MapReduce笔记


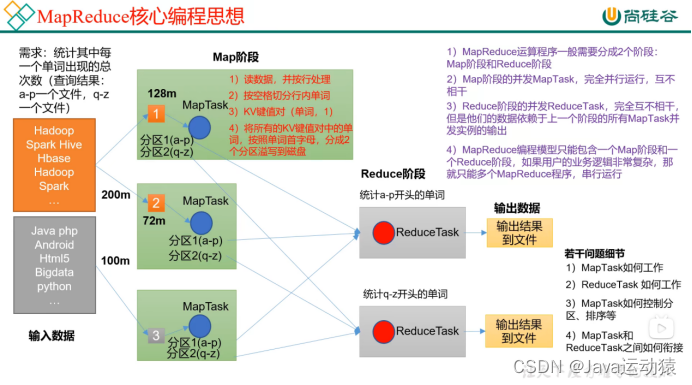



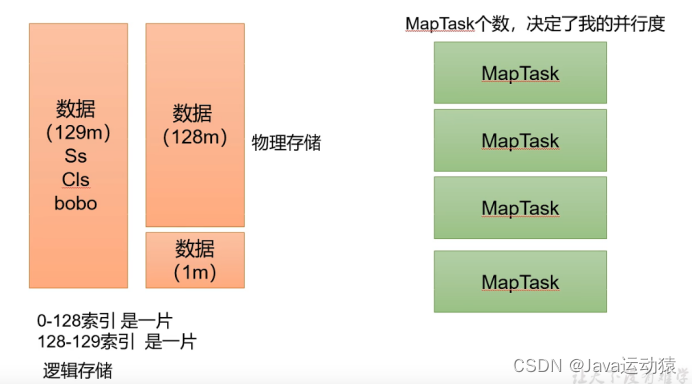
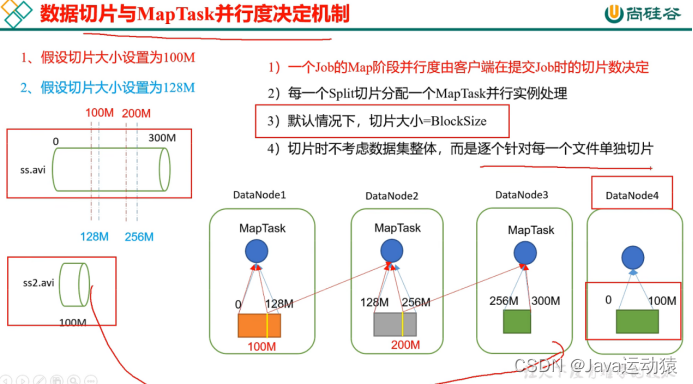

总计:切片就是对一个文件按逻辑进行切片,默认每128m为一个切片,不是物理切片,每个切片对应着一个mapTask进行处理。而且切片是针对每一个文件进行切片的,即一个文件一个文件切片,不是把所以待处理的文件总量放一起进行切片。


3:遍历一个文件ss.txt,这里要注意,每一个文件都是单独切片。
C:切片大小=blocksize,即128M
d:每次切片时,都会判断剩下的数据是否大于块(128M)的1.1倍,如果大于则继续切片,不大于就把剩下的数据划分为一个切片
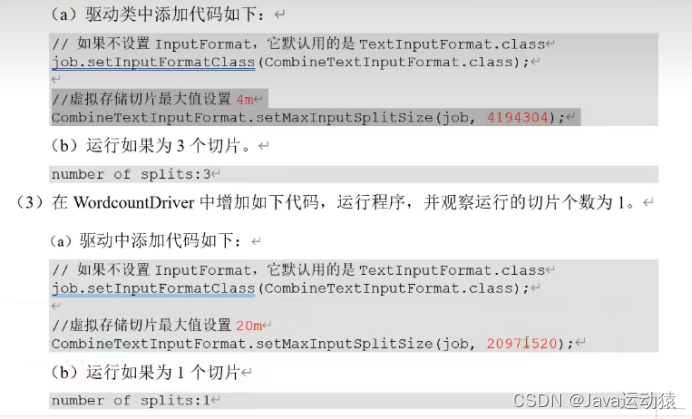
常用的几个切片机制:
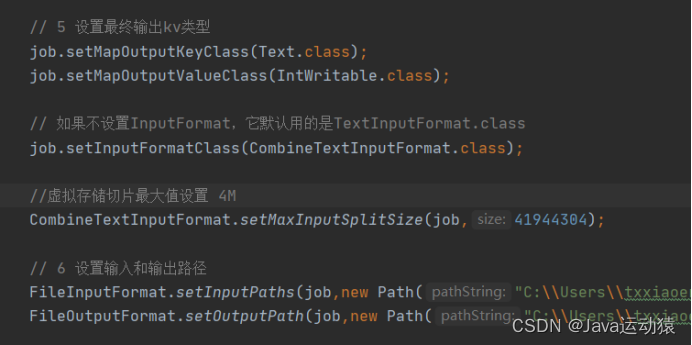
1.FileInputFormat、TextInputFormat、CombineTextInputFormat



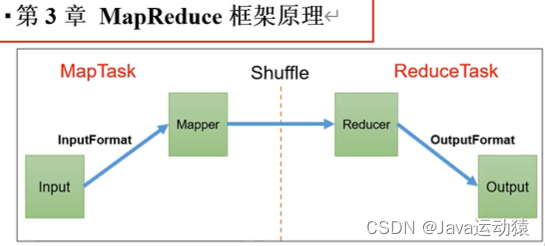
shuffle 阶段:即Map方法之后,Reduce方法之前的数据处理过程称之为Shuffle阶段。

MapReduce是如何将数据进行分区的:
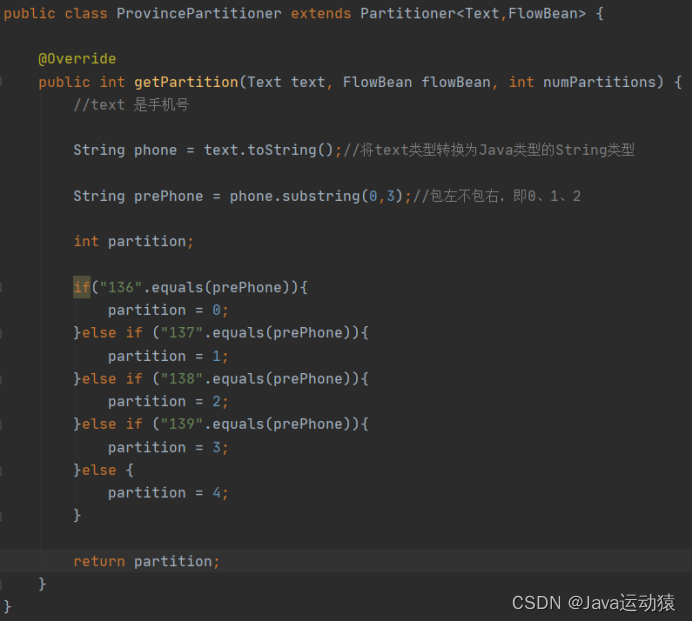
默认情况下,用户没法控制对key存储的分区,但可以继承Partitoner抽象类重写getPartiton方法,自定义控制key存储到哪个区,同时可以指定NumReduceTask的数量,如果不指定NumReduceTask的数量的话,系统默认数量为1,那么不会对key存储进行分区,都存放在一个文件里。


自定义Partitioner,重写分区代码逻辑,将手机号前三位不同进行划分区域,一共有5个分区。
job.setNumReduceTasks();设置ReduceTask的数量有规则,如下:

注意:第(4)点很重要,分区号必须从零开始,逐一累加,中间不能跳。

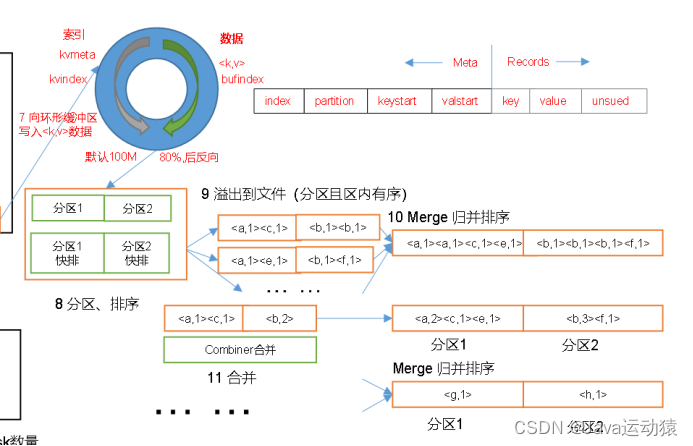

Combiner合并的过程是在环形缓冲区在写入磁盘过程之间的一个合并过程,将排序好的数据进行两次Combiner合并,第一次是将每一个分区排序好的数据进行第一次合并,第二次是将每一个分区排序好的数据进行第二次合并。因为第一次可能只合并了其中的一小部分,第二次将每一次合并的那一小部分再合并成总的数据。


注意:1.Combiner不能用于求数据的平均值,因为统计前和统计后进行除法会有误。但可以用于数据的加减,因为统计前和统计后不会对加减造成影响。
- 如果程序中没有了Reduce的话,那就别设置Combiner了,因为shuffle是在map输出和reduce输入之间的,没有reduce的话,数据直接就从map输出了,不会有shuffle的阶段。
- 实际上,reduce就相当于Combiner了,reduce的功能和Combiner的功能是一样的,所以直接调用reduce就可以完成Combiner的合并过程:job.setCombinerClass(wordCountReducer.class)
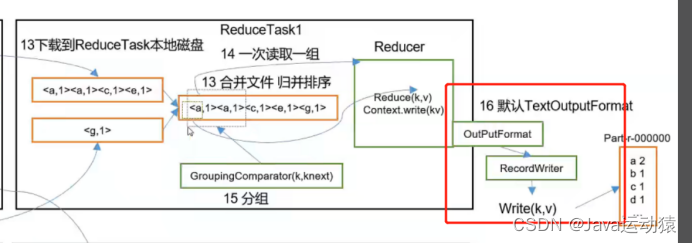
Reducer处理好的数据并不是直接写入文件,而是到OutPutFormat流那里,由RecordWriter方法进行写入文件中,所以我们可以自定义OutPutFormat来决定Reducer的数据是写入哪里。

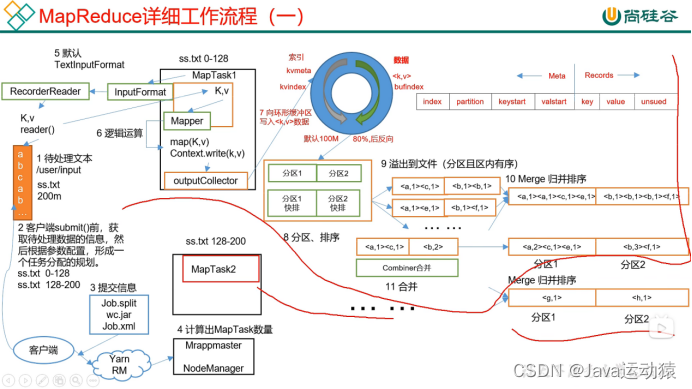
MapTask的工作机制:
五个阶段:Read阶段、Map阶段、Collect阶段、溢写阶段、Merge阶段
(1)Read阶段:默认用TextInputFormat进行读取数据,用RecordReader中的reader()方法进行读取,以(K,V)的形式传入Mapper中。
(2)Map阶段:map阶段就是用户在map方法中自定义业务代码,来实现需要的业务,用context.write()写(K,V)数据。
(3)Collect阶段:map写出的数据进入环形缓冲区,环形缓冲区一半存元数据,一半存数据,默认为100M,当数据写入环形缓冲区80%的时候,开始反向写,在环形缓冲区的数据会进行分区和排序(环形缓冲区的数据是存放在内存的)。
(4)溢写阶段:当环形缓冲区的数据达到80%的时候或将数据全部读完之后,会将分区且区内有序的数据溢写到磁盘中。
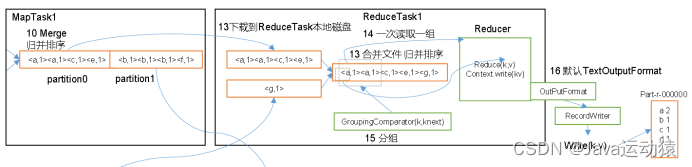
(5)Merge阶段:溢写到磁盘的数据会进行归并排序,将数据排序好。
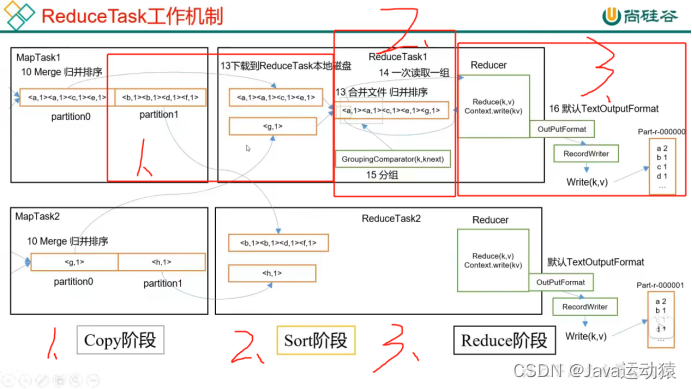
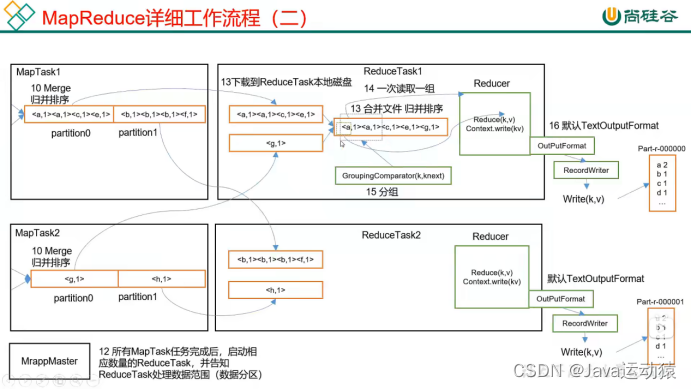
ReduceTask工作机制:
三个阶段:Copy阶段、Sort阶段、Reduce阶段
- Copy阶段:ReduceTask从MapTask上拉取(拷贝)数据,并对数据大小进行判断,如果超过一定阈值,则写到磁盘上,否则直接写到内存上。
- Sort阶段:拿到数据之后,ReduceTask会启动两个后台线程对内存和磁盘上的文件进行合并,以防止内存使用过多或磁盘上文件过多。由于各个MapTask已经对数据进行了局部的排序,所以ReduceTask只需要对所有数据进行一次归并排序即可。
- Reduce阶段:根据业务自定义reduce()函数,将计算的结果写到HDFS上。



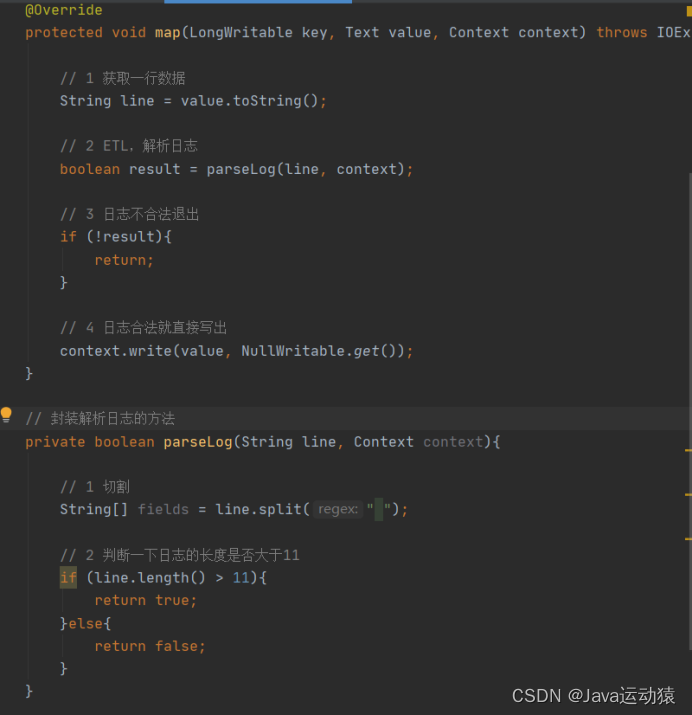
过滤掉不需要的数据,留下需要的数据,这里的代码是过滤掉一行数据的长度低于11的数据。
3.8 MapReduce开发总结
1)输入数据接口:InputFormat
(1)默认使用的实现类是:TextInputFormat
(2)TextInputFormat的功能逻辑是:一次读一行文本,然后将该行的起始偏移量作为key,行内容作为value返回。
(3)CombineTextInputFormat可以把多个小文件合并成一个切片处理,提高处理效率。
2)逻辑处理接口:Mapper
用户根据业务需求实现其中三个方法:setup() 初始化 map()用户的业务逻辑 cleanup () 关闭资源
3)Partitioner分区
(1)有默认实现 HashPartitioner,逻辑是根据key的哈希值和numReduces来返回一个分区号;key.hashCode()&Integer.MAXVALUE % numReduces
(2)如果业务上有特别的需求,可以自定义分区。
4)Comparable排序
(1)当我们用自定义的对象作为key来输出时,就必须要实现WritableComparable接口,重写其中的compareTo()方法。
(2)部分排序:对最终输出的每一个文件进行内部排序。
(3)全排序:对所有数据进行排序,通常只有一个Reduce。
(4)二次排序:排序的条件有两个,实现WritableComparable接口,重写其中的compareTo()方法。。
5)Combiner合并
Combiner合并可以提高程序执行效率,减少IO传输。
但是使用时必须不能影响原有的业务处理结果。(加减可以,乘除不行,比如求平均值不行)
提前聚合map,是解决数据倾斜的一个方法
6)逻辑处理接口:Reducer
用户根据业务需求实现其中三个方法:setup() 初始化 reduce()用户的业务逻辑 cleanup () 关闭资源
7)输出数据接口:OutputFormat
(1)默认实现类是TextOutputFormat,功能逻辑是:将每一个KV对,向目标文本文件输出一行。(按行输出到文件)
(2)用户还可以自定义OutputFormat。

