【Diffusion Model】Learning notes
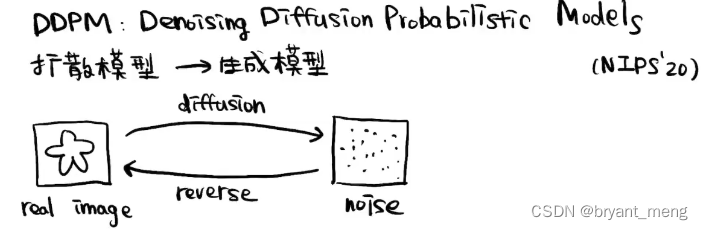
扩散模型(Diffusion Model)是个啥?说白了,它就是个高级“画图”工具,能把一堆无序的噪点逐渐变成一张有意义的图。听起来有点玄乎?其实可以类比咱们修图的“磨皮”过程,只不过它是从噪点“磨”出图来,而不是从图磨出平滑皮肤。扩散模型的核心思想是通过“加噪”和“去噪”两个步骤,模拟数据的生成过程,最终“磨”出一张符合特定分布的新图。
那么问题来了:这东西和GAN(生成对抗网络)比,哪个更牛?拿训练难度来说,GAN就像两个小孩打架,生成器和判别器得打得势均力敌,不然就容易“崩盘”。扩散模型就不一样了,它的目标明确,就是一步步去噪,训练起来更稳当,不容易“翻车”。而且,GAN的训练过程复杂得让人头疼,扩散模型则简单直白,损失函数一目了然。
但这并不意味着扩散模型就是完美的。比如,它的生成速度慢得像蜗牛,每张图得加噪N次才能搞定。能不能直接从原图一步到位生成最终效果?嗯,技术上确实可以,但效果可能就打了个折扣。所以,扩散模型更适合那些追求高质量生成结果的场景,比如艺术创作、医学影像处理等。
说到应用,扩散模型潜力巨大。AI绘画、虚拟现实、甚至科研领域,它都能插一脚。比如,AI绘画师用它生成超现实的画面,科研人员用它模拟复杂的分子结构。总之,扩散模型虽然有点“慢”,但它稳如老狗,前途无量。

来自 扩散模型 Diffusion Model 1-1 概述
扩散模型是什么?
本质是生成模型,拟合目标分布,然后生成很多数据符合这个分布
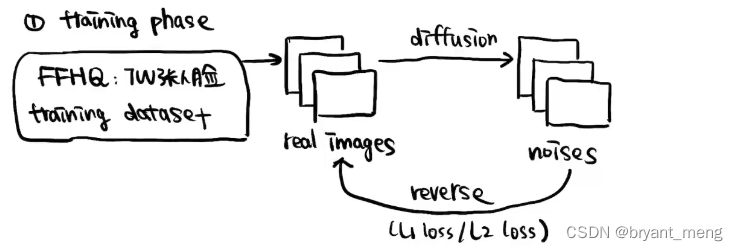
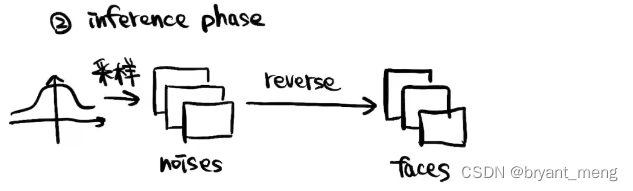
训练测试阶段?
和 GAN 相比优势是什么?
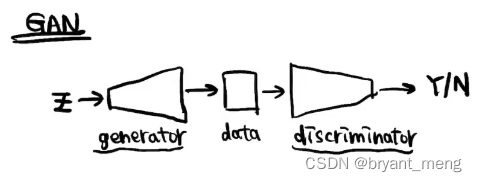
generator 和 discriminator 两者都得训练的比较均衡才能得到好的结果(稳定性),两者对抗,loss 并不能直观的反应训练过程
- 训练难度
- 训练稳定性
- loss 的复杂性
DDPM 的话,reverse 只是一个去噪模型,目标比较明确,易于训练
扩散阶段
ZtZ_tZt 服从标准正态分布
βt\\beta_tβt 加权系数,越来越大

上图是从 XtX_tXt 到 Xt−1X_{t-1}Xt−1 的公式
每张图加噪 T 次太慢了
我们能否直接从 X0X_0X0 直接推导到 XtX_tXt 呢?

αt\\alpha_tαt
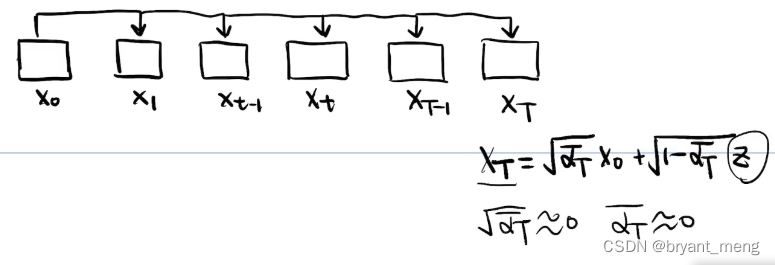
XT≈ZX_T \\approx ZXT≈Z 近似高斯噪声
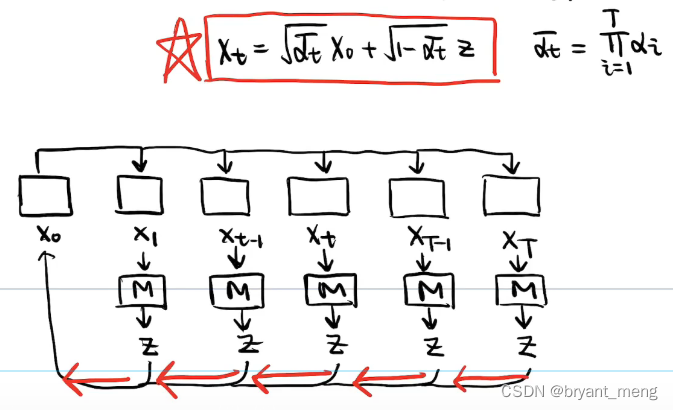
reverse 的过程这里简单的进行了表示
看看多 batch 的时候是怎么训练的
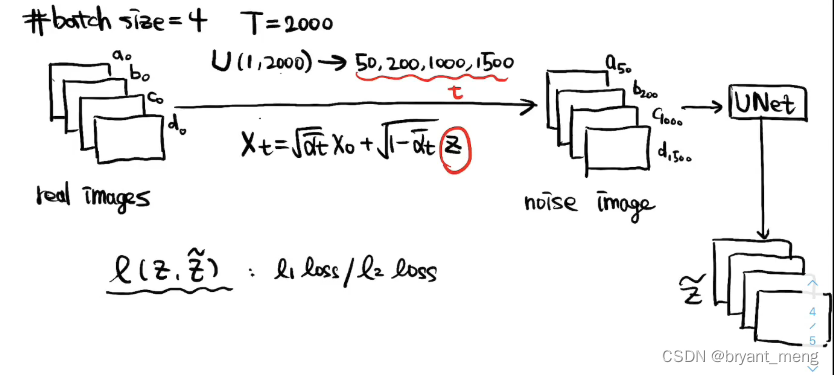
扩散过程
Z~=UNet(Xt,t)\\widetilde{Z} = UNet(X_t, t)Z