sqoop数据导出、脚本使用

目录
准备表与数据
数据导出
脚本调用
准备表与数据
mysql表
CREATE TABLE `user` (`id` int(20),`name` varchar(20)
)ENGINE=INNODB DEFAULT CHARSET=utf8;hive表
create table users(
id bigint,
name string
)
row format delimited fields terminated by "\\t";
数据导出
在 Sqoop 中,“导出”概念指:从大数据集群(HDFS,HIVE,HBASE)向非大数据集群 (RDBMS)中传输数据,叫做:导出,即使用 export 关键字。
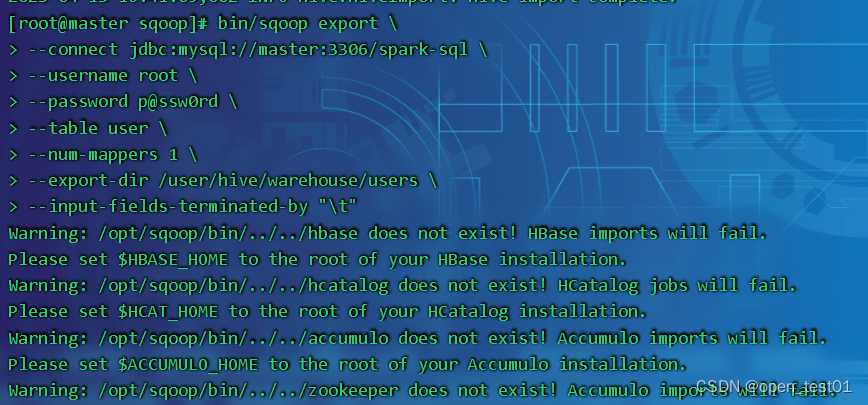
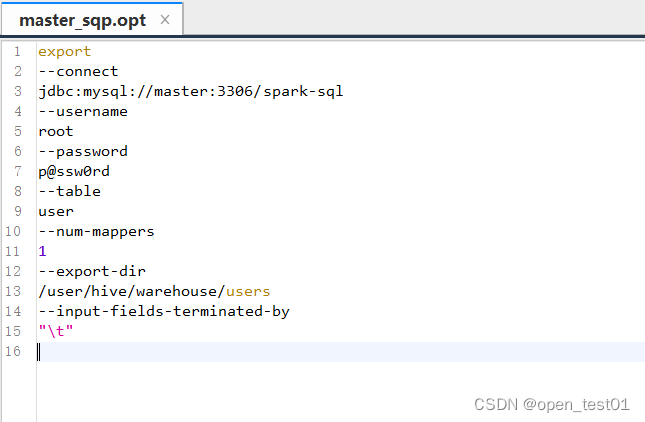
bin/sqoop export \\
--connect jdbc:mysql://master:3306/spark-sql \\
--username root \\
--password p@ssw0rd \\
--table user \\
--num-mappers 1 \\
--export-dir /user/hive/warehouse/users \\
--input-fields-terminated-by "\\t"参数解读:
bin/sqoop export \\ 导出命令
--connect jdbc:mysql://master:3306/spark-sql \\ mysql数据库路径
--username root \\ 用户名
--password p@ssw0rd \\ 用户密码
--table user \\ mysql表名
--num-mappers 1 \\ mr资源
--export-dir /user/hive/warehouse/users \\ hive表在hdfs上的存储路径
--input-fields-terminated-by "\\t" 分割列
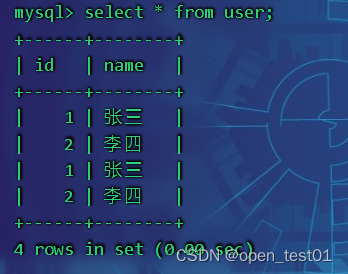
mysql中查看导入结果

脚本调用
创建脚本文件
在sqoop目录中创建一个job目录用于存放脚本
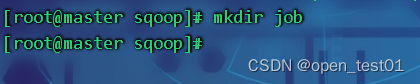
创建脚本文件

编写命令(以刚才导出数据为例)
执行脚本文件
[root@master sqoop]# bin/sqoop -options-file 目录名/脚本文件名

mysql中查看导入结果