上传的HDFS中的地址

三、代码开发
本次入门案例首先先创建Spark的核心对象SparkContext,接着使用PySpark的textFile、flatMap、Map,reduceByKey等API,这四个API结合起来的作用是:
(1)先读取存储在HDFS上的文件,
(2)由于Spark处理数据是一行一行处理,所以使用flatMap将每一行按照空格进行拆分
(3)接着使用map将拆分后的单词按照(Word,1)key-value的形式组装起来
(4)然后使用reduceByKey按照key进行汇总
详细代码如下:
from pyspark import SparkContext,SparkConf
import os
# 锁定远端环境, 确保环境统一
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'if __name__ == '__main__':print("WordCount入门案例")# 1. 创建Spark核心对象SparkContextprint("第一步:创建Spark核心对象SparkContext")spark_Conf = SparkConf().setAppName("WordCount").setMaster("local[*]")spark = SparkContext(conf=spark_Conf)# 2.读取HDFS上的WordCount文件print("第二步:读取HDFS上的WordCount文件")filePath = "hdfs://node1:8020/pyspark/wordcount/input/WordCount.txt"rdd_ini = spark.textFile(name=filePath)print(rdd_ini.collect())# 3.将每一行中的Word按照空格进行拆分print("第三步:将每一行中的Word按照空格进行拆分")rdd_flatmap = rdd_ini.flatMap(lambda line:line.split(" "))print(rdd_flatmap.collect())# 4.将每一个单词转换成(Word,1)Key-Value的形式print("第四步:将每一个单词转换成(Word,1)Key-Value的形式")rdd_map = rdd_flatmap.map(lambda word:(word,1))print(rdd_map.collect())# 5.将(word,1)按照key进行汇总print("第五步:将(word,1)按照key进行汇总")rdd_reduce = rdd_map.reduceByKey(lambda agg,curr:agg+curr)print(rdd_reduce.collect())# 6.停止spark,释放资源print("第六步:停止spark,释放资源")spark.stop()
四、运行结果
运行结果大致如下:

总结
PySpark提供了大量的API,使得数据处理起来比较方便快捷,有时一行代码就能处理很复杂的逻辑,最主要的就是得了解每一个API底层的运行逻辑,从而能够更加熟练的使用相关API。