缺省函数,函数重载,引用简单介绍的补充说明

TIPS
- 命名空间域的作用实际上相当于把部分变量的名称给他隔离起来,这样的话就可以减少变量名的冲突。
- 命名空间是对全局域当中的这些变量啊,函数啊,类型啊进行一个封装与隔离,可以防止你和我之间的冲突,也可以防止与库之间的冲突。命名空间域他封装的是全局域当中的一些东西,而不是局部域当中,在局部当中也不存在命名冲突的问题。这个局部域实际上说白了也就是函数的作用域。命名空间域解决的是全局当中的冲突问题
- cin,cout在一般场景下会更为快捷,因为它是自动识别类型的。由于c++兼容c,所以在有些时候可以与printf与scanf结合起来混着用。
缺省参数补充
- 缺省参数也叫做默认参数
- 当在函数调用的时候没有给缺省参数传入具体的实参的时候,这个参数在函数里面就会用默认指定的缺省值。对于全缺省参数来说,这时候函数调用传参的方式可以有很多种,这个参数可以写全,也可以不写全,如果不写全的话就默认是从左往右依次给过去。
- 你提供的实参是从左到右提供到函数形参里面的,因此缺省参数要缺也必须是从右往左缺省(全缺省咱也就不说了)
- 当在函数调用的时候没有给缺省参数传入具体的实参的时候,这个参数在函数里面就会用默认指定的缺省值。对于全缺省参数来说,这时候函数调用传参的方式可以有很多种,这个参数可以写全,也可以不写全,如果不写全的话就默认是从左往右依次给过去。
- 对于半缺省参数来说,必须得从右往左去缺。对于半缺省来说,必须得至少穿一个实参。传入实参的时候实参是从左往右去给形参的
- 缺省参数的实际应用:比方说我现在已经定义了一个栈,然后当我假设需要去使用这个栈数据结构的时候,可能会面临两种场景。第一种场景就是说:我已经提前知道需要往栈当中插入100个数据;我也不知道到底需要插入多少个数据,基于此,因此在栈的初始化过程当中,对于malloc开辟的空间个数,就可以通过缺省参数来设置。
#include <iostream>
using namespace std;
typedef struct Stack
{int* p;int top;int capacity;
}Stack;
void StackInit(Stack* pst, int defaultcapacity = 4)
{pst->p = (int*)malloc(sizeof(int) * defaultcapacity);if (pst->p == NULL){perror("malloc failed");return;}pst->top = 0;pst->capacity = defaultcapacity;
}
int main()
{Stack st;StackInit(&st);StackInit(&st, 100);return 0;
}
- 在一般大型项目当中,函数的声明与定义都是分开的,函数的声明是放在头文件当中,函数的定义是放在一个单独的.c文件当中。如果说这个函数有缺省参数的话,应该把这个缺省参数的缺省值给他写在函数的声明当中。如果说缺省参数的缺省值设定不写在声明当中的话就会报错。因为在预处理阶段就会把头文件打开,也就意味着函数的声明就会在main函数的上方,如果说在函数的声明当中没有去设定缺省值,那么在main函数里面如果说你函数传参的时候没有对缺省参数传参(按道理来说是完全合法的),但是在编译的时候编译器就会认为你这个函数传参没有传完整,因为你没有去给缺省值的话,他不知道这个参数是缺省参数,以为是必须得传参的(直接编译阶段语法报错),所以说在函数的声明当中必须得去给缺省值。对于函数的定义来说的话,就没必要去给缺省值了。
同作用域内函数重载的补充
- 重载:在自然语言当中,一个词可以有多重含义,人们可以通过上下文来判断该词真实的含义,也就是说该词被重载了。比如:以前有一个笑话,国有两个体育项目大家根本不用看,也不用担心。一个是乒乓球,一个是男足。前者是“谁也赢不了!”,后者是“谁也赢不了!”
- 在c++当中允许同名函数的存在,但你只需要保证要么是参数的类型不同,要么是参数的个数不同,要么是参数类型的顺序不同。但是对返回值的话没有要求,比方说两个函数,它们的参数部分与函数名称全部都是一模一样的,但就是返回类型不一样。那这样这两个函数是不构成重载的。
- 因此对于出现多个函数名称相同的函数,你就根据函数名修饰的规则去判断一下这些函数到底构不构成函数重载。如果说这些函数构成函数重载,那肯定就是可以编译通过;如果说这些函数不能够构成函数重载,那么肯定是不能够编译通过的,会报错的,重定义
- 但有时候有更为特殊的情况,就是说当缺省参数参与进来的时候,有时候两个函数可以构成重载,但是调用的时候会存在歧义,调用不明确。

- 所有的那些自动识别类型其实都跟函数重载有关,包括cin,cout等那些自动识别类型的玩意儿,还跟类和对象有关,以后再讲。
关于编译链接过程,函数重载底层原理的一些回顾与新补充
- 编译器在编译的时候早就没有.h了,因为头文件早在预处理的时候就已经全部被展开了,相当于就是一个拷贝与替换的过程。
- 但是预处理这个过程并不是在原先的.c文件上进行。因为如果那样去搞的话,相当于就把原先的给破坏掉了,可以理解成相当于新去创建了一个xxx.i文件,然后先把.c文件里面的代码全部拷贝到这个.i文件。然后再把头文件在.i里面给他全部展开。
- 然后预处理阶段完了之后就是编译阶段,编译阶段实际上有个非常非常重要的作用,就是检查语法,因为我现在需要把已经预处理好的代码给他转化成汇编代码。有语法问题的话我转化为汇编语言的时候就受阻了。这个过程非常非常的复杂,编译器工作当中最为核心的部分
- 汇编代码实际上就是指令级的代码,它的代码都是一个一个指令。
- 汇编阶段,由于这些汇编指令CPU是看不懂的,计算机只能看懂二进制指令,机器只识别二进制。汇编就是把汇编代码转化为机器码。
- 上面的这些过程,各个源文件都是不会发生交互,都是单独进行,最后生成一个又一个目标文件,然后进入链接阶段的时候,这些目标文件会全部合整起来,形成一个可执行程序。
- 然后先从预处理开始,现在进入到编译阶段,这时候进行语法检查,并把源代码给他转化成汇编指令,然后源代码当中的调用函数在汇编指令当中就是用call再加一个函数地址(因为函数本质上也就是一条又一条的汇编指令,函数中第一条汇编指令的地址=所谓的函数地址=第一条汇编指令其实就是压栈push ebp,因为需要去建立函数栈帧),这个call本质上就是一种跳转,也就是说跳转到后面跟着的那个地址所对应的汇编指令那边去。

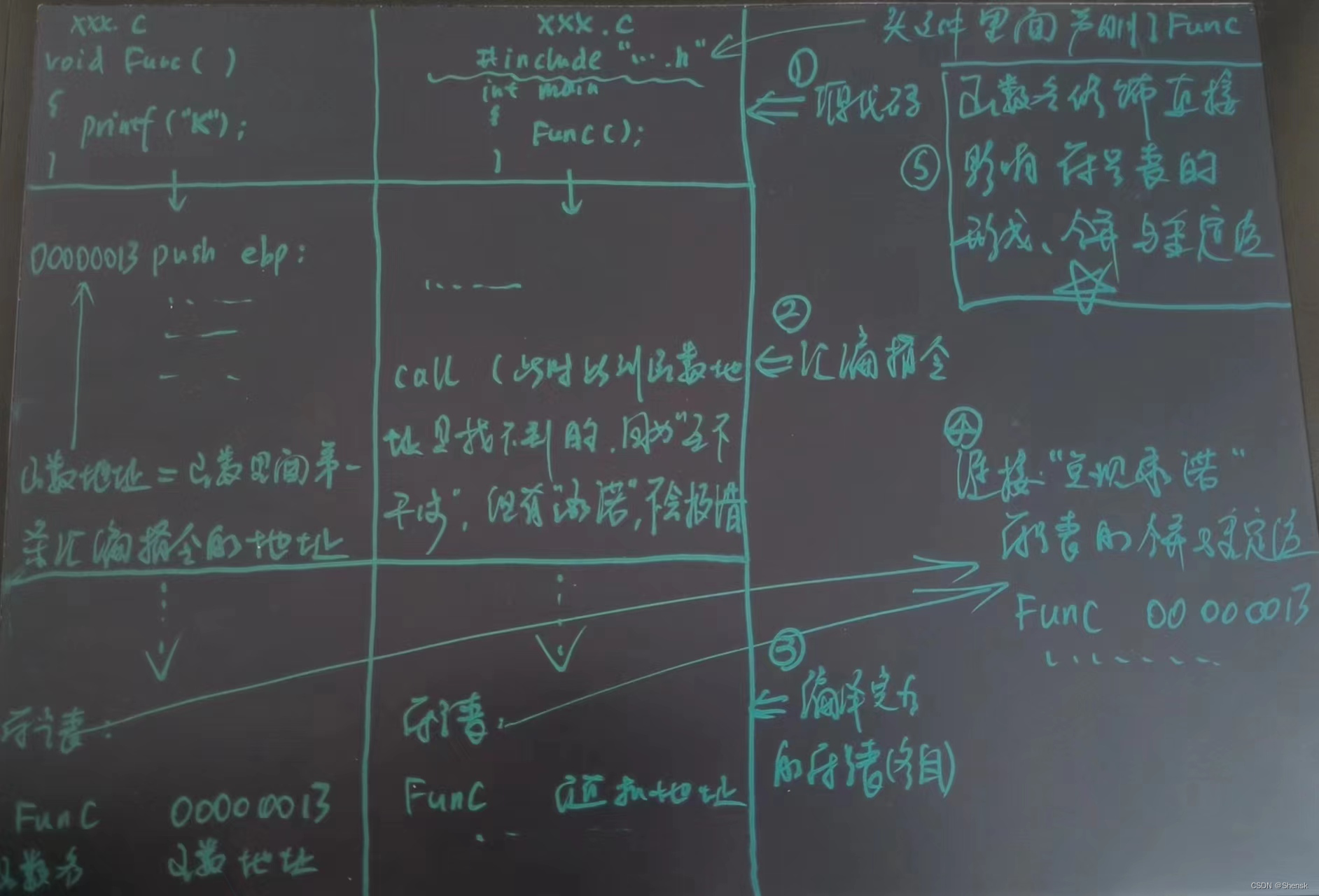
去找函数的地址就是去通过符号表,然后对照着名字去找到地址的,所以说c++当中的函数名修饰的话,它会直接影响到符号表的形成,合并与重定位
- 其他具体内容细节看我C++博客前一节,这边只是新的认知与补充。
引用简单介绍的补充
- 引用主要是针对函数传参的时候的传址调用,就是不用再去通过传地址到参数里面,而是直接通过引用的方式直接空降到函数里面,达到相同的效果。
- 引用相当于就是说对同一块内存空间的一个变量名字,进行了多种取别名。它主要的优势在于有时候可以比指针的那些写法可读性更高,也更容易操作一些。尤其是在函数传参过程当中,通过引用可以将需要通过函数改动的东西不是通过传地址的方式而是引用的方式直接空降进来
- (内存里面的数据类型)& (外号别名) = 原先的名字or别名 注意:函数在传参的过程当中,定义形式形参与实参之间可以想象成划等号
- 对于指针的话,创建的时候可以不用明确的说指向谁,但是在引用的时候必须明确指出引用的实体
- (终身制)引用的话是不能够去改变指向的,比方说现在假设有一个变量是a,然后引用了一下,就是说把这个变量a取一个别名称为b,但是两者实际上都是同一个变量,都是同一个内存空间,然后现在比如说b等于是c,c为3,这时候不是说b已经改变了他引用的实体,引用是不能够去改变实体的,这边相当于就是说把变量a或者说b的值变成了3。a就是b,b就是a。
