大数据技术(入门篇)--- 使用Spring Boot 操作 CDH6.2.0 Spark SQL进行离线计算

前言
CDH 6.2.0 搭建的环境,并不能直接使用 spark 相关资源,需要对此服务端环境进行一些修改Spark 目前仅支持 JDK1.8, Java项目运行环境只能使用JDK 1.8我这里使用的是 CDH6.2.0集群,因此使用的依赖为CDH专用依赖,需要先添加仓库spark 使用scala 语言编写,因此项目中使用的scala依赖版本要和cdh中的 scala 版本一致因为需要将计算结果写入到MySQL,所以当前项目中需要加入MySQL-JDBC驱动程序Spark 在运行过程中,会将JAR上传到节点,进行网络传输,因此,Spark计算类,必须实现序列化接口 java.io.Serializable,同时设置序列化id( private static final long serialVersionUID = 1L;),如果不知道怎么设置,那就默认值1L,每次更新代码,切记 maven clean package,缺一不可Spark 在进行RDD计算的时候,可能会在集群中的任一节点上,因此每个节点也需要有 MySQL的JDBC驱动程序,否则无法创建数据库表,我这里用了偷懒的方式,将JAR上传到HDFS,通过配置文件进行加载启动
代码库地址:https://github.com/lcy19930619/cdh-demo
环境处理
步骤一:添加 spark 基础环境
步骤二,处理对应的 master 和 slave 节点
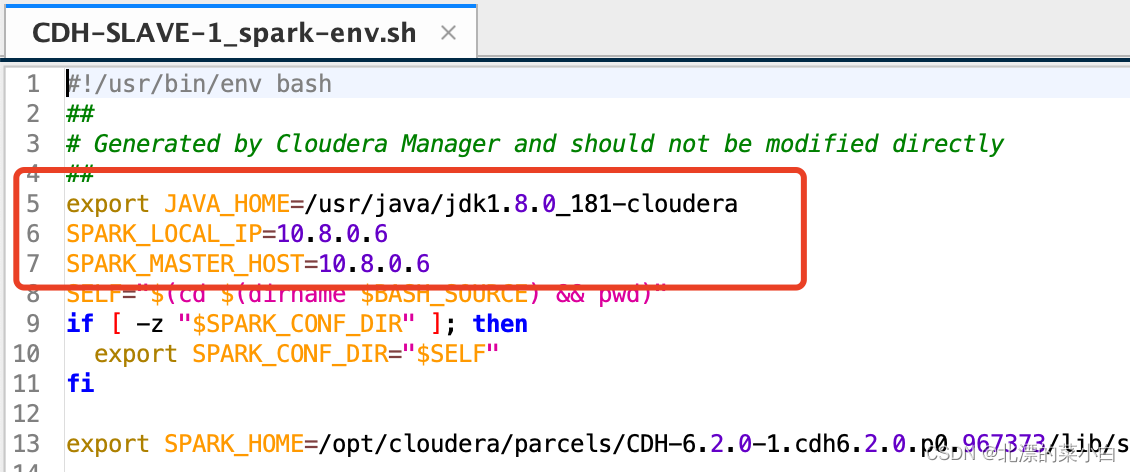
修改基础环境配置文件
文件:/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/spark/conf/spark-env.sh
在文件上方添加以下内容
export JAVA_HOME=/usr/java/jdk1.8.0_181-cloudera # jdk 路径
SPARK_LOCAL_IP=10.8.0.6 # 此ip为我的远程访问ip地址,spark 默认只处理链接此ip的数据
SPARK_MASTER_HOST=10.8.0.6 # master 节点ip地址
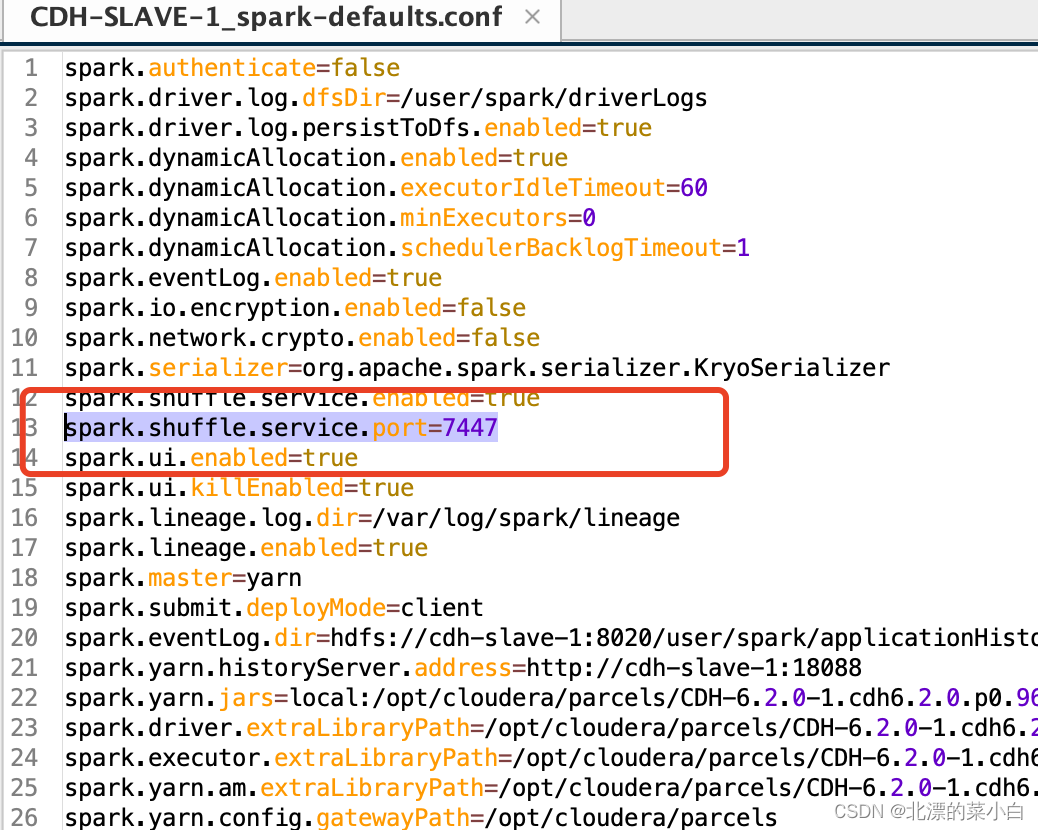
修改端口
文件:/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/spark/conf/spark-defaults.conf
修改内容:
将 7337 端口修改为 7447
spark.shuffle.service.port=7447
分别启动节点
文件路径:/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/spark/sbin
启动 master 执行:
./start-master.sh
启动 slave 执行:
./start-slaves.sh # 注意,这个脚本是有 s 的,还有一个是start-slave.sh,别启动错了
确认正常启动
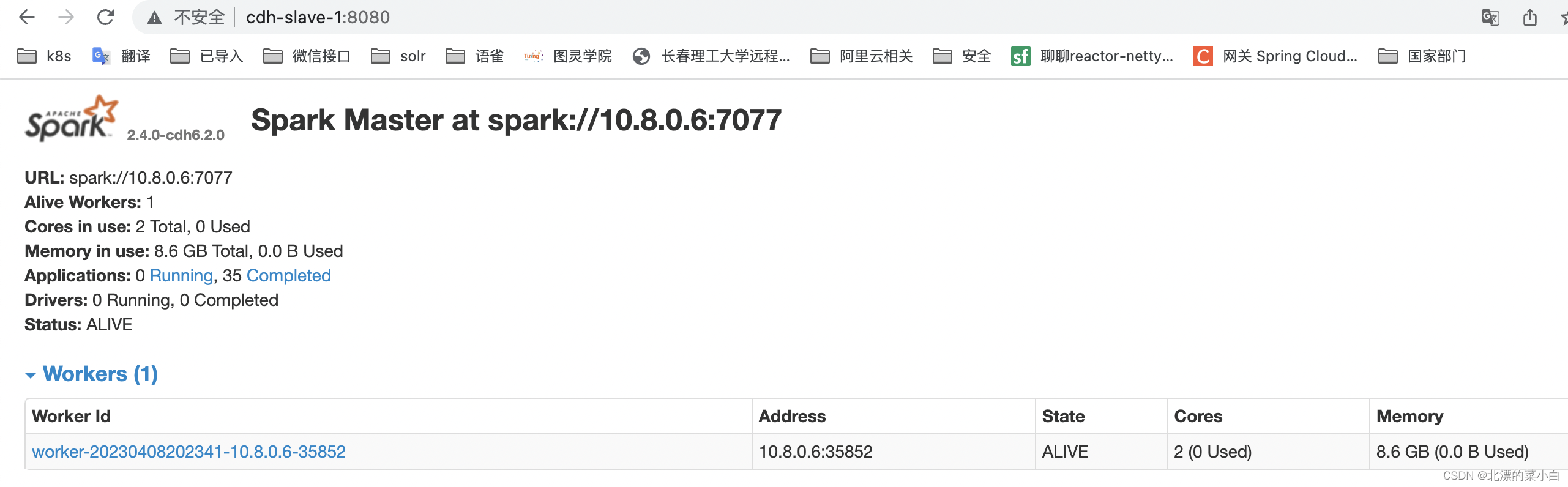
了解 Spark
- Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室) 所开源的
类Hadoop MapReduce的通用并行框架 - 拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是——
Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。 - Spark 比 MapReduce 快,MapReduce只能进行离线运算,并且需要完全依靠HDFS,数据需要从磁盘加载,然后才能进行计算,因此MapReduce速度较慢,但Spark可以将计算结果存储到内存中,也可以进行流式计算,因此速度比MapReduce 快
- Spark 提供了大量的库,包括Spark Core、Spark SQL、Spark Streaming、MLlib、GraphX。 开发者可以在同一个应用程序中无缝组合使用这些库。
- Spark 支持 Hadoop YARN,Apache Mesos,及其自带的独立集群管理器
组件
-
SparkCore:相当于MapReduce,是spark的核心引擎。
-
SparkSQL:是一个用于处理结构化数据的Spark组件,主要用于结构化数据处理和对数据执行类SQL查询。可以针对不同数据格式(如:JSON,Parquet, ORC等)和数据源执行ETL操作(如:HDFS、数据库等),完成特定的查询操作。
-
SparkStreaming:微批处理的流处理引擎,将流数据分片以后用SparkCore的计算引擎中进行处理,可以进行实时运算。
-
Mllib和GraphX主要一些机器学习和图计算的算法库。
-
SparkR是一个R语言包,它提供了轻量级的方式使得可以在R语言中使用 Spark。

Spark数据结构
在Spark中,数据以RDD或者DataFrame的格式储存。
RDD
RDD 是 Spark 中最重要的概念之一,全称为 Resilient Distributed Dataset,即弹性分布式数据集。它是一种容错、可并行计算的数据类型,可以跨多个节点进行分布式计算。RDD 是 Spark 提供的核心分布式数据结构,可以通过一系列的转换和动作(operation)进行处理,从而实现大规模数据处理。
在 Spark 中,RDD 表示一个不可变、可分区、支持并行操作的数据集合,每个 RDD 可以被分为多个分区,这些分区可以被放置在不同的节点上,使得计算可以在节点间并行进行。用户可以通过一系列的操作来构建和转换 RDD。
RDD 的特点如下:
-
以分布式方式存储在多个节点上,通过网络进行传输,可以实现高效的数据计算和处理。
-
支持多种数据来源,例如 HDFS, HBase, Cassandra 等大规模数据存储系统。
-
可以容错并快速恢复,当某个节点失败或数据损坏时,RDD 可以快速恢复原始数据。
-
支持多种操作,例如转换(transformation)和动作(action),可以在 RDD 上进行各种复杂的数据处理、过滤、排序等操作。
DataFrame
DataFrame 是 Spark SQL 中内置的、分布式的数据处理结构。它可以看做是基于 RDD 的分布式数据集合,但相对于 RDD,DataFrame 提供了更高层次的抽象,使得数据处理更加方便、高效。DataFrame 可以将不同数据源中的数据统一表示为一个分布式的表格,提供了一套 SQL 的查询语言,支持丰富的数据转换以及数据分析处理功能。
与 RDD 不同的是,DataFrame 中的数据结构是由一组命名的列组成的,支持多种数据类型,并且可以自动推断数据模式(schema)。而且 DataFrame 中的数据都是以列存储的,因此可以更加高效地进行数据压缩和编码,提高数据处理的速度和效率。除此之外,DataFrame 还提供了很多类似于 SQL 的数据操作方法,例如 select, filter, groupBy, orderBy 等等。
使用 DataFrame 可以更加方便地进行数据处理工作,将常用的大部分复杂计算交给 Spark SQL 来处理,而不需要过多地自己实现。
例如,在 Spark SQL 中可以读取各种结构化数据(如 JSON, CSV, parquet 等等),然后使用 DataFrame API 进行数据查询、筛选、聚合甚至机器学习算法的处理。在某些情况下,DataFrame 甚至可以代替编写 MapReduce 作业来处理数据。
Dataset
在 Spark 中,Dataset 是一种强类型的、可分布式处理的数据集合,可以运用 Spark 的函数式编程方式,提供了更加方便、稳定的 API 接口,支持如 SQL 语法风格的查询,也可以与原生 Scala、Java 等语言的 API 紧密结合,支持对各种数据源的读取和写入等操作。
Dataset 实现了两个经典的 Spark 数据结构:RDD 和 DataFrame。与 RDD 相比,Dataset 提供了更加高级的类型约束和更好的性能优化,可以在编译期间捕获类型错误,并且能够利用 Catalyst(Spark 的高性能查询优化器)对查询语句进行优化。
与 DataFrame 相比,Dataset 不仅支持强类型编程,还支持面向对象编程。可以通过编写强类型类来指定数据结构,支持使用标准 Scala、Java 类型检查器进行检查,避免了在运行时出现类型不匹配的错误。
一次Spark Job的运行过程简述
-
配置与初始化。在这个阶段中,Spark 根据用户设定的配置信息,对集群进行初始化,并加载用户指定的代码和依赖项。这个阶段还包括 Spark 上下文的创建和运行环境的初始化等操作。
-
转换与优化。在这个阶段中,Spark 根据用户设定的代码和数据输入,进行一系列的转换和优化操作,包括分区、排序、过滤、聚合等操作。Spark 会根据 DAG (Directed Acyclic Graph) 的形式将转换操作组织起来,并进行逻辑优化和物理优化。
-
计算与执行。在这个阶段中,Spark 根据 DAG 的构建结果,将代码和数据输入根据 DAG 拆分为多个阶段,并按照计算依赖关系进行并行计算和执行。Spark 会在集群中的多个节点上运行任务,从而实现高效的数据并行处理。
-
结果输出和保存。在这个阶段中,Spark 将计算结果进行输出和保存,可以将结果保存到内存、磁盘或是外部存储系统中(如 HDFS, S3, HBase 等)。可以通过 API 代码或 Spark SQL 等途径直接与结果进行交互和查询。
运行角色
在 Spark 集群中,有以下几个运行角色:
-
Driver:Driver 是整个 Spark 应用程序的主类,通过调用 SparkContext 来创建 RDD 并且定义数据处理流程。Driver 维护着集群任务的整体状态、资源分配和任务调度等职责,是整个应用的控制节点。
-
Executor:Executor 是 Spark 中真正执行任务的角色,每个应用程序启动时,Spark 会为每个节点分配一个或多个 Executor,Executor 会在该节点上负责执行分配给它的任务,包括数据的计算和转换、计算结果的缓存和存储、以及任务的监控和重试等职责。
-
Cluster Manager:Cluster Manager 是 Spark 集群的管理组件,负责分配和管理集群的资源、监控集群的状态和健康状况、处理节点的故障和重启等职责。Spark 支持多种 Cluster Manager,包括 Standalone、Mesos、YARN、Kubernetes 等。
-
Worker:Worker 是 Spark 集群中的节点,可以是物理机、虚拟机或 Docker 容器等,它们负责提供计算和存储资源、启动和运行 Executor、定期向 Cluster Manager 汇报节点状态等职责。
-
Client:Client 是 Spark 应用程序的启动者,负责启动 Driver 进程,向 Cluster Manager 请求计算资源、提交应用程序代码等职责。通常来说,Client 与 Driver 运行在同一台机器上。
常用的配置参数
SparkConf 是 Spark 配置的核心类,你可以使用 SparkConf 配置类来设置 Spark 应用程序的各种参数。下面是一些常见的 SparkConf 配置参数及其说明:
spark.master: 指定 Spark 应用程序运行在哪个集群(Standalone、Mesos 或 YARN)的哪个节点上,以及运行模式(local、client 或 cluster);示例:spark://master:7077(集群模式)或local[*](本地模式)。spark.app.name: 指定应用程序的名称,方便在 Spark Web UI 和日志中定位;示例:MyApp。spark.driver.memory: 指定 Driver 程序占用的内存大小,包括 JVM Heap 和其他内存(如 I/O 缓存);示例:2g。spark.executor.memory: 指定 Executor 程序占用的内存大小,包括 JVM Heap 和其他内存(如 I/O 缓存);示例:4g。spark.executor.instances: 指定 Spark 应用程序启动的 Executor 数量;示例:10。spark.executor.cores: 指定每个 Executor 占用的 CPU 核数;示例:4。spark.default.parallelism: 指定默认的并行度,通常和数据分区数保持一致;示例:100。spark.sql.shuffle.partitions: 指定 Spark SQL Shuffle 操作的默认并行度,通常和数据分区数保持一致;示例:100。spark.hadoop.fs.s3a.endpoint: 指定 Object Store 的访问地址;示例:s3.amazonaws.com。spark.hadoop.fs.s3a.access.key: 指定 Object Store 的访问 Key;示例:AKIATXDGSSAACXEXAMPLE。spark.hadoop.fs.s3a.secret.key: 指定 Object Store 的访问 Secret;示例:wJalrXUtnFEMI/K7MDENG+bPxRfiCYEXAMPLEKEY。
除了上面列出的常用配置参数外,还有许多其他的配置参数,
以下是 Spark 官方文档的链接:
- Spark 配置指南
- Spark SQL 配置指南
- Spark Streaming 配置指南
在这些文档中,可以找到 Spark 所有模块的配置参数,包括 Spark Core、Spark SQL、Spark Streaming、机器学习库 MLlib 等。同时,这些文档还提供了每个配置参数的用途、默认值和可用值范围等信息。
代码编写
查看scala 版本和 spark 版本
登陆 Spark Master 服务器
# 找到执行 spark-shell 的目录
cd /opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/spark/bin
# 执行该命令
./spark-shell
观察执行结果
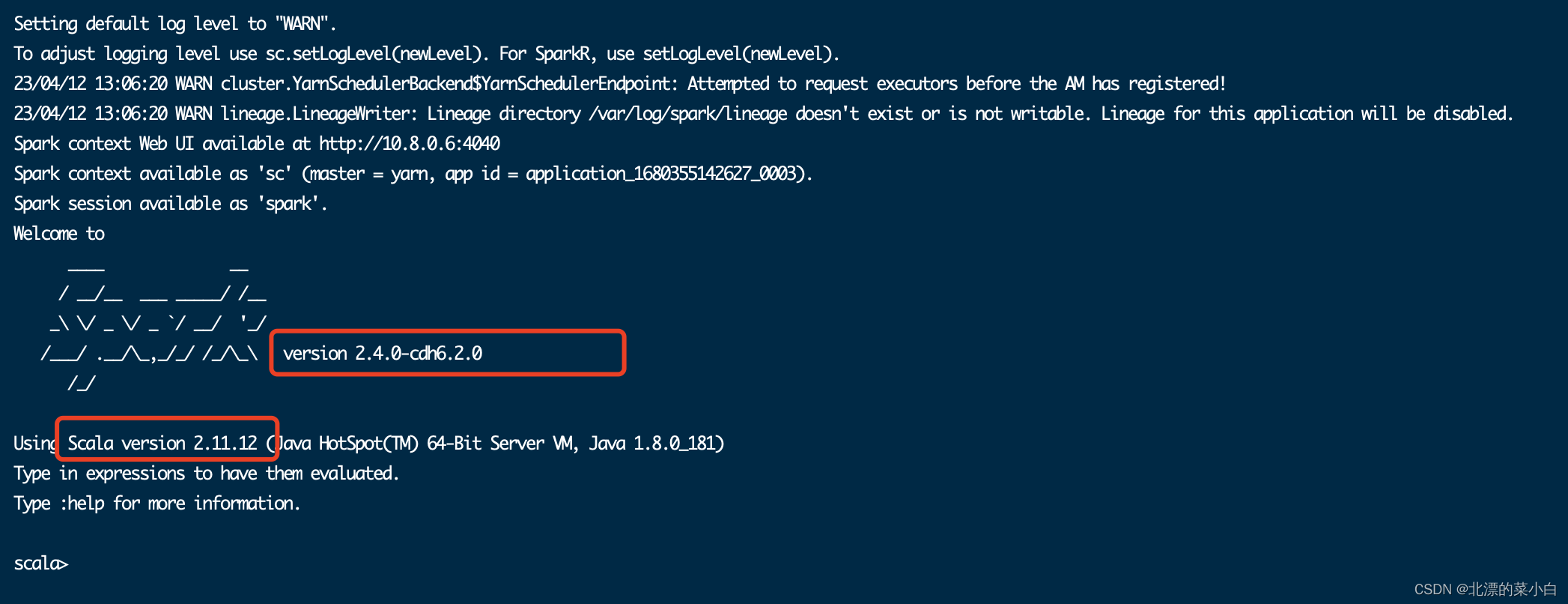
Spark version: 2.4.0-cdh6.2.0
Scala version: 2.11.12
pom.xml
已知 Scala 版本,和 spark 版本,所以针对性的添加依赖文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.example</groupId><artifactId>cdh-demo</artifactId><version>0.0.1-SNAPSHOT</version><name>cdh-demo</name><description>cdh-demo</description><properties><java.version>1.8</java.version><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding><spring-boot.version>2.6.13</spring-boot.version><cdh.version>2.4.0-cdh6.2.0</cdh.version><scala.version>2.11.12</scala.version><hadoop.version>3.0.0-cdh6.2.0</hadoop.version></properties><dependencies><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId></dependency><!-- scala 依赖 开始 --><dependency><groupId>org.scala-lang</groupId><artifactId>scala-library</artifactId><version>${scala.version}</version></dependency><dependency><groupId>org.codehaus.janino</groupId><artifactId>janino</artifactId><version>3.0.8</version></dependency><!-- scala 依赖 结束--><!-- spark 依赖 开始--><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.11</artifactId><version>${cdh.version}</version><exclusions><exclusion><artifactId>slf4j-reload4j</artifactId><groupId>org.slf4j</groupId></exclusion></exclusions></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql_2.11</artifactId><version>${cdh.version}</version></dependency><dependency><groupId>com.databricks</groupId><artifactId>spark-xml_2.12</artifactId><version>0.11.0</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming-kafka-0-10_2.11</artifactId><version>${cdh.version}</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming_2.11</artifactId><version>${cdh.version}</version></dependency><!-- spark 依赖 结束--><dependency><groupId>org.glassfish.jersey.inject</groupId><artifactId>jersey-hk2</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-configuration-processor</artifactId></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>${hadoop.version}</version><exclusions><exclusion><artifactId>slf4j-reload4j</artifactId><groupId>org.slf4j</groupId></exclusion></exclusions></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-hdfs</artifactId><version>${hadoop.version}</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-mapreduce-client-core</artifactId><version>${hadoop.version}</version><exclusions><exclusion><artifactId>slf4j-reload4j</artifactId><groupId>org.slf4j</groupId></exclusion></exclusions></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-mapreduce-client-jobclient</artifactId><version>${hadoop.version}</version><exclusions><exclusion><artifactId>slf4j-reload4j</artifactId><groupId>org.slf4j</groupId></exclusion></exclusions></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-mapreduce-client-common</artifactId><version>${hadoop.version}</version><exclusions><exclusion><artifactId>slf4j-reload4j</artifactId><groupId>org.slf4j</groupId></exclusion></exclusions></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-configuration-processor</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency></dependencies><dependencyManagement><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-dependencies</artifactId><version>${spring-boot.version}</version><type>pom</type><scope>import</scope></dependency></dependencies></dependencyManagement><build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>3.8.1</version><configuration><source>1.8</source><target>1.8</target><encoding>UTF-8</encoding></configuration></plugin><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId><version>${spring-boot.version}</version><configuration><mainClass>com.example.cdh.CdhDemoApplication</mainClass><skip>true</skip></configuration><executions><execution><id>repackage</id><goals><goal>repackage</goal></goals></execution></executions></plugin></plugins></build><repositories><repository><id>cloudera.repo</id><url>https://repository.cloudera.com/artifactory/cloudera-repos/</url></repository><repository><id>spring</id><url>https://maven.aliyun.com/repository/central</url></repository><repository><id>jcenter</id><url>https://maven.aliyun.com/repository/jcenter</url></repository><repository><id>public</id><url>https://maven.aliyun.com/repository/public</url></repository></repositories>
</project>yml
spark:jars:# 当前 JAR 的名字,支持相对路径,如果使用匿名内部类,会生成$1的class,不添加jar,会出现ClassNotFoundException- target/cdh-demo-0.0.1-SNAPSHOT.jarapp-name: cdh-demomaster-url: spark://cdh-slave-1:7077driver:memory: 1ghost: 10.8.0.5# JDBC 驱动地址,手动上传到 hdfs 的extraClassPath: hdfs://cdh-slave-1:8020/jars/mysql-connector-java-5.1.47.jarworker:memory: 1gexecutor:memory: 1grpc:message:maxSize: 1024logging:level:org:apache:spark:storage: WARNdeploy:client: WARNscheduler:cluster: WARN
hadoop:url: hdfs://cdh-slave-1:8020replication: 3blockSize: 2097152user: root
SparkAutoConfiguration
package com.example.cdh.configuration;import com.example.cdh.properties.spark.SparkProperties;
import java.util.List;
import java.util.Map;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.sql.SparkSession;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.autoconfigure.condition.ConditionalOnMissingBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.env.AbstractEnvironment;
import org.springframework.core.env.Environment;
import org.springframework.core.env.MapPropertySource;
import org.springframework.core.env.MutablePropertySources;
import org.springframework.core.env.PropertySource;/* @author lcy*/
@Configuration
public class SparkAutoConfiguration {private static final Logger logger = LoggerFactory.getLogger(SparkAutoConfiguration.class);@Autowiredprivate SparkProperties sparkProperties;@Autowiredprivate Environment env;/* spark 的基本配置 @return 把 yml 里配置的内容都写入该配置项*/@Beanpublic SparkConf sparkConf() {List<String> jars = sparkProperties.getJars();String[] sparkJars = jars.toArray(new String[0]);SparkConf conf = new SparkConf().setAppName(sparkProperties.getAppName()).setMaster(sparkProperties.getMasterUrL()).setJars(sparkJars);AbstractEnvironment abstractEnvironment = ((AbstractEnvironment) env);MutablePropertySources sources = abstractEnvironment.getPropertySources();for (PropertySource<?> source : sources) {if (source instanceof MapPropertySource) {Map<String, Object> propertyMap = ((MapPropertySource) source).getSource();for (Map.Entry<String, Object> entry : propertyMap.entrySet()) {String key = entry.getKey();if (key.startsWith("spark.")) {if ("spark.jars".equals(key)){continue;}String value = env.getProperty(key);conf.set(key,value);logger.info("已识别 spark 配置属性,{}:{}",key,value);}}}}// 也可以通过此方式设置 (方式二) 二选一即可// conf.set("spark.driver.extraClassPath","hdfs://cdh-slave-1:8020/jars/mysql-connector-java-5.1.47.jar");// 也可以通过此方式设置 (方式三) 二选一即可 // conf.set("spark.executor.extraClassPath","hdfs://cdh-slave-1:8020/jars/mysql-connector-java-5.1.47.jar");return conf;}/* 连接 spark 集群 @param sparkConf* @return*/@Bean@ConditionalOnMissingBean(JavaSparkContext.class)public JavaSparkContext javaSparkContext(SparkConf sparkConf) {return new JavaSparkContext(sparkConf);}/ @param javaSparkContext* @return*/@Beanpublic SparkSession sparkSession(JavaSparkContext javaSparkContext) {return SparkSession.builder().sparkContext(javaSparkContext.sc()).appName(sparkProperties.getAppName()).getOrCreate();}}踩坑记录
ClassNotFoundException:xxxxxx$1
异常信息截图
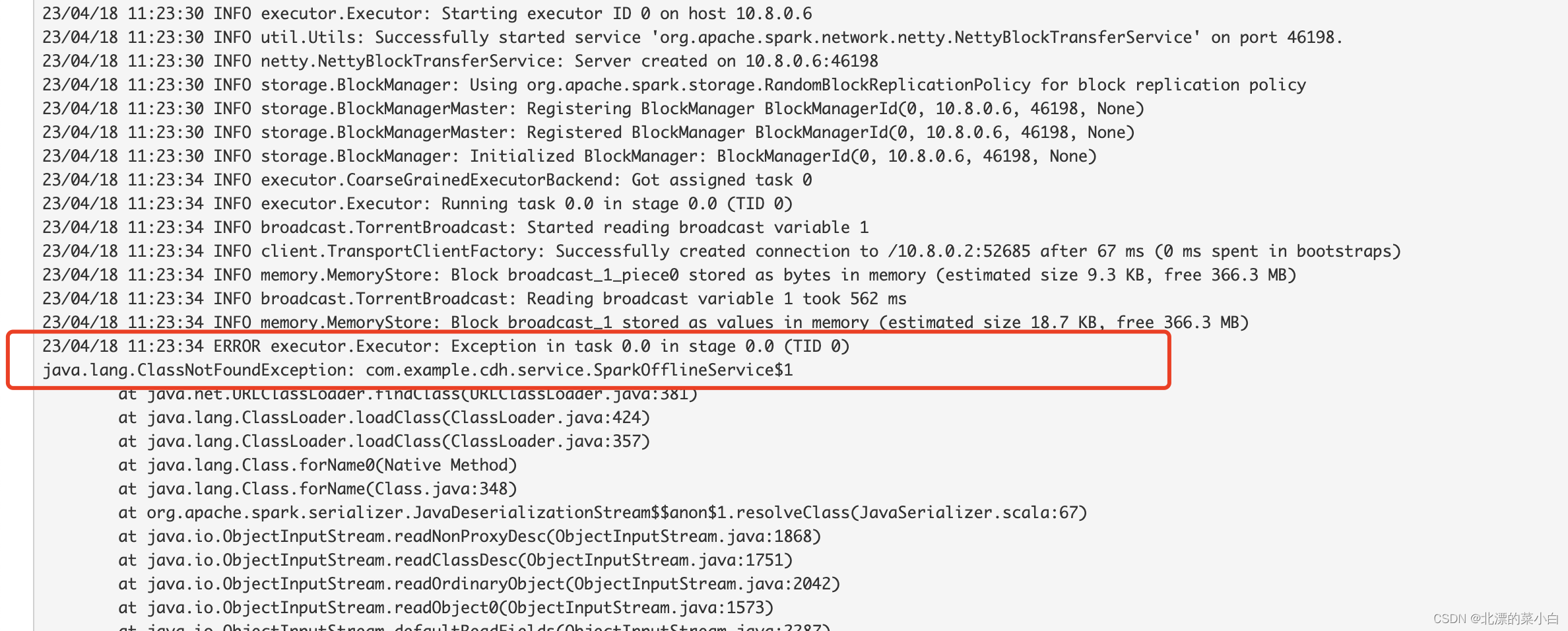
产生的原因分析
Spark 在执行过程中,会将jar 进行网络传输,但是代码中包含了匿名内部类,因此产生了$1这种后缀的class 文件
示例

解决方案
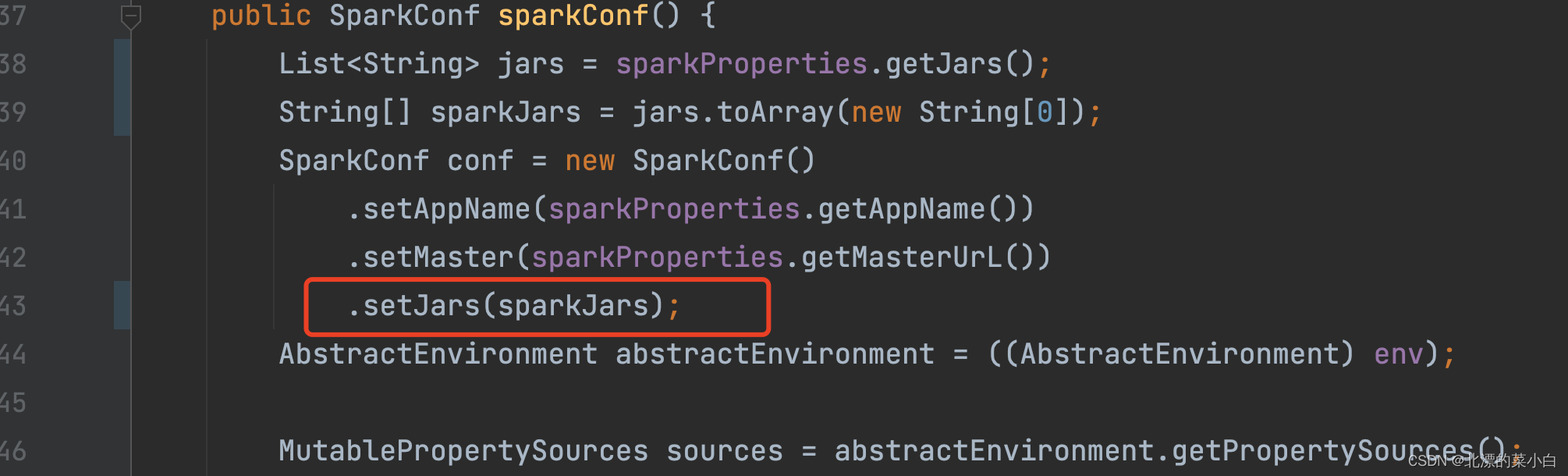
在装配时候,通过 setJars方法,添加当前的jar包作为传输对象,该路径可以为相对路径,或者 hdfs 路径

示例代码目标
使用 spark sql 进行简单的查询示例
- 简单的条件查询
- 稍微复杂一些的聚合查询
- 每行数据对象,转换为自定义Class对象
- 目标数据存储到MySQL数据库中
- 符合断言判断
package com.example.cdh.service;import com.example.cdh.dto.UserDTO;
import java.io.Serializable;
import org.apache.spark.api.java.function.MapFunction;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Encoders;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SaveMode;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.types.DataTypes;
import org.apache.spark.sql.types.StructField;
import org.apache.spark.sql.types.StructType;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;import static org.apache.spark.sql.functions.column;
import static org.apache.spark.sql.functions.count;/* 使用 spark sql 离线计算 @author chunyang.leng* @date 2023-04-12 14:53*/
@Component
public class SparkOfflineService implements Serializable {private static final Logger logger = LoggerFactory.getLogger(SparkOfflineService.class);private static final long serialVersionUID = 1L;@Autowiredprivate SparkSession sparkSession;/* 统计 hdfs 中一个csv文件的行数 @param hdfsPath demo: hdfs://cdh-slave-1:8020/demo/csv/input.csv* @return*/public long countHdfsCsv(String hdfsPath) {return sparkSession.read().csv(hdfsPath).count();}/* 小于等于 计算示例* <br/>* <pre>* {@code select name, age from xx where age <=#{age} }* </pre>* @param hdfsPath 要计算的文件* @param age 阈值* @return 算出来的数据总量*/public long lte(String hdfsPath, int age) {// 临时表名称String tempTableName = "cdh_demo_lte";// 加载 csv 数据Dataset<UserDTO> data = loadCsv(hdfsPath);// 创建临时表data.createOrReplaceTempView(tempTableName);// 执行 sql 语句Dataset<Row> sqlData = sparkSession.sql("select name,age from " + tempTableName + " where age <= " + age);// 存储数据saveToMySQL(tempTableName, sqlData);return sqlData.count();}/* 简单的聚合查询示例* <br/>* <pre>* {@code* select* count(name) as c,* age* from* xx* group by age having c > #{count} order by c desc* }* </pre>* @param hdfsPath 要统计的文件* @param count having > #{count}* @return*/public long agg(String hdfsPath, int count){// 临时表名称String tempTableName = "cdh_demo_agg";// 加载 csv 数据Dataset<UserDTO> data = loadCsv(hdfsPath);// 创建临时表data.createOrReplaceTempView(tempTableName);// 执行 sql 语句Dataset<Row> sqlData = sparkSession.sql("select name,age from " + tempTableName).groupBy(column("age").alias("age")).agg(count("name").alias("c"))// filter = having.filter(column("c").gt(count))// 按照统计出来的数量,降序排序.orderBy(column("c").desc());saveToMySQL(tempTableName, sqlData);return sqlData.count();}/* 加载 hdfs 中 csv 文件内容* @param hdfsPath* @return*/private Dataset<UserDTO> loadCsv(String hdfsPath) {// 自定义数据类型,也可以使用数据类型自动推断StructField nameField = DataTypes.createStructField("name", DataTypes.StringType, true);StructField ageField = DataTypes.createStructField("age", DataTypes.IntegerType, true);StructField[] fields = new StructField[2];fields[0] = nameField;fields[1] = ageField;StructType schema = new StructType(fields);return sparkSession.read().schema(schema).csv(hdfsPath).map(new MapFunction<Row, UserDTO>() {@Overridepublic UserDTO call(Row row) throws Exception { UserDTO dto = new UserDTO();// 防止 npe if (!row.isNullAt(0)){dto.setName(row.getString(0));}// 防止 npe if (!row.isNullAt(1)) {dto.setAge(row.getInt(1));}return dto;}}, Encoders.bean(UserDTO.class));}/* 数据存储到 mysql* @param tableName 表名字* @param dataset 数据*/private void saveToMySQL(String tableName,Dataset<Row> dataset){dataset.write()// 覆盖模式,原始数据会被覆盖掉,如果需要追加,换成 SaveMode.Append.mode(SaveMode.Overwrite).format("jdbc").option("url", "jdbc:mysql://10.8.0.4/test").option("driver", "com.mysql.jdbc.Driver").option("dbtable", tableName).option("user", "root").option("password", "q").save();}
}测试结果
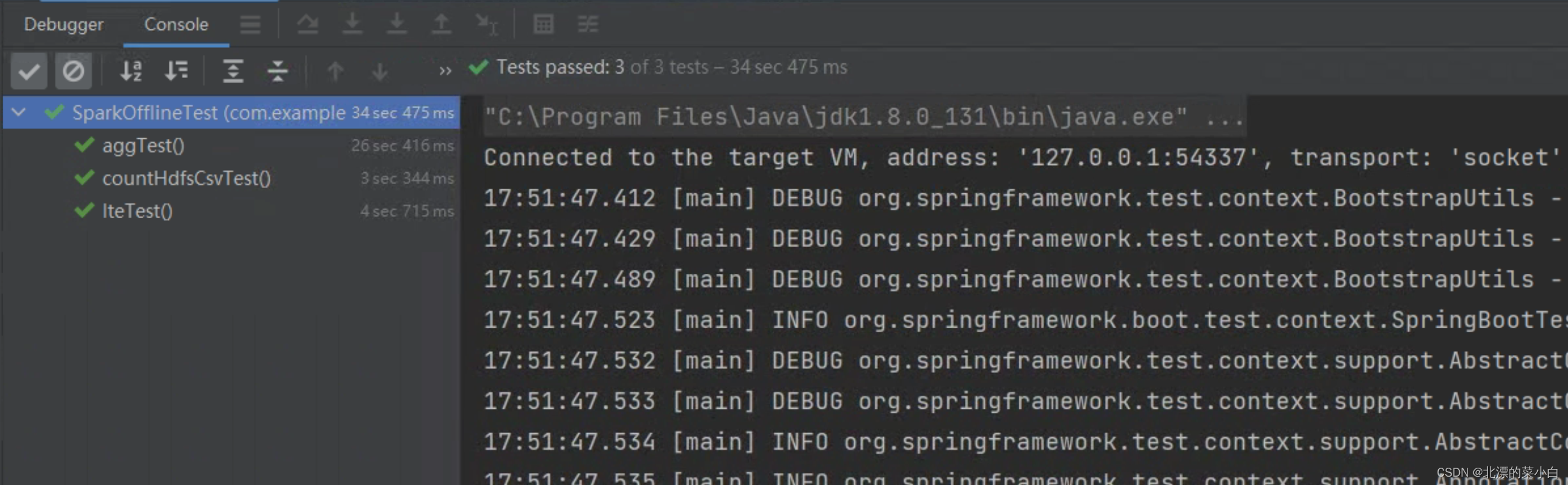
单元测试通过
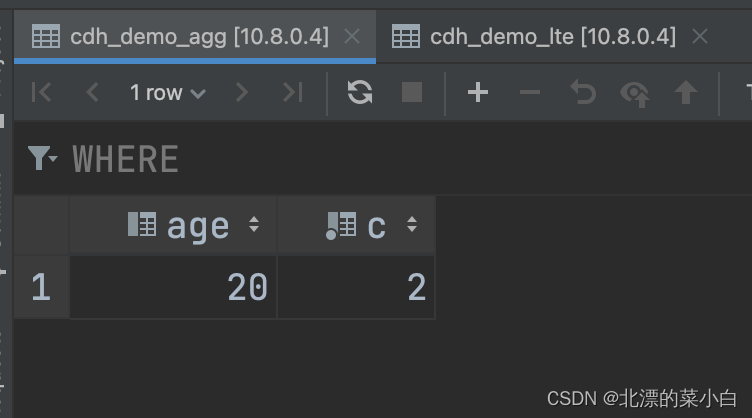
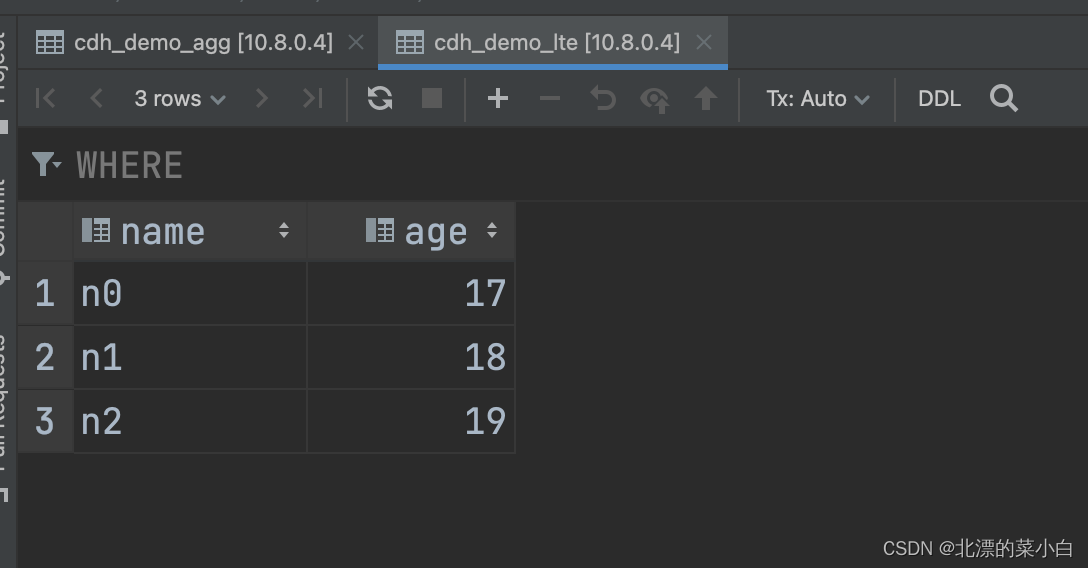
lte临时表数据验证通过
agg 临时表数据验证通过