【大数据之Hadoop】十四、MapReduce之Combiner合并

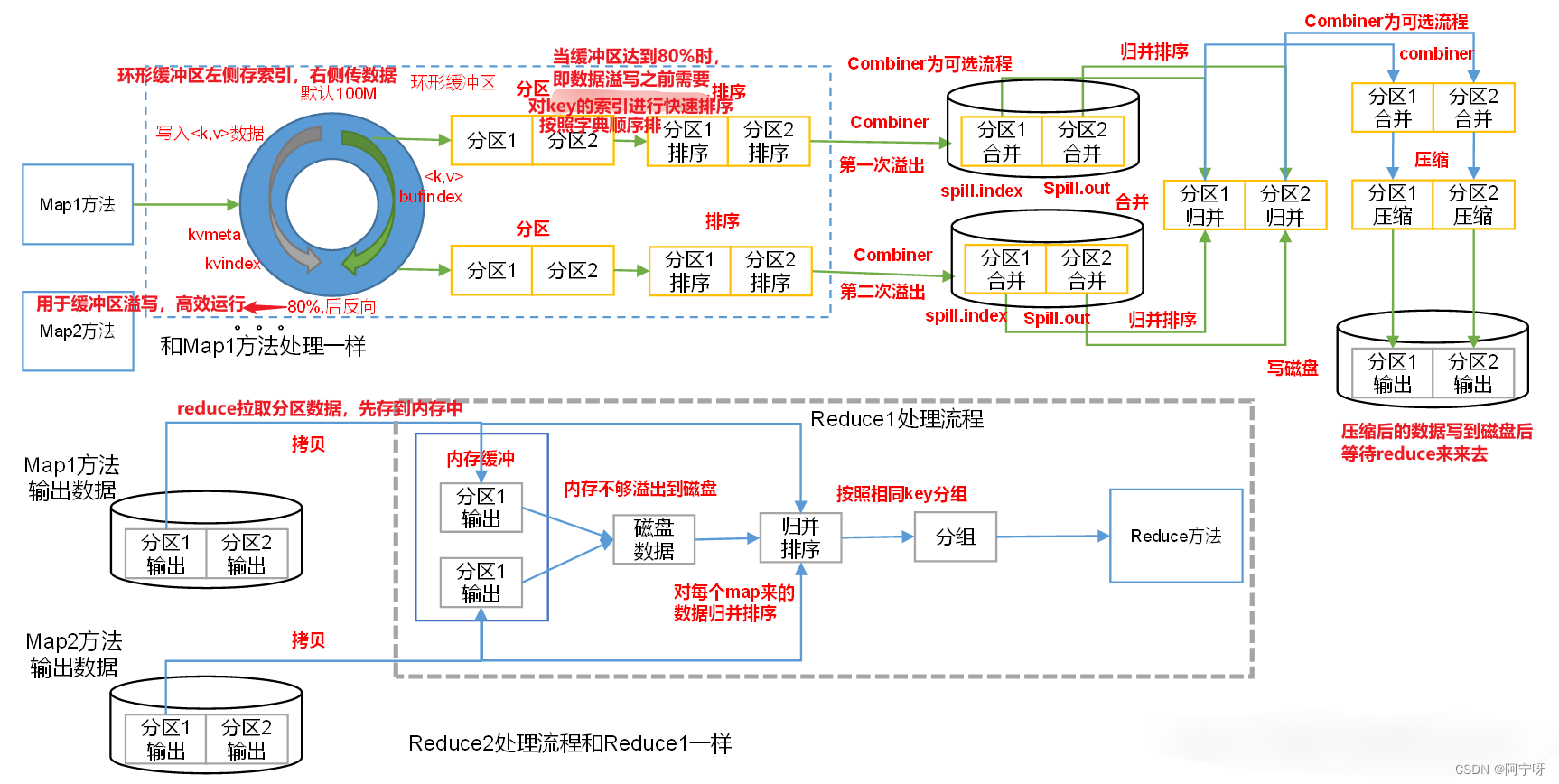
Combiner是Mapper和Reducer之间的组件,其组件的父类是Reducer。
Combiner和Reducer的区别:
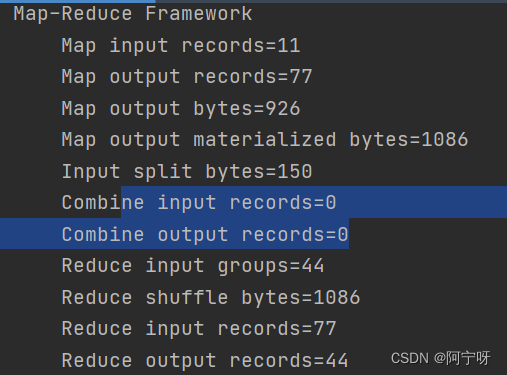
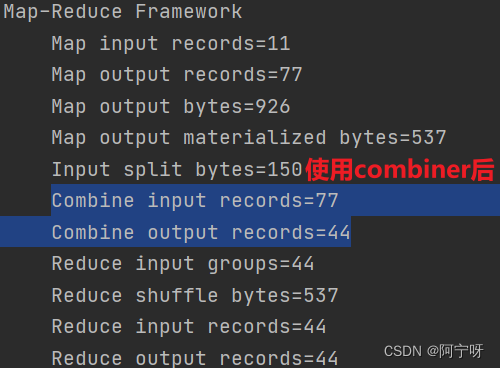
Combiner是运行在每一个MapTask所在的节点,即对每一个MapTask的输出进行局部汇总,减少网络传输量。
Reducer则是接收全局是Mapper的输出结果。
Combiner应用前提是不能影响最终的业务逻辑,且Combiner的输出kv对应Reducer输入kv。
方法一、自定义Combiner
- 创建一个新Combiner类继承Reducer类,重写reduce()方法,与Reducer类中的写法相同。
- 在驱动类Driver中指定combiner
// 指定需要使用combiner,以及用哪个类作为combiner的逻辑
job.setCombinerClass(WordCountCombiner.class);
方法二、把WordcountReducer作为Combiner在WordcountDriver驱动类中指定
// 指定需要使用Combiner,以及用哪个类作为Combiner的逻辑
job.setCombinerClass(WordCountReducer.class);