【图像分类】【深度学习】ViT算法Pytorch代码讲解

【图像分类】【深度学习】ViT算法Pytorch代码讲解
文章目录
- 【图像分类】【深度学习】ViT算法Pytorch代码讲解
- 前言
- ViT(Vision Transformer)讲解
-
- patch embedding
- positional embedding
- Transformer Encoder
- Encoder Block
- Multi-head attention
- MLP Head
- 完整代码
- 总结
前言
ViT是由谷歌公司的Dosovitskiy, Alexey等人在《 An Image Is Worth 16x16 Words: Transformers For Image Recognition At Scale [ICLR2021]》【论文地址】一文中提出的模型,提出了一种基于transformer结构的模型,摒弃传统的CNN结构,直接将Transformer应用到图像块序列上一样可以达到非常好的性能。
ViT(Vision Transformer)讲解
论文在模型设计方面尽可能和原始Transformer保持一致。这种有意设计简单化的优点在于对NLP的Transformer有良好的扩展性,几乎可以实现“开箱即用”。

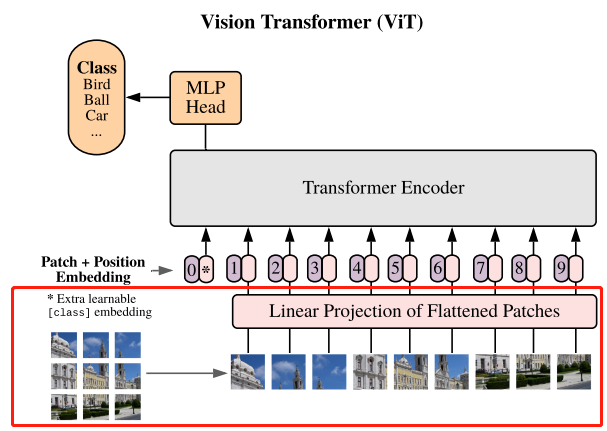
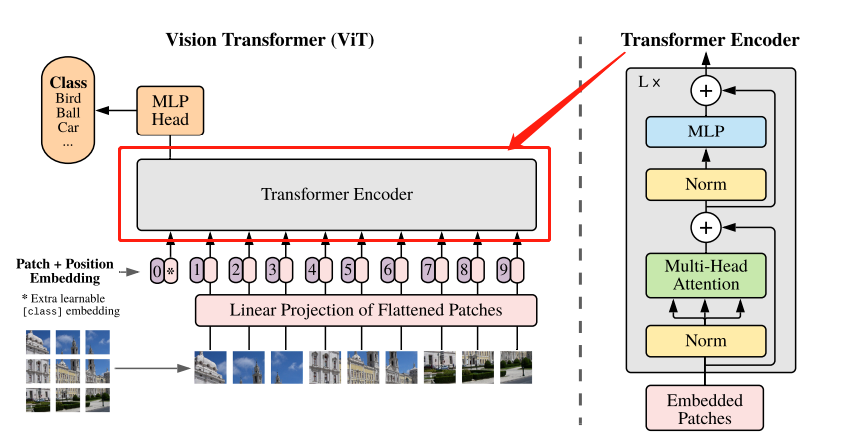
如上面的动态图所示,ViT在分类任务中的分为以下几个基本步骤:
- 图片切分为若干图片序列块
- 所有序列块经过线性映射后展平为一维向量
以上俩步是 patch embedding过程,成功将一个视觉问题转化为了一个seq2seq问题。
- positional embedding:嵌入类别编码和位置编码(用于保留位置信息)
- Transformer Encoder:主体编码器部分
- MLP Head
【代码部分参考1】
【代码部分参考2】
patch embedding
输入图片大小为224x224,巧妙使用步长为16的卷积核将图片分为固定大小16x16的patch,则每张图像会生成224x224/16x16=196个patch,输出序列为196。每个patch维度16x16x3=768,线性投射层(其实就是卷积操作)的维度为MxN(M=16x16x3,N=3x768x16x16),因此输入通过线性投射层之后的维度依然为196x768,即一共有196个token,每个token的维度是768。
通过patch embedding将一个视觉问题转化为了一个seq2seq问题,patch embedding流程如下图所示:
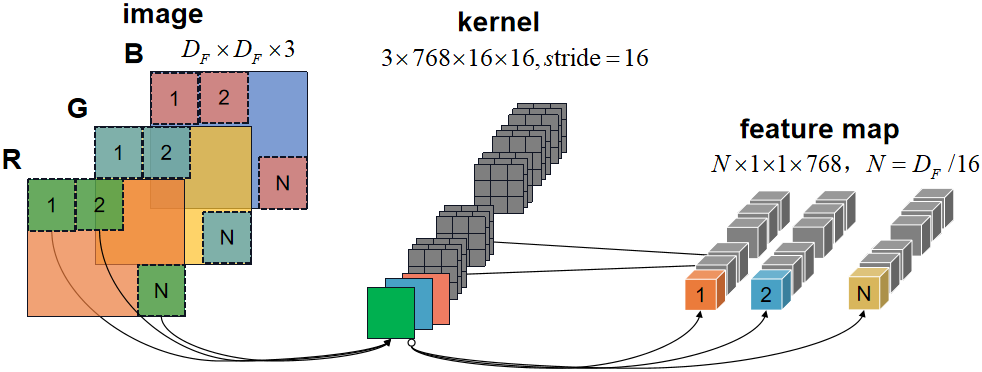
class PatchEmbed(nn.Module):"""2D Image to Patch Embedding"""def __init__(self, img_size=224, patch_size=16, in_c=3, embed_dim=768, norm_layer=None):super().__init__()# 图片分辨率 h wimg_size = (img_size, img_size)# 卷积核大小patch_size = (patch_size, patch_size)self.img_size = img_sizeself.patch_size = patch_size# 分别计算w、h方向上的patch的个数self.grid_size = (img_size[0] // patch_size[0], img_size[1] // patch_size[1])# 一张图片的pacth个数self.num_patches = self.grid_size[0] * self.grid_size[1]# 卷积的步长巧妙地实现图片切分操作,而后与patch大小一致的卷积核完成线性映射self.proj = nn.Conv2d(in_c, embed_dim, kernel_size=patch_size, stride=patch_size)self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity() # nn.Identity()恒等函数 f(x)=xdef forward(self, x):B, C, H, W = x.shapeassert H == self.img_size[0] and W == self.img_size[1], \\f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."# flatten: [B, C, H, W] -> [B, C, HW]# transpose: [B, C, HW] -> [B, HW, C]# 一维展平x = self.proj(x).flatten(2).transpose(1, 2)x = self.norm(x)return x
demo在动态流程图中的对应部分:
positional embedding
经过patch embedding后输出维度是196x768,concat一个特殊字符cls(1x768),维度变为197x768。ViT同样需要加入位置编码,位置编码可以理解为一张map,map的行数与输入序列个数相同(197),每一行代表一个向量,向量的维度和输入序列embedding的维度相同(768)。位置编码的操作是sum,所以维度依旧保持197x768。
个人理解cls和pos的作用就是ax+b中的b,是可训练的归纳偏置,因为Vision Transformer相比CNN具有更少的针对图像的归纳偏置。position embeddings在初始化时不携带任何2维位置信息,图像块之间的所有空间关系都是从头学习得到的。
positional embedding流程如下图所示:
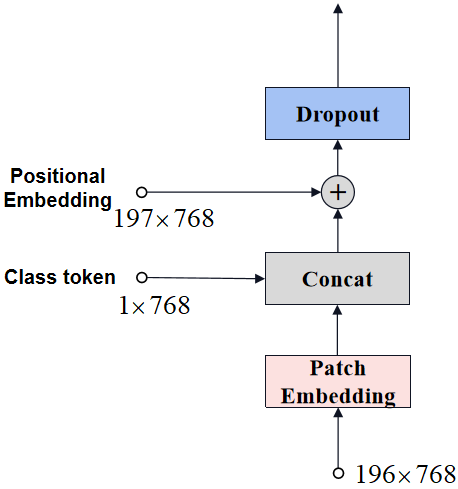
class PositionEmbs(nn.Module):def __init__(self, num_patches, emb_dim, dropout_rate=0.1):super(PositionEmbs, self).__init__()self.pos_embedding = nn.Parameter(torch.zeros(1, num_patches + 1, emb_dim))if dropout_rate > 0:self.dropout = nn.Dropout(dropout_rate)else:self.dropout = Nonedef forward(self, x):out = x + self.pos_embeddingif self.dropout:out = self.dropout(out)return out
在class VisionTransformer的__init__函数中
# class token
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
self.dist_token = nn.Parameter(torch.zeros(1, 1, embed_dim)) if distilled else None
# positional embedding
self.pos_embedding = PositionEmbs(num_patches, embed_dim, drop_ratio)
在class VisionTransformer的forward_features函数中
cls_token = self.cls_token.expand(x.shape[0], -1, -1)
# self.dist_token暂时可以忽略
if self.dist_token is None:x = torch.cat((cls_token, x), dim=1) # [B, 197, 768]
else:x = torch.cat((cls_token, self.dist_token.expand(x.shape[0], -1, -1), x), dim=1)
x = self.pos_embedding(x)
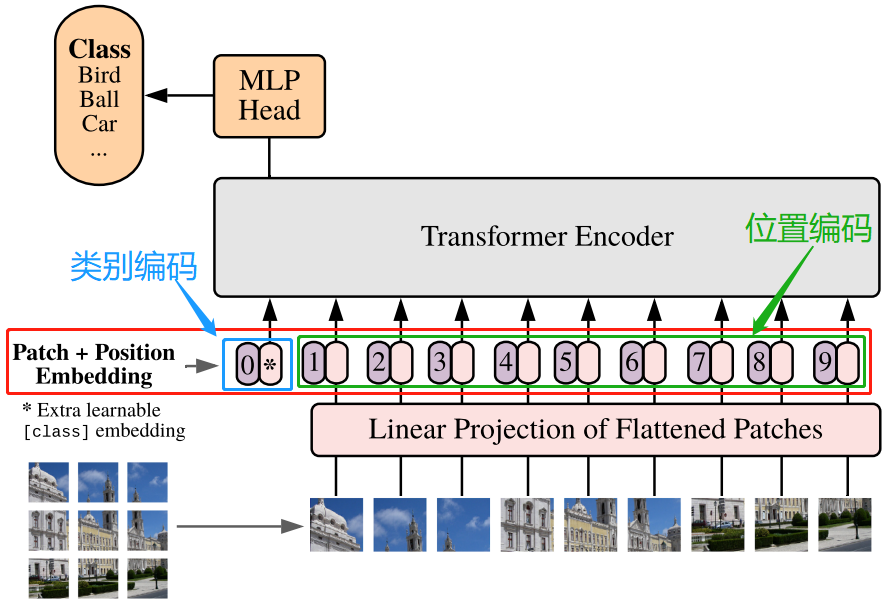
demo在动态流程图中的对应部分:
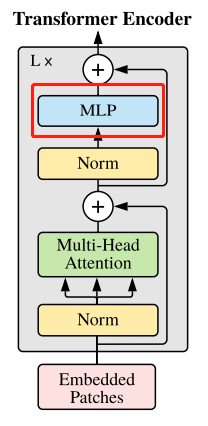
Transformer Encoder
Transformer EncoderL个重复堆叠 Encoder Block组成。
class VisionTransformer(nn.Module):def __init__(self, img_size=224, patch_size=16, in_c=3, num_classes=1000,embed_dim=768, depth=12, num_heads=12, mlp_ratio=4.0, qkv_bias=True,qk_scale=None, representation_size=None, distilled=False, drop_ratio=0.,attn_drop_ratio=0., drop_path_ratio=0., embed_layer=PatchEmbed, norm_layer=None,act_layer=None):"""Args:img_size (int, tuple): input image sizepatch_size (int, tuple): patch sizein_c (int): number of input channelsnum_classes (int): number of classes for classification headembed_dim (int): embedding dimensiondepth (int): depth of transformernum_heads (int): number of attention headsmlp_ratio (int): ratio of mlp hidden dim to embedding dimqkv_bias (bool): enable bias for qkv if Trueqk_scale (float): override default qk scale of head_dim -0.5 if setrepresentation_size (Optional[int]): enable and set representation layer (pre-logits) to this value if setdistilled (bool): model includes a distillation token and head as in DeiT modelsdrop_ratio (float): dropout rateattn_drop_ratio (float): attention dropout ratedrop_path_ratio (float): stochastic depth rateembed_layer (nn.Module): patch embedding layernorm_layer: (nn.Module): normalization layer"""super(VisionTransformer, self).__init__()# 类别个数self.num_classes = num_classes# embed_dim默认tansformer的base 768self.num_features = self.embed_dim = embed_dim # num_features for consistency with other models# 源码distilled是为了其他任务,分类暂时不考虑self.num_tokens = 2 if distilled else 1# LayerNorm:对每单个batch进行的归一化norm_layer = norm_layer or partial(nn.LayerNorm, eps=1e-6)# act_layer默认tansformer的GELUact_layer = act_layer or nn.GELU# embed_layer默认是patch embedding,在其他应用中应该会有其他选择# patch embedding过程self.patch_embed = embed_layer(img_size=img_size, patch_size=patch_size, in_c=in_c, embed_dim=embed_dim)# patche个数num_patches = self.patch_embed.num_patches# class tokenself.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))self.dist_token = nn.Parameter(torch.zeros(1, 1, embed_dim)) if distilled else None# positional embedding过程self.pos_embedding = PositionEmbs(num_patches, embed_dim, drop_ratio)# self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + self.num_tokens, embed_dim))# self.pos_drop = nn.Dropout(p=drop_ratio)# depth是Block的个数# 不同block层数 drop_ratio的概率不同,越深度越高dpr = [x.item() for x in torch.linspace(0, drop_path_ratio, depth)] # stochastic depth decay rule# blocks搭建self.blocks = nn.Sequential(*[Block(dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,drop_ratio=drop_ratio, attn_drop_ratio=attn_drop_ratio, drop_path_ratio=dpr[i],norm_layer=norm_layer, act_layer=act_layer)for i in range(depth)])self.norm = norm_layer(embed_dim)# Representation layerif representation_size and not distilled:self.has_logits = Trueself.num_features = representation_sizeself.pre_logits = nn.Sequential(OrderedDict([("fc", nn.Linear(embed_dim, representation_size)),("act", nn.Tanh())]))else:self.has_logits = Falseself.pre_logits = nn.Identity()# Classifier head(s)self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()self.head_dist = Noneif distilled:self.head_dist = nn.Linear(self.embed_dim, self.num_classes) if num_classes > 0 else nn.Identity()# Weight initif self.dist_token is not None:nn.init.trunc_normal_(self.dist_token, std=0.02)nn.init.trunc_normal_(self.cls_token, std=0.02)self.apply(_init_vit_weights)def forward_features(self, x):# [B, C, H, W] -> [B, num_patches, embed_dim]x = self.patch_embed(x) # [B, 196, 768]# [1, 1, 768] -> [B, 1, 768]cls_token = self.cls_token.expand(x.shape[0], -1, -1)# self.dist_token暂时可以忽略if self.dist_token is None:x = torch.cat((cls_token, x), dim=1) # [B, 197, 768]else:x = torch.cat((cls_token, self.dist_token.expand(x.shape[0], -1, -1), x), dim=1)x = self.pos_embedding(x)# x = self.pos_drop(x + self.pos_embed)x = self.blocks(x)x = self.norm(x)if self.dist_token is None:return self.pre_logits(x[:, 0])else:return x[:, 0], x[:, 1]def forward(self, x):x = self.forward_features(x)if self.head_dist is not None:x, x_dist = self.head(x[0]), self.head_dist(x[1])if self.training and not torch.jit.is_scripting():# during inference, return the average of both classifier predictionsreturn x, x_distelse:return (x + x_dist) / 2else:x = self.head(x)return x
demo在动态流程图中的对应部分:
Encoder Block
组成 Transformer Encoder的单位,从低到高由LayerNorm (针对NLP领域提出的对每个token进行Norm处理)、Multi-Head Attention、DropPath(可直接换成Dropout)和 MLP Head等构成。
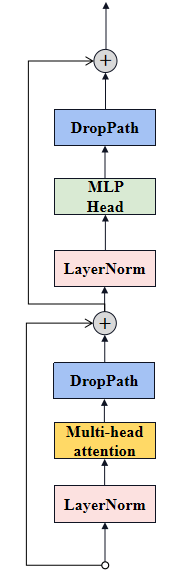
class Block(nn.Module):def __init__(self,dim,num_heads,mlp_ratio=4.,qkv_bias=False,qk_scale=None,drop_ratio=0.,attn_drop_ratio=0.,drop_path_ratio=0.,act_layer=nn.GELU,norm_layer=nn.LayerNorm):super(Block, self).__init__()self.norm1 = norm_layer(dim)# Multi-head attention模块self.attn = Attention(dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,attn_drop_ratio=attn_drop_ratio, proj_drop_ratio=drop_ratio)# NOTE: drop path for stochastic depth, we shall see if this is better than dropout hereself.drop_path = DropPath(drop_path_ratio) if drop_path_ratio > 0. else nn.Identity()self.norm2 = norm_layer(dim)mlp_hidden_dim = int(dim * mlp_ratio)# MLP Head模块self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop_ratio)def forward(self, x):x = x + self.drop_path(self.attn(self.norm1(x)))x = x + self.drop_path(self.mlp(self.norm2(x)))return x
Multi-head attention
读者先阅读大佬的博文【Multi-head attention流程与原理参考】。这里博主结合代码也做了自己的总结供大家参考。
N–>num_patches + 1 ;(197)
E:embed_dim;(768)
H–>num_heads;
Eq–>embed_dim_per_head(E/H)
对于输入到Multi-head attention模块的特征 F(N×E) ,通过attention模块的nn.Linear进一步提取特征获得输出特征 v(value) 。为了考虑 N 个特征之间存在的亲疏和位置关系对于 v 的影响,所以需要一个额外权重 w(weight) 对 v 进行加权操作,这引出了计算 w 所需的 q(query) 与 k(key) , q 与 k 同样是特征 F 通过nn.Linear获取。
下图简要展示了q、k和v的作用,便于理解原始特征v和原始特征v经过w加权计算后的特征V。
(qn{{\\rm{q}}_{\\rm{n}}}qn,kn{{\\rm{k}}_{\\rm{n}}}kn,vn{{\\rm{v}}_{\\rm{n}}}vn)是特征n的经过attention模块后输出的三个特征。q1{{\\rm{q}}_{\\rm{1}}}q1与k3{{\\rm{k}}_{\\rm{3}}}k3矩阵计算得到权重w13{{\\rm{w}}_{\\rm{13}}}w13,以此类推。以原始特征v1{{\\rm{v}}_{\\rm{1}}}v1计算得到加权特征V1{{\\rm{V}}_{\\rm{1}}}V1的过程为例,v1{{\\rm{v}}_{\\rm{1}}}v1分别于w1x{{\\rm{w}}_{\\rm{1x}}}w1x、w2x{{\\rm{w}}_{\\rm{2x}}}w2x和w3x{{\\rm{w}}_{\\rm{3x}}}w3x矩阵运算得到V11{{\\rm{V}}_{\\rm{11}}}V11、V12{{\\rm{V}}_{\\rm{12}}}V12和V13{{\\rm{V}}_{\\rm{13}}}V13,即最终的V1{{\\rm{V}}_{\\rm{1}}}V1。
因此可以看到任何Vi{{\\rm{V}}_{\\rm{i}}}Vi都考虑了特征 F 中 N 个特征之间存在的影响。

Multi-head self-attention流程如下图所示(不考虑batchsize):
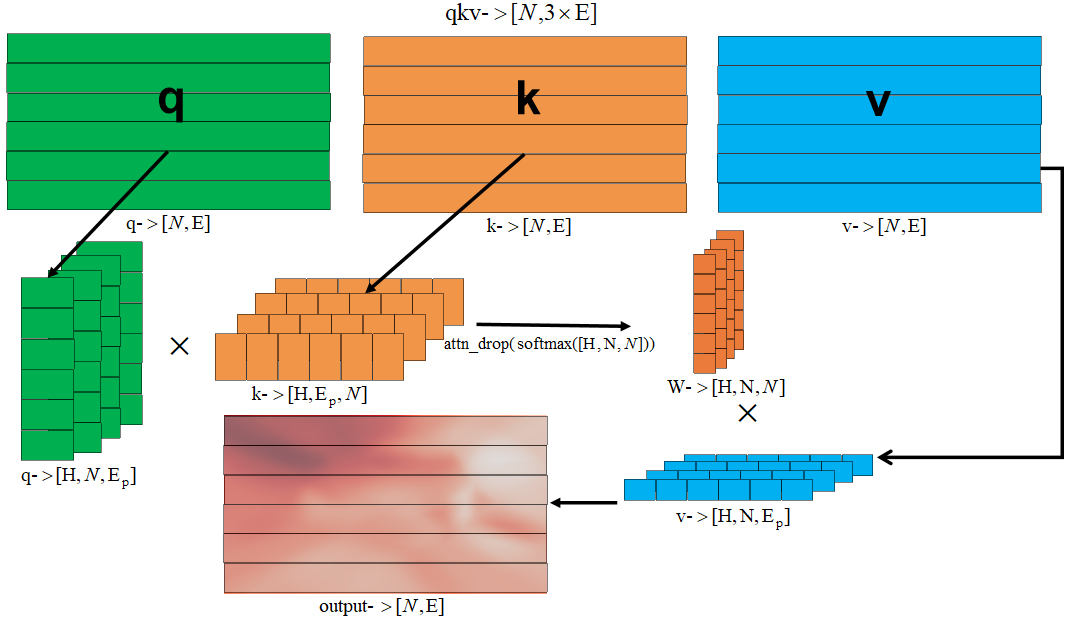
class Attention(nn.Module):def __init__(self,dim, # 输入token的dimnum_heads=8,qkv_bias=False,qk_scale=None,attn_drop_ratio=0.,proj_drop_ratio=0.):super(Attention, self).__init__()self.num_heads = num_headshead_dim = dim // num_headsself.scale = qk_scale or head_dim -0.5self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)self.attn_drop = nn.Dropout(attn_drop_ratio)self.proj = nn.Linear(dim, dim)self.proj_drop = nn.Dropout(proj_drop_ratio)def forward(self, x):# [batch_size, num_patches + 1, total_embed_dim]B, N, C = x.shape# qkv(): -> [batch_size, num_patches + 1, 3 * total_embed_dim]# reshape: -> [batch_size, num_patches + 1, 3, num_heads, embed_dim_per_head]# permute: -> [3, batch_size, num_heads, num_patches + 1, embed_dim_per_head]qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)# [batch_size, num_heads, num_patches + 1, embed_dim_per_head]q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)# transpose: -> [batch_size, num_heads, embed_dim_per_head, num_patches + 1]# @: multiply -> [batch_size, num_heads, num_patches + 1, num_patches + 1]attn = (q @ k.transpose(-2, -1)) * self.scaleattn = attn.softmax(dim=-1)attn = self.attn_drop(attn)# @: multiply -> [batch_size, num_heads, num_patches + 1, embed_dim_per_head]# transpose: -> [batch_size, num_patches + 1, num_heads, embed_dim_per_head]# reshape: -> [batch_size, num_patches + 1, total_embed_dim]x = (attn @ v).transpose(1, 2).reshape(B, N, C)x = self.proj(x)x = self.proj_drop(x)return x
demo在动态流程图中的对应部分:

不考虑全连接的偏置,下图简单举例了3个Linear(3,2)和1个nn.Linear(3,6)再切片没有本质区别。
因此,无论q、k、v是特征F分别与3个Linear(dim,dim)操作获得,还是和一个nn.Linear(dim,3×dim)操作再切片获得,没有任何区别。

MLP Head
MLP Headl流程如下图所示(不考虑batchsize):
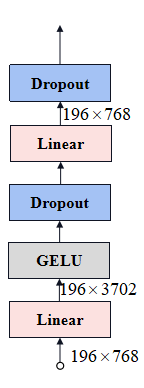
class Mlp(nn.Module):"""MLP as used in Vision Transformer, MLP-Mixer and related networks"""def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):super().__init__()out_features = out_features or in_featureshidden_features = hidden_features or in_featuresself.fc1 = nn.Linear(in_features, hidden_features)self.act = act_layer()self.fc2 = nn.Linear(hidden_features, out_features)self.drop = nn.Dropout(drop)def forward(self, x):x = self.fc1(x)x = self.act(x)x = self.drop(x)x = self.fc2(x)x = self.drop(x)return x
demo在动态流程图中的对应部分:
完整代码
【参考代码部分】,博主为了方便讲解作了细微修改。
"""
original code from rwightman:
https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vision_transformer.py
"""
from functools import partial
from collections import OrderedDictimport torch
import torch.nn as nndef drop_path(x, drop_prob: float = 0., training: bool = False):"""Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).This is the same as the DropConnect impl I created for EfficientNet, etc networks, however,the original name is misleading as 'Drop Connect' is a different form of dropout in a separate paper...See discussion: https://github.com/tensorflow/tpu/issues/494#issuecomment-532968956 ... I've opted forchanging the layer and argument names to 'drop path' rather than mix DropConnect as a layer name and use'survival rate' as the argument."""if drop_prob == 0. or not training:return xkeep_prob = 1 - drop_probshape = (x.shape[0],) + (1,) * (x.ndim - 1) # (shape[0],1,1,1)random_tensor = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device) # rand范围在[0~1]之间, +keep_prob在[keep_prob~keep_prob+1]之间random_tensor.floor_() # 只保留0或者1output = x.div(keep_prob) * random_tensor # x.div(keep_prob)个人理解是为了强化保留部分的xreturn outputclass DropPath(nn.Module):"""Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks)."""def __init__(self, drop_prob=None):super(DropPath, self).__init__()self.drop_prob = drop_probdef forward(self, x):return drop_path(x, self.drop_prob, self.training)class PatchEmbed(nn.Module):"""2D Image to Patch Embedding"""def __init__(self, img_size=224, patch_size=16, in_c=3, embed_dim=768, norm_layer=None):super().__init__()# 图片分辨率 h wimg_size = (img_size, img_size)# 卷积核大小patch_size = (patch_size, patch_size)self.img_size = img_sizeself.patch_size = patch_size# 分别计算w、h方向上的patch的个数self.grid_size = (img_size[0] // patch_size[0], img_size[1] // patch_size[1])# 一张图片的pacth个数self.num_patches = self.grid_size[0] * self.grid_size[1]# 卷积的步长巧妙地实现图片切分操作,而后与patch大小一致的卷积核完成线性映射self.proj = nn.Conv2d(in_c, embed_dim, kernel_size=patch_size, stride=patch_size)self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity() # nn.Identity()恒等函数 f(x)=xdef forward(self, x):B, C, H, W = x.shapeassert H == self.img_size[0] and W == self.img_size[1], \\f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."# flatten: [B, C, H, W] -> [B, C, HW]# transpose: [B, C, HW] -> [B, HW, C]# 一维展平x = self.proj(x).flatten(2).transpose(1, 2)x = self.norm(x)return xclass PositionEmbs(nn.Module):def __init__(self, num_patches, emb_dim, dropout_rate=0.1):super(PositionEmbs, self).__init__()self.pos_embedding = nn.Parameter(torch.zeros(1, num_patches + 1, emb_dim))if dropout_rate > 0:self.dropout = nn.Dropout(dropout_rate)else:self.dropout = Nonenn.init.trunc_normal_(self.pos_embedding, std=0.02)def forward(self, x):out = x + self.pos_embeddingif self.dropout:out = self.dropout(out)return outclass Attention(nn.Module):def __init__(self,dim, # 输入token的dimnum_heads=8,qkv_bias=False,qk_scale=None,attn_drop_ratio=0.,proj_drop_ratio=0.):super(Attention, self).__init__()self.num_heads = num_headshead_dim = dim // num_headsself.scale = qk_scale or head_dim -0.5self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)self.attn_drop = nn.Dropout(attn_drop_ratio)self.proj = nn.Linear(dim, dim)self.proj_drop = nn.Dropout(proj_drop_ratio)def forward(self, x):# [batch_size, num_patches + 1, total_embed_dim]B, N, C = x.shape# qkv(): -> [batch_size, num_patches + 1, 3 * total_embed_dim]# reshape: -> [batch_size, num_patches + 1, 3, num_heads, embed_dim_per_head]# permute: -> [3, batch_size, num_heads, num_patches + 1, embed_dim_per_head]qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)# [batch_size, num_heads, num_patches + 1, embed_dim_per_head]q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)# transpose: -> [batch_size, num_heads, embed_dim_per_head, num_patches + 1]# @: multiply -> [batch_size, num_heads, num_patches + 1, num_patches + 1]attn = (q @ k.transpose(-2, -1)) * self.scaleattn = attn.softmax(dim=-1)attn = self.attn_drop(attn)# @: multiply -> [batch_size, num_heads, num_patches + 1, embed_dim_per_head]# transpose: -> [batch_size, num_patches + 1, num_heads, embed_dim_per_head]# reshape: -> [batch_size, num_patches + 1, total_embed_dim]x = (attn @ v).transpose(1, 2).reshape(B, N, C)x = self.proj(x)x = self.proj_drop(x)return xclass Mlp(nn.Module):"""MLP as used in Vision Transformer, MLP-Mixer and related networks"""def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):super().__init__()out_features = out_features or in_featureshidden_features = hidden_features or in_featuresself.fc1 = nn.Linear(in_features, hidden_features)self.act = act_layer()self.fc2 = nn.Linear(hidden_features, out_features)self.drop = nn.Dropout(drop)def forward(self, x):x = self.fc1(x)x = self.act(x)x = self.drop(x)x = self.fc2(x)x = self.drop(x)return xclass Block(nn.Module):def __init__(self,dim,num_heads,mlp_ratio=4.,qkv_bias=False,qk_scale=None,drop_ratio=0.,attn_drop_ratio=0.,drop_path_ratio=0.,act_layer=nn.GELU,norm_layer=nn.LayerNorm):super(Block, self).__init__()self.norm1 = norm_layer(dim)# Multi-head attention模块self.attn = Attention(dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,attn_drop_ratio=attn_drop_ratio, proj_drop_ratio=drop_ratio)# NOTE: drop path for stochastic depth, we shall see if this is better than dropout hereself.drop_path = DropPath(drop_path_ratio) if drop_path_ratio > 0. else nn.Identity()self.norm2 = norm_layer(dim)mlp_hidden_dim = int(dim * mlp_ratio)# MLP Head模块self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop_ratio)def forward(self, x):x = x + self.drop_path(self.attn(self.norm1(x)))x = x + self.drop_path(self.mlp(self.norm2(x)))return xclass VisionTransformer(nn.Module):def __init__(self, img_size=224, patch_size=16, in_c=3, num_classes=1000,embed_dim=768, depth=12, num_heads=12, mlp_ratio=4.0, qkv_bias=True,qk_scale=None, representation_size=None, distilled=False, drop_ratio=0.,attn_drop_ratio=0., drop_path_ratio=0., embed_layer=PatchEmbed, norm_layer=None,act_layer=None):"""Args:img_size (int, tuple): input image sizepatch_size (int, tuple): patch sizein_c (int): number of input channelsnum_classes (int): number of classes for classification headembed_dim (int): embedding dimensiondepth (int): depth of transformernum_heads (int): number of attention headsmlp_ratio (int): ratio of mlp hidden dim to embedding dimqkv_bias (bool): enable bias for qkv if Trueqk_scale (float): override default qk scale of head_dim -0.5 if setrepresentation_size (Optional[int]): enable and set representation layer (pre-logits) to this value if setdistilled (bool): model includes a distillation token and head as in DeiT modelsdrop_ratio (float): dropout rateattn_drop_ratio (float): attention dropout ratedrop_path_ratio (float): stochastic depth rateembed_layer (nn.Module): patch embedding layernorm_layer: (nn.Module): normalization layer"""super(VisionTransformer, self).__init__()# 类别个数self.num_classes = num_classes# embed_dim默认tansformer的base 768self.num_features = self.embed_dim = embed_dim # num_features for consistency with other models# 源码distilled是为了其他任务,分类暂时不考虑self.num_tokens = 2 if distilled else 1# LayerNorm:对每单个batch进行的归一化norm_layer = norm_layer or partial(nn.LayerNorm, eps=1e-6)# act_layer默认tansformer的GELUact_layer = act_layer or nn.GELU# embed_layer默认是patch embedding,在其他应用中应该会有其他选择# patch embedding过程self.patch_embed = embed_layer(img_size=img_size, patch_size=patch_size, in_c=in_c, embed_dim=embed_dim)# patche个数num_patches = self.patch_embed.num_patches# class tokenself.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))self.dist_token = nn.Parameter(torch.zeros(1, 1, embed_dim)) if distilled else None# positional embedding过程self.pos_embedding = PositionEmbs(num_patches, embed_dim, drop_ratio)# self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + self.num_tokens, embed_dim))# self.pos_drop = nn.Dropout(p=drop_ratio)# depth是Block的个数# 不同block层数 drop_ratio的概率不同,越深度越高dpr = [x.item() for x in torch.linspace(0, drop_path_ratio, depth)] # stochastic depth decay rule# blocks搭建self.blocks = nn.Sequential(*[Block(dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,drop_ratio=drop_ratio, attn_drop_ratio=attn_drop_ratio, drop_path_ratio=dpr[i],norm_layer=norm_layer, act_layer=act_layer)for i in range(depth)])self.norm = norm_layer(embed_dim)# Representation layerif representation_size and not distilled:self.has_logits = Trueself.num_features = representation_sizeself.pre_logits = nn.Sequential(OrderedDict([("fc", nn.Linear(embed_dim, representation_size)),("act", nn.Tanh())]))else:self.has_logits = Falseself.pre_logits = nn.Identity()# Classifier head(s)self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()self.head_dist = Noneif distilled:self.head_dist = nn.Linear(self.embed_dim, self.num_classes) if num_classes > 0 else nn.Identity()# Weight initif self.dist_token is not None:nn.init.trunc_normal_(self.dist_token, std=0.02)nn.init.trunc_normal_(self.cls_token, std=0.02)self.apply(_init_vit_weights)def forward_features(self, x):# [B, C, H, W] -> [B, num_patches, embed_dim]x = self.patch_embed(x) # [B, 196, 768]# [1, 1, 768] -> [B, 1, 768]cls_token = self.cls_token.expand(x.shape[0], -1, -1)# self.dist_token暂时可以忽略if self.dist_token is None:x = torch.cat((cls_token, x), dim=1) # [B, 197, 768]else:x = torch.cat((cls_token, self.dist_token.expand(x.shape[0], -1, -1), x), dim=1)x = self.pos_embedding(x)# x = self.pos_drop(x + self.pos_embed)x = self.blocks(x)x = self.norm(x)if self.dist_token is None:return self.pre_logits(x[:, 0])else:return x[:, 0], x[:, 1]def forward(self, x):x = self.forward_features(x)if self.head_dist is not None:x, x_dist = self.head(x[0]), self.head_dist(x[1])if self.training and not torch.jit.is_scripting():# during inference, return the average of both classifier predictionsreturn x, x_distelse:return (x + x_dist) / 2else:x = self.head(x)return xdef _init_vit_weights(m):"""ViT weight initialization:param m: module"""if isinstance(m, nn.Linear):nn.init.trunc_normal_(m.weight, std=.01)if m.bias is not None:nn.init.zeros_(m.bias)elif isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight, mode="fan_out")if m.bias is not None:nn.init.zeros_(m.bias)elif isinstance(m, nn.LayerNorm):nn.init.zeros_(m.bias)nn.init.ones_(m.weight)def vit_base_patch16_224(num_classes: int = 1000):"""ViT-Base model (ViT-B/16) from original paper (https://arxiv.org/abs/2010.11929).ImageNet-1k weights @ 224x224, source https://github.com/google-research/vision_transformer.weights ported from official Google JAX impl:链接: https://pan.baidu.com/s/1zqb08naP0RPqqfSXfkB2EA 密码: eu9f"""model = VisionTransformer(img_size=224,patch_size=16,embed_dim=768,depth=12,num_heads=12,representation_size=None,num_classes=num_classes)return modeldef vit_base_patch16_224_in21k(num_classes: int = 21843, has_logits: bool = True):"""ViT-Base model (ViT-B/16) from original paper (https://arxiv.org/abs/2010.11929).ImageNet-21k weights @ 224x224, source https://github.com/google-research/vision_transformer.weights ported from official Google JAX impl:https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-vitjx/jx_vit_base_patch16_224_in21k-e5005f0a.pth"""model = VisionTransformer(img_size=224,patch_size=16,embed_dim=768,depth=12,num_heads=12,representation_size=768 if has_logits else None,num_classes=num_classes)return modeldef vit_base_patch32_224(num_classes: int = 1000):"""ViT-Base model (ViT-B/32) from original paper (https://arxiv.org/abs/2010.11929).ImageNet-1k weights @ 224x224, source https://github.com/google-research/vision_transformer.weights ported from official Google JAX impl:链接: https://pan.baidu.com/s/1hCv0U8pQomwAtHBYc4hmZg 密码: s5hl"""model = VisionTransformer(img_size=224,patch_size=32,embed_dim=768,depth=12,num_heads=12,representation_size=None,num_classes=num_classes)return modeldef vit_base_patch32_224_in21k(num_classes: int = 21843, has_logits: bool = True):"""ViT-Base model (ViT-B/32) from original paper (https://arxiv.org/abs/2010.11929).ImageNet-21k weights @ 224x224, source https://github.com/google-research/vision_transformer.weights ported from official Google JAX impl:https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-vitjx/jx_vit_base_patch32_224_in21k-8db57226.pth"""model = VisionTransformer(img_size=224,patch_size=32,embed_dim=768,depth=12,num_heads=12,representation_size=768 if has_logits else None,num_classes=num_classes)return modeldef vit_large_patch16_224(num_classes: int = 1000):"""ViT-Large model (ViT-L/16) from original paper (https://arxiv.org/abs/2010.11929).ImageNet-1k weights @ 224x224, source https://github.com/google-research/vision_transformer.weights ported from official Google JAX impl:链接: https://pan.baidu.com/s/1cxBgZJJ6qUWPSBNcE4TdRQ 密码: qqt8"""model = VisionTransformer(img_size=224,patch_size=16,embed_dim=1024,depth=24,num_heads=16,representation_size=None,num_classes=num_classes)return modeldef vit_large_patch16_224_in21k(num_classes: int = 21843, has_logits: bool = True):"""ViT-Large model (ViT-L/16) from original paper (https://arxiv.org/abs/2010.11929).ImageNet-21k weights @ 224x224, source https://github.com/google-research/vision_transformer.weights ported from official Google JAX impl:https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-vitjx/jx_vit_large_patch16_224_in21k-606da67d.pth"""model = VisionTransformer(img_size=224,patch_size=16,embed_dim=1024,depth=24,num_heads=16,representation_size=1024 if has_logits else None,num_classes=num_classes)return modeldef vit_large_patch32_224_in21k(num_classes: int = 21843, has_logits: bool = True):"""ViT-Large model (ViT-L/32) from original paper (https://arxiv.org/abs/2010.11929).ImageNet-21k weights @ 224x224, source https://github.com/google-research/vision_transformer.weights ported from official Google JAX impl:https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-vitjx/jx_vit_large_patch32_224_in21k-9046d2e7.pth"""model = VisionTransformer(img_size=224,patch_size=32,embed_dim=1024,depth=24,num_heads=16,representation_size=1024 if has_logits else None,num_classes=num_classes)return modeldef vit_huge_patch14_224_in21k(num_classes: int = 21843, has_logits: bool = True):"""ViT-Huge model (ViT-H/14) from original paper (https://arxiv.org/abs/2010.11929).ImageNet-21k weights @ 224x224, source https://github.com/google-research/vision_transformer.NOTE: converted weights not currently available, too large for github release hosting."""model = VisionTransformer(img_size=224,patch_size=14,embed_dim=1280,depth=32,num_heads=16,representation_size=1280 if has_logits else None,num_classes=num_classes)return model总结
尽可能简单、详细的介绍了深度可分卷积的原理和卷积过程,讲解了ViT模型的结构和pytorch代码。