机器学习——L1范数充当正则项,让模型获得稀疏解,解决过拟合问题

问:使用L2范数正则项比L1范数正则项得到的是更为稀疏的解。
答:错误,L1范数正则项得到的是更稀疏的解。因为在L1正则项中,惩罚项是每个参数绝对值之和;而在L2正则项中,惩罚项是每个参数平方的和。L1正则项可以压缩参数中的小值,更容易导致一些参数被压缩到零。采用L1正则化,最优解为0的概率极大增加,这使得得到的解更可能是稀疏的。
为了理解l1范数的正则项和稀疏性之间的关系,我们可以想想下面三个问题:
- ·为什么l范数就能使得我们得到一个稀疏解呢?
- 为什么稀疏解能够避免过拟合?
- 正则项在模型中扮演者何种角色?
什么是过拟合问题?
在讨论上面三个问题之前,我们先来看看什么是过拟合问题:假设我们现在买了一个机器人,想让它学会区分汉字,例如
认定前5个字属于第一类,后5个字属于第二类。在这里,10个字是所有的训练的“数据”
不幸的是,机器人其实很聪明,它能够把所有的字都“记住”,看过这10个字以后,机器人学会了一种分类的方式:它把前5个字的一笔一划都准确地记在心里。只要我们给任何一个字,如“揪”(不在10个字里面),它就会很自信地告诉你,非此即彼,这个字属于第二类。当然,对于这10个字,机器人可以区分地非常好,准确率100%.但是,对于
机器人没见过这个字(不在10个字里面),它将这个字归为第二类,这可能就错了。
因为我们可以明显看到,前5个字都带提手旁:
所以,“揪”属于第一类。
机器人的失败在于它太聪明,而训练数据又太少,不允许它那么聪明,这就是过拟合问题。
正则项是什么?为什么稀疏可以避免过拟合?
还是给它前面测试过的那10个字,但现在机器人已经没办法记住前5个字的一笔一划了(存储有限),它此时只能记住一些简单的模式,于是,第一类字都带有提手旁就被它成功地发现了。
实际上,这就是L1范数正则项的作用。
L1范数会让你的模型变傻一点,相比于记住事物本身,此时机器人更倾向于从数据中找到一些简单的模式。

假设我们有一个待训练的机器学习模型,如下: 假设我们有一个待训练的机器学习模型,如下:
Ax=b
其中,A是一个训练数据构成的矩阵,b是一个带有标签的向量,这里的是我们希望求解出来的解。
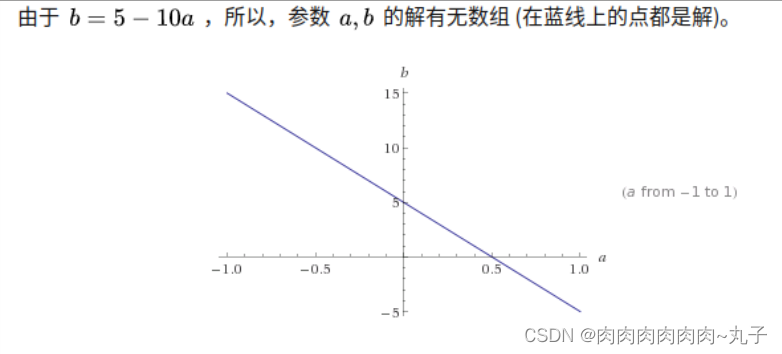
当训练样本很少(training data is not enough)向量 a长度很长时,这个模型的解就很多了。
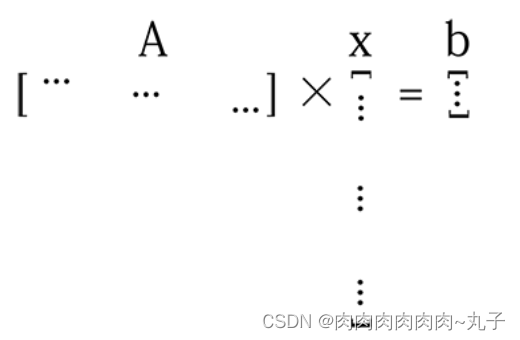
如图,矩阵A 的行数远少于向量 的长度。
我们希望的是找到一个比较合理的解,即向量能够发现有用的特征(useful features)。使用L1范数作为正则项,向量会变得稀疏,非零元素就是有用的特征了。
为什么增加L1范数能够保证稀疏?

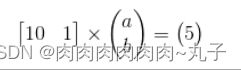
怎样通过L1范数找到一个稀疏解呢?
我们不妨先假设向量的L1范数是一个常数c,如下图: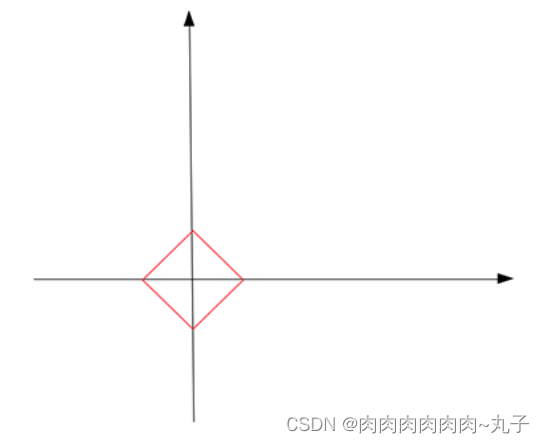
它的形状是一个正方形(红色线),不过在这些边上只有很少的点是稀疏的,即与坐标轴相交的4个顶点。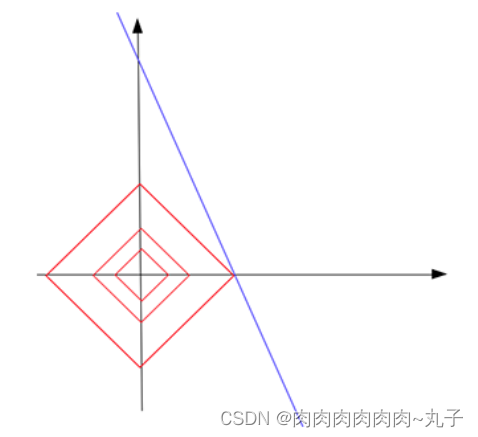
把红色的正方形(L范数为常数))与蓝色的线(解)放在同一个坐标系,于是,我们发现蓝线与横轴的交点恰好是满足稀疏性要求的解。同时,这个交点使得L范数取得最小值。