MongoDB实现---WiredTiger

WiredTiger
参考:https://zhuanlan.zhihu.com/p/265222573
- MongoDB默认的存储引擎,其和InnoDb类似
https://www.jianshu.com/p/f053e70f9b18
快速访问(CRUD)
内存预分配机制
- 预分配:MongoDB启动时,首先从整个主机内存中切一大块出来分给WiredTiger的Internal Cache,用于构建B-Tree中的各种page以及基于这些page的增删改查等操作。
- 数据页:默认的Internal Cache大小由下面的规则决定:比较50% of (RAM - 1 GB)和256MB的大小,取其中较大者;
- 索引页:主机内存再额外划一小块给MongoDB创建索引专用,默认最大值为500MB;
- 虚拟主存(虚拟硬盘):会将主机剩余的内存(排除其它进程的使用)作为文件系统缓存,供MongoDB使用;
- 快速IO:为了节省磁盘空间,集合和索引在磁盘上的数据是被压缩的,默认情况下集合采取的是块压缩算法,索引采取的是前缀压缩算法。
- 所有数据在File System Cache中的格式和在磁盘上的格式是一致的,将数据先加载到文件系统缓存,不但可以减少磁盘I/O次数,还能减少内存的占用;
- 索引加载到WiredTiger的Internal Cache后,格式与磁盘上的格式不一样,但仍能利用其前缀压缩的特性(即去掉索引字段上重复的前缀)减少对内存的占用;
- 集合数据加载到WiredTiger的Internal Cache后,其数据必须解压后才能被后续各种操作使用,因此格式与磁盘上和File System Cache都不一样。
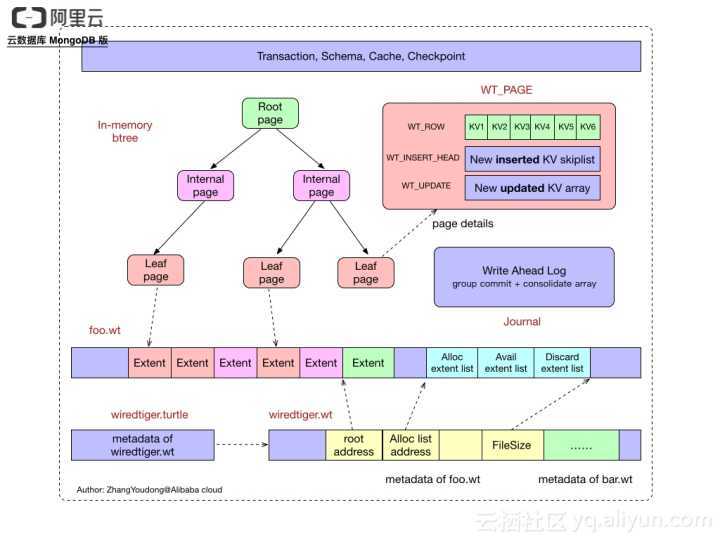
数据内存组织形式
- 通过WT_PAGE记录还未刷新化盘的数据的各个情况;
- 类似undo log:两个链表(Update List和Insert List)
- 通过B-Tree树(B+Tree)组织数据;
- 主要有三类节点:root page、internal page和leaf page;
- Leaf page:叶子结点(数据节点)
- 数据部分通过WT_ROW记录:
- 将保存从磁盘leaf page读取的keys/values值,每一条记录还有一个cell_offset变量,表示这条记录在page上的偏移量;
- UPDATE和INSERT部分通过WT_UPDATE和WT_INSERT_HEAD记录:
- WT_UPDATE:每条被修改的记录都会有一个数组元素与之对应,如果某条记录被多次修改,则会将所有修改值以链表形式保存。
- WT_INSERT_HEAD(插入数据记录):为了提高寻找待插入位置的效率,每个WT_INSERT_HEAD变量以跳转链表的形式构成。
- 数据部分通过WT_ROW记录:
检查点和脏页刷新
检查点
触发checkpoint执行,通常有如下几种情况:
- 按一定时间周期:默认60s,执行一次checkpoint;
- 按一定日志文件大小:当Journal日志文件大小达到2GB(如果已开启),执行一次checkpoint;
- 任何打开的数据文件被修改,关闭时将自动执行一次checkpoint。
脏页刷新
Page的生命周期
- 第一步:pages从磁盘读到内存;
- 第二步:pages在内存中被修改;
- 第三步:被修改的脏pages在内存被reconcile,完成后将discard这些pages。
- 可能由于检查点机制触发
- 也可能是用户(MongoDB)要求落盘;
- 脏页内脏数据达到一定比例;
- 第四步:pages被选中,加入淘汰队列,等待被evict线程淘汰出内存;
- 第五步:evict线程会将“干净“的pages直接从内存丢弃(因为相对于磁盘page来说没做任何修改),将经过reconcile处理后的磁盘映像写到磁盘再丢弃“脏的”pages。
MVCC
- 和MySQL的MVCC一样,实现依赖于:读视图和undo log
- 前面介绍了MongoDB的undolog的实现,下面介绍读视图:
WWT_TXN
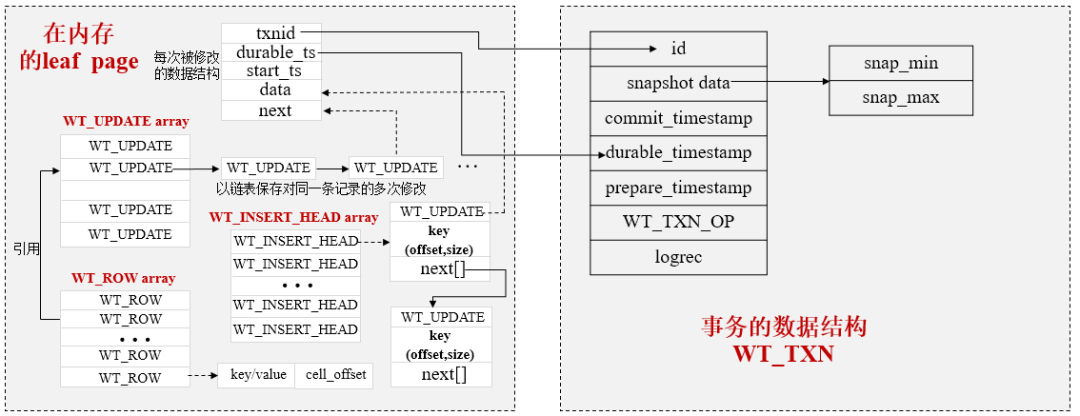
- MVCC的读视图实现:
- 数据结构:当前事务id、最小事务id、最大事务id+1、活跃事务id数组组成;
- 产生:当前事务可读、根据事务隔离性决定读视图产生的时机;
- 规则:略
- MongDB和MySQL实现的区别:
- MongoDB支持语句级别的设置:所以MVCC的读视图需要记录当前语句的隔离级别
- MongoDB通过事务提交和产生时间和事务id实现隔离检查控制;
- MongoDB通过文档的field的版本号version确定是否对修改进行乐观锁控制;
读视图
- id字段
- 这是事务的全局唯一标识,通过它与具体的操作关联,这样就能知道一个事务里面包含哪些操作。
- snapshot_data字段
- 因为MongoDB使用的是快照隔离级别的事务,这个字段保存事务的快照信息,具体来说它会有snap_min和snap_max两个属性,通过这两个属性能够计算一个事务开始时能够看到的数据范围,每个事务开始时都会构造一个这样的快照。
- commit_timestamp字段
- 表示事务提交的时间。
- durable_timestamp字段
- 表示事务修改的数据已持久化的时间,与具体操作里面的durable_ts字段关联。
- prepare_timestamp字段
- 表示事务开始准备的时间。
- WT_TXN_OP字段
- 包含事务的修改操作,用于事务rollback和生成事务的Journal日志。
- logrec字段
- 表示事务日志的缓存,用于在内存里面保存事务日志(对于MongoDB来Journal日志就是事务日志)。