目标检测框架yolov5环境搭建

目前,目标检测框架中,yolov5 是很火的,它基于pytorch框架,集成opencv等框架,项目地址:https://github.com/ultralytics/yolov5,对我来说,机器学习、深度学习才开始接触,本篇只能是按照项目说明来进行一个简单的测试和验证。
这里目标检测,其实就是给定一些图片后者视频,结合现有的模型训练,然后生成识别的结果。
项目介绍给出的两个示例图片如下:
第一张像是西班牙足球运动员皮克,夏奇拉的前夫弟弟:

还有一个是齐祖打领带咆哮的照片:

这里目标检测,需要识别图片中的人和车,还有领带。
环境要求:python3.9及以上版本。
我这里是在linux下,python版本是3.10 。
1 、克隆github上的项目到本地:https://github.com/ultralytics/yolov5,如果这个地址比较慢,可以考虑国内的码云地址:https://gitee.com/monkeycc/yolov5,这个地址就是同步的github仓库的项目,但是下载速度很快:
git clone https://github.com/ultralytics/yolov52、安装依赖
cd yolov5
pip install -r requirements.txt3、下载模型文件:https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5s.pt
如果这个地址太慢,可以到这个百度网盘的地址上下载:https://pan.baidu.com/s/1vSqeX7WDyo23FCLOwiTBjA?pwd=yolo
下载之后,放到项目根路径下,我们暂时只下载一个模型文件yolov5s.pt。
4、运行测试demo。
buejee@SKY-20230223WWS:~/yolov5$ python3 detect.py
detect: weights=yolov5s.pt, source=data/images, data=data/coco128.yaml, imgsz=[6 40, 640], conf_thres=0.25, iou_thres=0.45, max_det=1000, device=, view_img=False , save_txt=False, save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=False, augment=False, visualize=False, update=False, project=runs/d etect, name=exp, exist_ok=False, line_thickness=3, hide_labels=False, hide_conf= False, half=False, dnn=False, vid_stride=1
YOLOv5 🚀 2023-4-10 Python-3.10.6 torch-2.0.0+cu117 CPUFusing layers...
YOLOv5s summary: 213 layers, 7225885 parameters, 0 gradients
image 1/2 /home/buejee/yolov5/data/images/bus.jpg: 640x480 4 persons, 1 bus, 197 .4ms
image 2/2 /home/buejee/yolov5/data/images/zidane.jpg: 384x640 2 persons, 2 ties, 139.0ms
Speed: 4.6ms pre-process, 168.2ms inference, 9.4ms NMS per image at shape (1, 3, 640, 640)
Results saved to runs/detect/exp2
buejee@SKY-20230223WWS:~/yolov5$
根据提示,结果放到了runs/detect/exp2目录下。
先看看大致的结果:
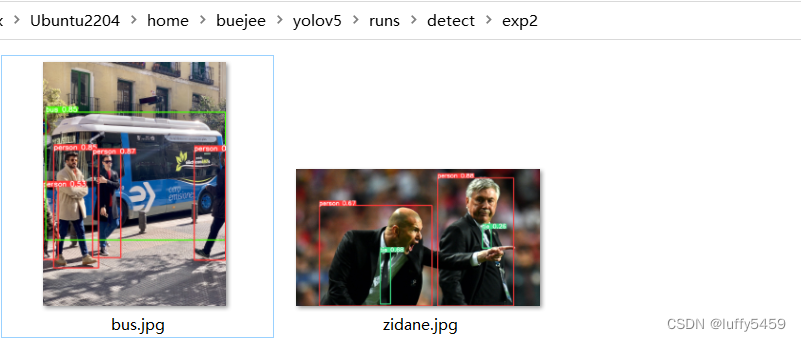
图片中的人都识别出来了,并且用红框画出来了。
具体的图片:
第一张,公交车与旁边的人:
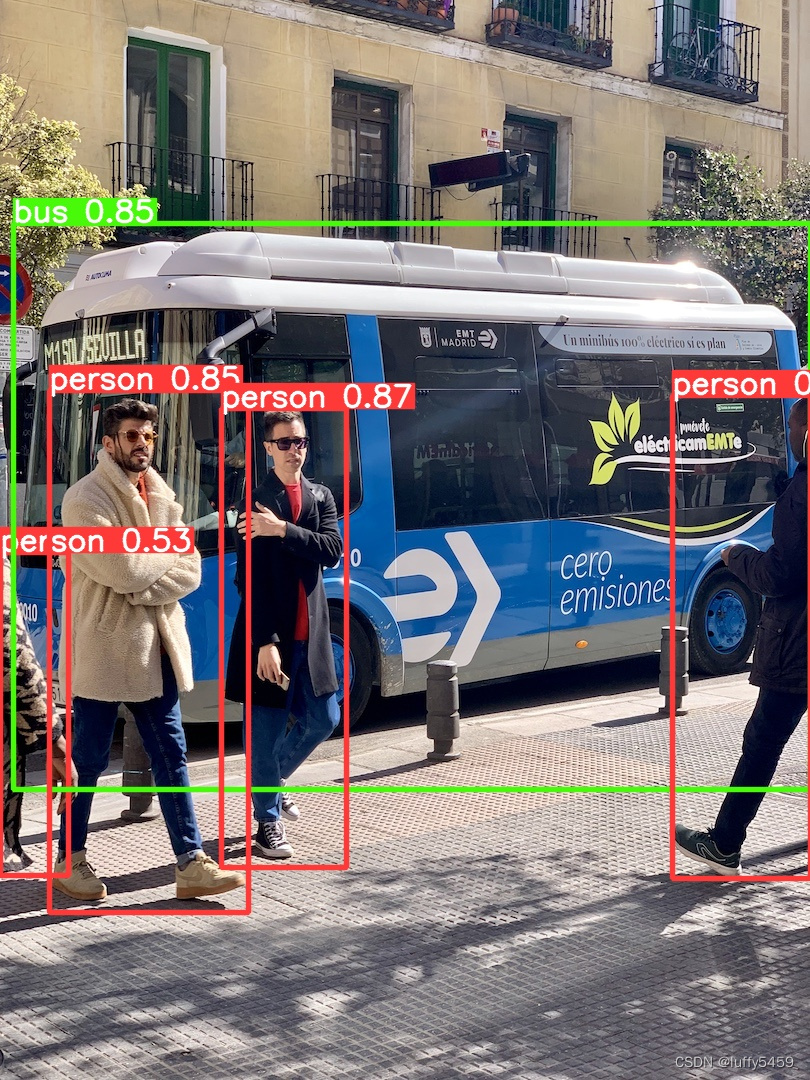
第二张,人和领带都识别了:

感觉很强大,很厉害,环境部署也不是很复杂,基本就是傻瓜式的执行几个命令。