kafka3.0安装使用

一:定义
Kafka传 统定义:Kafka是一个分布式的基于发布/订阅模式的消息队列(Message
Queue),主要应用于大数据实时处理领域。
Kafka最 新定义 : Kafka是 一个开源的 分 布式事件流平台 (Event Streaming
Platform),被数千家公司用于高性能数据管道、流分析、数据集成和关键任务应用
目 前企 业中比 较常 见的 消息 队列产 品主 要有 Kafka、ActiveMQ 、RabbitMQ 、
RocketMQ 等。
在大数据场景主要采用 Kafka 作为消息队列。在 JavaEE 开发中主要采用 ActiveMQ、
RabbitMQ、RocketMQ
二、kafka体系
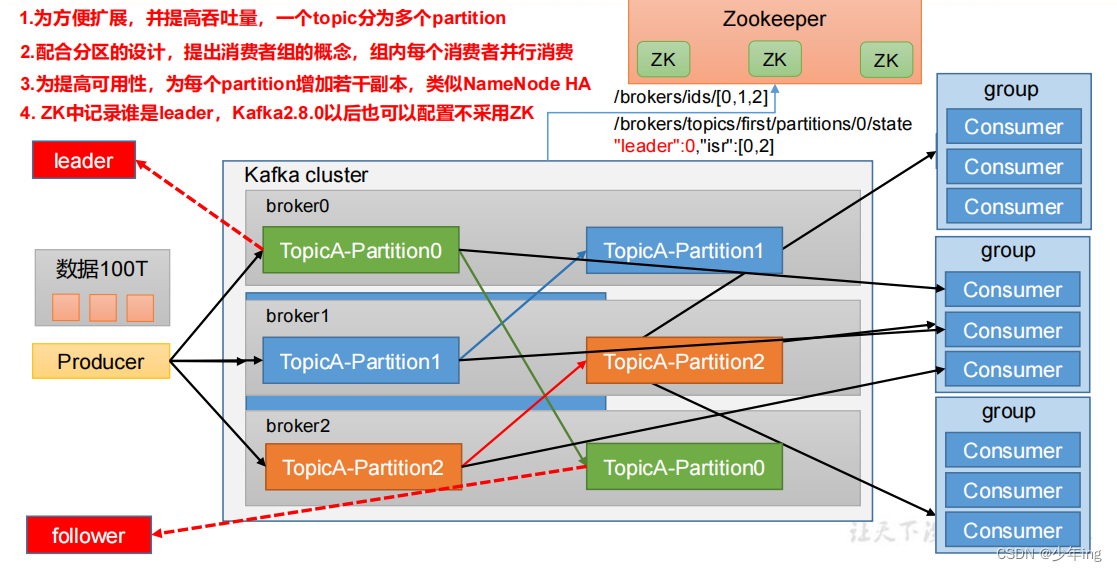
1、Producer:消息生产者,就是向 Kafka broker 发消息的客户端。
费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费;消费者组之间互不
影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
4、Broker:一台 Kafka 服务器就是一个 broker。一个集群由多个 broker 组成。一个
broker 可以容纳多个 topic。
5、Topic:可以理解为一个队列,生产者和消费者面向的都是一个 topic。
6、Partition:为了实现扩展性,一个非常大的 topic 可以分布到多个 broker(即服
务器)上,一个 topic 可以分为多个 partition,每个 partition 是一个有序的队列。
7、Replica:副本。一个 topic 的每个分区都有若干个副本,一个 Leader 和若干个
Follower。
8、Leader:每个分区多个副本的“主”,生产者发送数据的对象,以及消费者消费数
据的对象都是 Leader。
9、Follower:每个分区多个副本中的“从”,实时从 Leader 中同步数据,保持和
Leader 数据的同步。Leader 发生故障时,某个 Follower 会成为新的 Leader。
三、安装
1、环境背景
centos7.5
已安装zookeeper 可参考 zookeeper安装使用
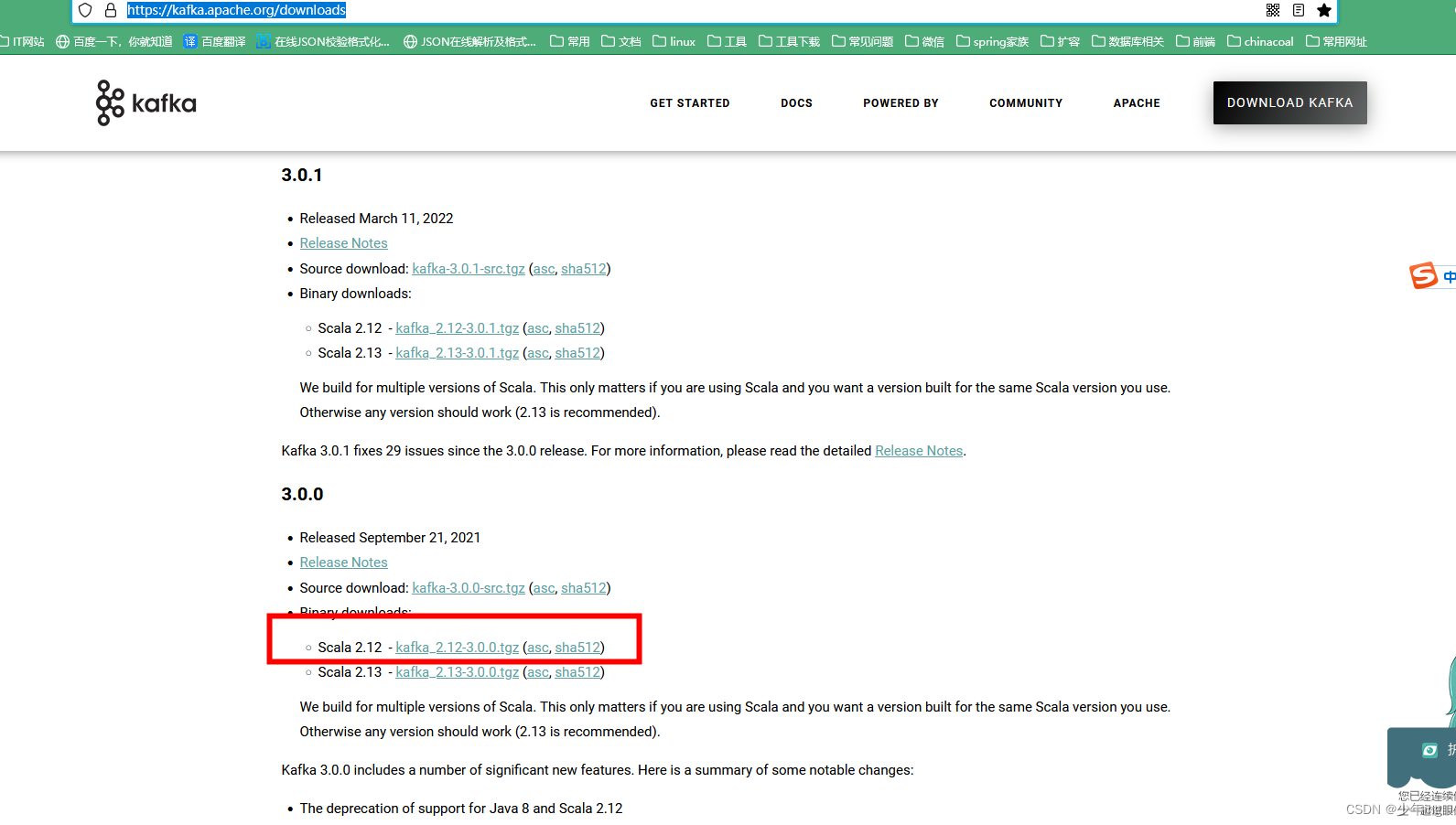
2、下载 版本3.0 非集群 后面单独出集群
官网 Apache Kafka

某云盘
链接:https://pan.baidu.com/s/181CN5W8g_Rjo42IG7xZqKA
提取码:v0w1
提取码:v0w1
3.上传解析
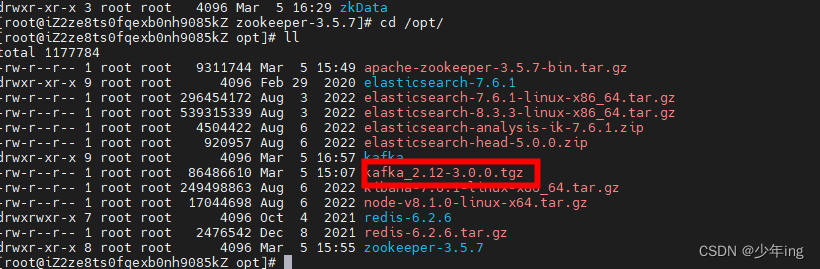
kafka_2.12-3.0.0.tgz压缩包上传/opt 目录
解压
tar -zxvf kafka_2.12-3.0.0.tgz
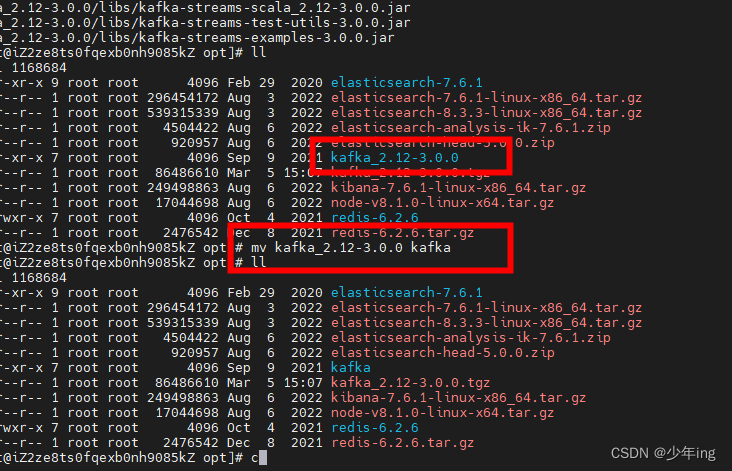
4、修改解压后的文件名称
mv kafka_2.12-3.0.0/ kafka
5、进入到/opt/kafka 目录,修改配置文件
cd config/
vim server.properties
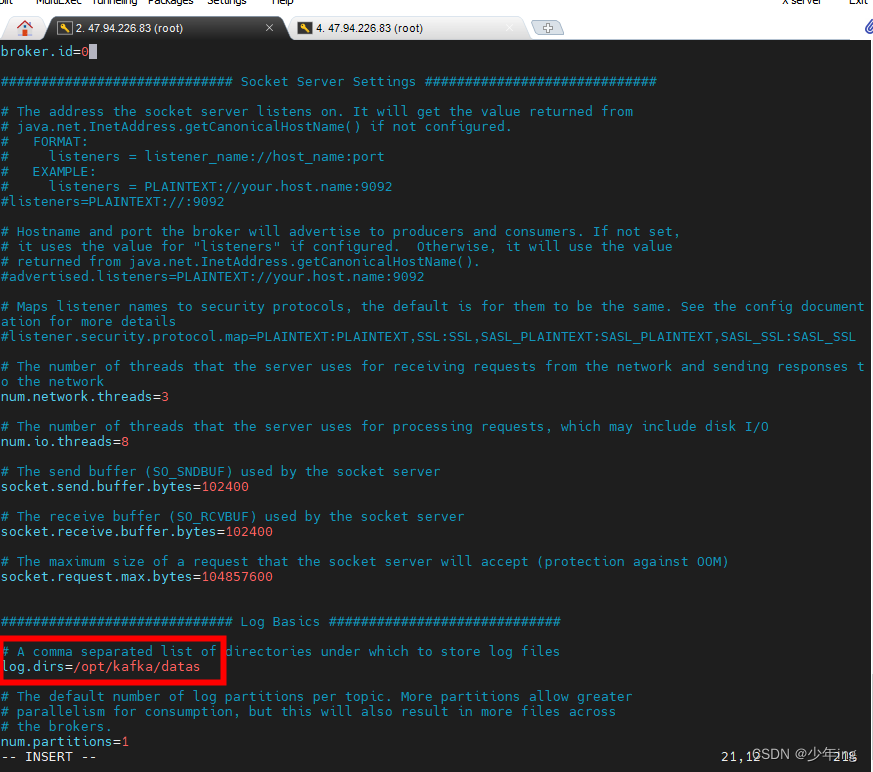
1、#kafka 运行日志(数据)存放的路径,路径不需要提前创建,kafka 自动帮你创建,可以
配置多个磁盘路径,路径与路径之间可以用","分隔
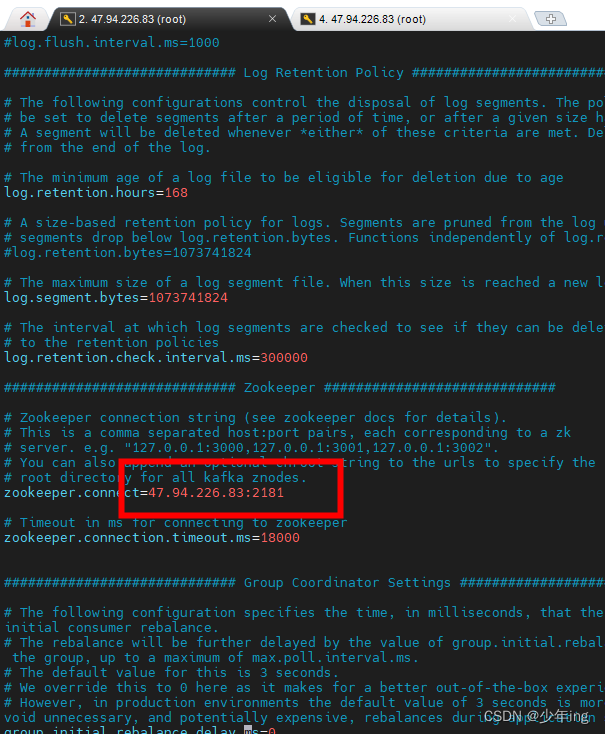
2、zookeeper连接地址
6、配置环境变量
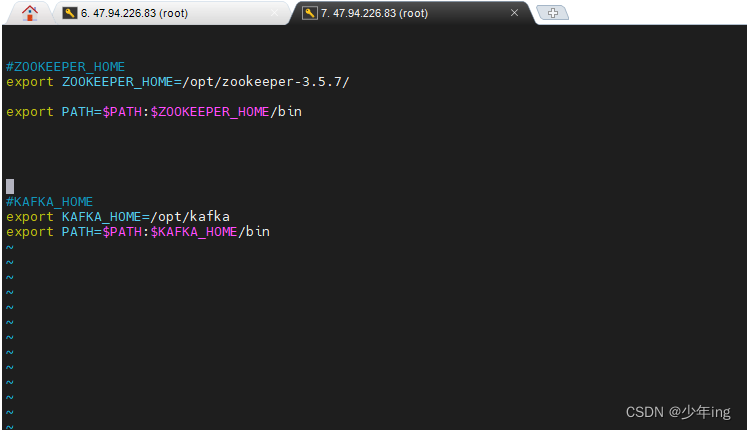
在/etc/profile.d/my_env.sh 文件中增加 kafka 环境变量配置
sudo vim /etc/profile.d/my_env.sh
增加如下内容
#KAFKA_HOME
export KAFKA_HOME=/opt/kafka
export PATH=$PATH:$KAFKA_HOME/bin
刷新环境变量
source /etc/profile
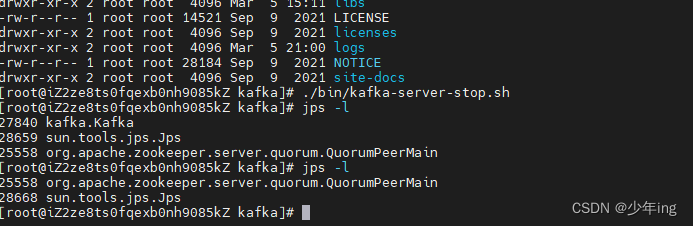
启动
bin/kafka-server-start.sh -daemon config/server.properties
查看进程
jps -l

停止
bin/kafka-server-stop.sh
此处先安装单节点 后面会出和spring Boot相关集成和集群安装
参照
kafka+springboot入门_龙谷情Sinoam的博客-CSDN博客
Kafka安装部署(3.0.0)_kafka3.0安装_tianyi6_6的博客-CSDN博客
Kafka3.0.0安装使用教程-CSDN博客