看完这篇文章你就彻底懂啦{保姆级讲解}-----(LeetCode刷题704数组二分查找) 2023.4.17

目录
前言
本文章一部分内容参考于《代码随想录》----如有侵权请联系作者删除即可,撰写本文章主要目的在于记录自己学习体会并分享给大家,全篇并不仅仅是复制粘贴,更多的是加入了自己的思考,希望读完此篇文章能真正帮助到您!!!
数组的定义
数组是由n(n>=1)个相同类型的数据元素构成的有限序列,每个数据元素称为一个数组元素,每个元素在n个线性关系中的序号称为该元素的下标,下标的取值范围为数组的维界。
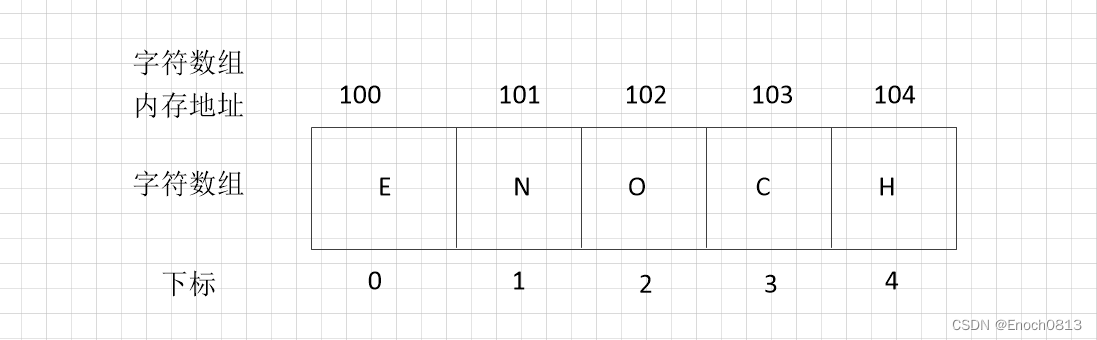 由上图可知:
由上图可知:
数组下标都是从0开始的数组内存空间的地址是连续的
数组的存储结构
对于多维数组,有两种映射方式,按行优先和按列优先。以二维数组为例,按行优先存储的基本思想是:先行后列,先存储行号较小的元素,行号相等先存储列号较小的元素。

算法题(LeetCode 704.二分查找)—(保姆级别讲解)
力扣题目链接

分析题目
- 处理数据类型为
整型数组 - 该数组为
有序数组即升序数组 - 该数组中的元素是
不重复的 - 上述条件中的
2和3是我们决定使用二分查找的关键
什么是二分查找?
我们会使用有序索引数组来表示被查找的目标值target可能存在的子数组的大小范围。在查找时,我们先将被查找的目标值和子数组的中间值比较。如果被查找的目标值小于中间值,我们就在左子数组中继续查找,如果大于,我们就在右子数组中继续查找,否则中间值就是我们要找的目标。
算法思想(重要)
二分查找其实有两种写法:
左闭右闭-----------[left, right]左闭右开-----------[left, right)
*至于为什么是两种写法后面会阐述,但是在这里我想声明一点,第二种写法本人不推荐,徒增算法难度,我们学习算法的初心不是算法越难越好,而是如何用最简单的算法思想解决我们的问题,这才是最主要的。所以本篇文章不会讨论第二种,如果对第二种写法感兴趣的可以自行探索。 *
第一种写法代码:
// (写法一) 左闭右闭区间 [left, right]
int search(int* nums, int numsSize, int target){int left = 0;int right = numsSize-1;int middle = 0;while(left<=right) {middle = (left+right)/2; if(nums[middle] > target) {right = middle-1;} else if(nums[middle] < target) {left = middle+1;} else if(nums[middle] == target){return middle;}} return -1;
}
时间复杂度:O(log n)
空间复杂度:O(1)
好!按照老样子,接下来开始详细讲解每行代码的用处,以及为什么这样写!
int search(int* nums, int numsSize, int target)
//函数入口参数分别为int* nums, int numsSize, int target,其中nums是int类型的指针,指向了其目标数组,numsSize为数组元素个数,target为数组目标值。
int left = 0;int right = numsSize-1;int middle = 0;
//初始化部分,左边界left初始化为0(因为数组下标是从0开始的),右边界right初始化为numsSize-1(因为数组下标是从0开始的,也就是0~numsSize-1),middle初始化为0(也就是计算中间值的下标)
while(left<=right)
//熟悉二分查找的都应该知道最终只会有三种情况,分别是left>right,left=right,left>right,当left>right证明该算法已经遍历结束也就代表其目标数组中没有我们要寻找的目标值(target)。
middle = (left+right)/2;
//计算中间值下标的公式,举个例子,假设目标数组中有6个元素,即下标为0~5,那么在第一次二分查找时计算middle值为(0+5)/2 = 2,即下标为2对应的middle值与target值比较大小。
if(nums[middle] > target) {right = middle-1;}
//根据二分查找的算法思想可知,当中间值大于target值时,意味着target值可能位于[left,middle-1]这个区间内,所以需要将right赋值为middle-1。
else if(nums[middle] < target) {left = middle+1;}
//根据二分查找的算法思想可知,当中间值小于target值时,意味着target值可能位于[middle+1,right]这个区间内,所以需要将left赋值为middle+1。
else if(nums[middle] == target){return middle;}
//根据二分查找的算法思想可知,当中间值等于target值时,意味着当前遍历的middle下标对应的值即为我们所寻找的目标值。
return -1;
//如果都不满足上述条件,则代表目标数组中没有我们所寻找的目标值。
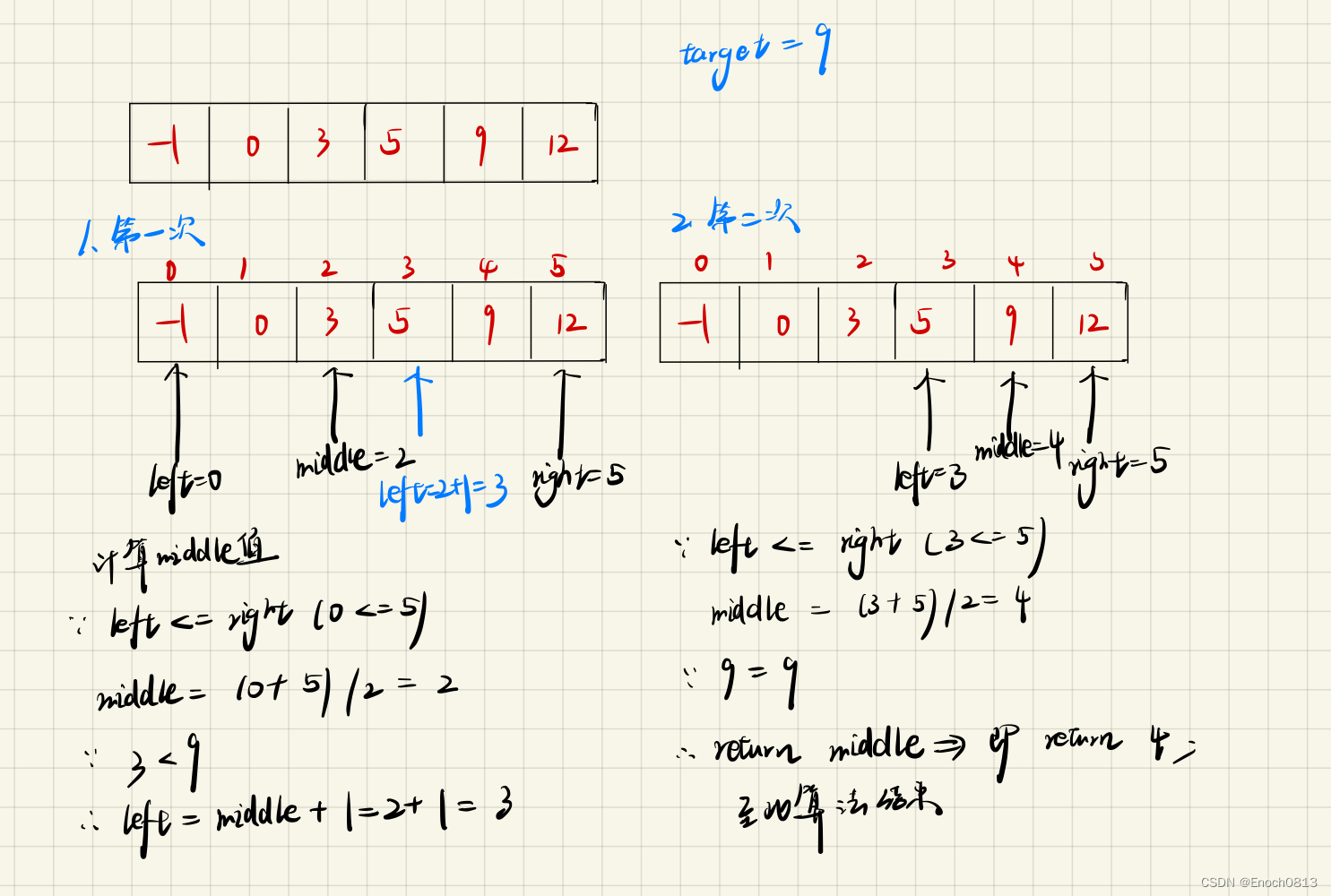
为了更能让大家了解二分查找的算法思想,作者特意画了一张图供大家观看!!!
第二种写法代码(本人不推荐):
// (版本二) 左闭右开区间 [left, right)
int search(int* nums, int numsSize, int target){int length = numsSize;int left = 0;int right = length; //定义target在左闭右开的区间里,即:[left, right)int middle = 0;while(left < right){ // left == right时,区间[left, right)属于空集,所以用 < 避免该情况int middle = left + (right - left) / 2;if(nums[middle] < target){//target位于(middle , right) 中为保证集合区间的左闭右开性,可等价为[middle + 1,right)left = middle + 1;}else if(nums[middle] > target){//target位于[left, middle)中right = middle ;}else{ // nums[middle] == target ,找到目标值targetreturn middle;}}//未找到目标值,返回-1return -1;
}
时间复杂度:O(log n)
空间复杂度:O(1)
//第二种写法相对于第一种写法的主要区别在于右边界right下标的选取,举个例子,初始阶段,left = 0,但是第二种写法中将right下标设置为numsSize,而不是第一种写法的numsSize-1,虽然改动了这个,但是在以后的判断中间值和target值时,会增加一些难度,例如当中间值大于target值时,意味着target值可能位于[left,middle-1]的区间内,但是由于是第二种写法,所以这里就只需将middle值赋值给right值即可,细心一点会发现和middle值小于target值的情况处理是不一样的,所以在实际的编写算法过程中容易犯错,徒增算法难度。所以第二种写法本人不推荐(没必要和自己过不去,懂得都懂)。
结束语
如果觉得这篇文章还不错的话,记得点赞 ,支持下!!!