100天精通Python丨黑科技篇 —— 26、代理ip技术(request)

据说:看我文章的帅帅 都有个习惯:先点赞、收藏再看
文章目录
一、背景知识:requests
欲练此功、必须先了解背景知识。python之所以强大,一个重要的原因就是,拿来即用的代码库丰富!
Python内置的urllib模块,用于访问网络资源。但是,它用起来比较麻烦,也缺少很多实用的高级功能。
更好的方案是使用requests
- get方法
- post方法
- header参数,模拟用户
- data参数,提交数据
- proxies参数,使用代理
1、pip安装requests
pip install requests
2、pycharm安装requests
举一反四,其它包的安装方法类似!

3、示例:一行代码使用requests
导入 Requests 模块:
import requests
然后,尝试获取某个网页。本例子中,我们来获取 Github 的公共时间线:
r = requests.get('https://api.github.com/events')
4、requests常用调用(get、post)
- GET 变量接受所有以 get 方式发送的请求,及浏览器地址栏中的 ?之后的内容。
- POST 变量接受所有以 post 方式发送的请求,例如,一个 form 以 method=post 提交
- REQUEST 支持两种方式发送过来的请求,即 post 和 get 它都可以接受,显示不显示要看传递方法,get 会显示在 url 中(有字符数限制),post 不会在 url 中显示,可以传递任意多的数据(只要服务器支持)。
5、requests返回参数
- r.status_code HTTP请求的返回状态,200表示连接成功,404表示失败
- r.text HTTP响应内容的字符串形式,即url对应的页面内容
- r.encoding 从HTTP header中猜测的响应内容编码方式(
- r.apparent_encoding 从内容中分析出的响应内容编码方式(备选编码方式)
- r.content HTTP响应内容的二进制形式
二、蜘蛛🕷🕷的背景知识
1、蜘蛛的应用场景
玩python的小伙伴,相信都听过蜘蛛🕷吧,他有以下10个方面的妙用,本文中,西红柿🍅将带领大家玩一下。
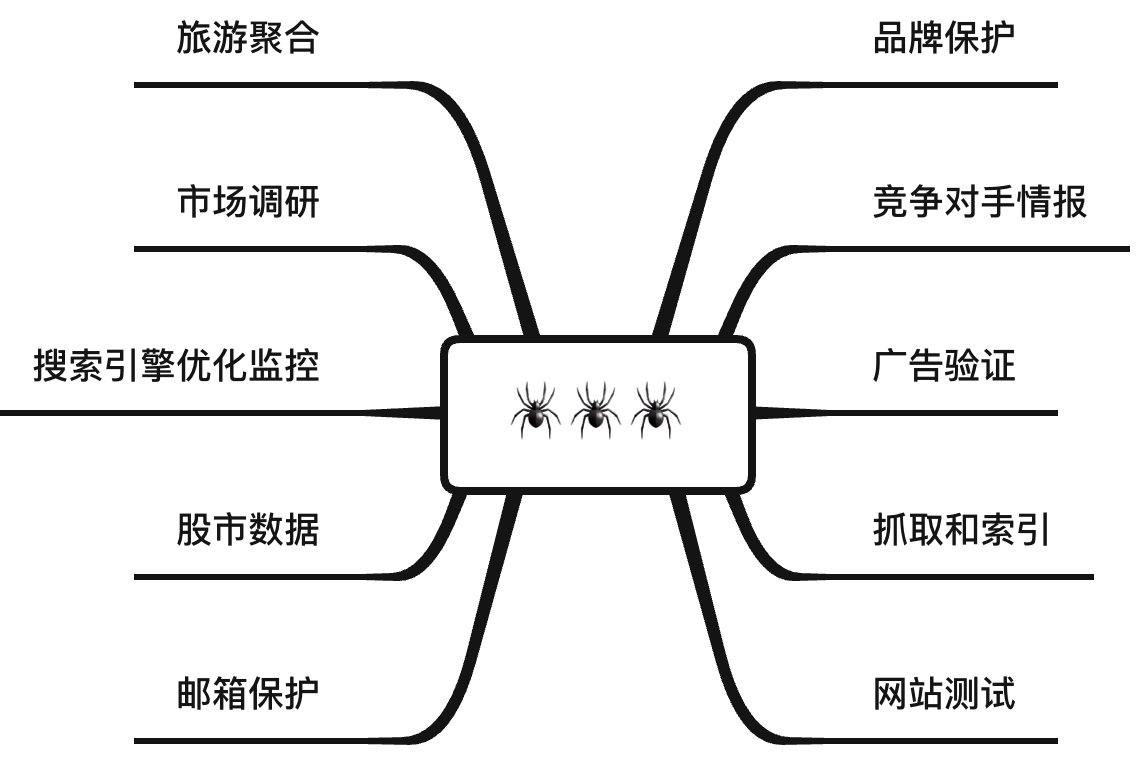
| 应用场景 | 用途解释 |
|---|---|
| 品牌保护 | 通过监控网络上的商标来保护品牌。 |
| 竞争对手情报 | 在不被屏蔽的情况下,抓取竞争对手公开数据信息, |
| 广告验证 | 确保广告在任何地点任何场景被正确的展示 |
| 抓取和索引 | 一个站点可能会将抓取限制为每分钟几个请求,但它们有数千万个页面。 |
| 网站测试 | 准确的测试始于设置正确的参数和正确的环境。 |
| 邮件保护 | 保护敏感数据通信,利用代理服务器应对网络攻击。 |
| 股市数据 | 大规模获取最新的股市信息。 |
| 搜索引擎优化监控 | 使用我们的实时爬虫,监控您的SEO实时情况。 |
| 市场调查 | 从任何位置获取准确的信息,例如可用性和价格。 |
| 旅游聚合 | 使用爬虫获取正确的机票价格和酒店价格。 |
2、动态ip的好
为什么要使用动态住宅IP?
真正的住宅IP地址,这意味着在您请求访问时被阻止的可能性较小并且成功率更高。
- 无限并发
- IP可用率>98%
- API调用频率:1秒
- HTTP、HTTPS和SOCKS5 协议
三、代理ip
我使用的是代理ip网站
1、api生成代理ip
def get_proxie(self, api_url):# 微信搜:信息技术智库,回复'源码'user_agent = 'Mozilla/5.0 (Linux; Android 10; EVR-AL00 Build/HUAWEIEVR-AL00; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/74.0.3729.186 Mobile Safari/537.36 baiduboxapp/11.0.5.12 (Baidu; P1 10)'headers = {'User-Agent': user_agent}res = requests.post(api_url,headers=headers, verify=True)proxie = "https://%s"%(res.text)proxies = {'http': proxie}is_valid, proxies = visitor.proxie_check(proxies)return is_valid, proxies
2、测试代理ip
def proxie_check(self, proxies):user_agent = 'Mozilla/5.0 (Linux; Android 10; EVR-AL00 Build/HUAWEIEVR-AL00; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/74.0.3729.186 Mobile Safari/537.36 baiduboxapp/11.0.5.12 (Baidu; P1 10)'headers = {'User-Agent': user_agent}res = requests.get("https://bbs.csdn.net/forums/ITID", headers=headers, proxies=proxies)is_valid = 0if res.status_code == 200 and "msg" not in str(proxies):is_valid = 1return is_valid, proxies
四、代理访问
在上一步中,我们拿到了代理ip。
代码解释:
- url为访问的地址
- proxies=proxie 为使用代理
class Visitor(object):def __init__(self):"""Inits Visitor with blah."""self.eggs = 0@time_decoratordef proxie_visit(self, proxie ,url):user_agent_list = ['Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) ''Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3','Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50','Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50','Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)','Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)','Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1','Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11','Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11','Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SE 2.X MetaSr 1.0; SE 2.X MetaSr 1.0; .NET CLR 2.0.50727; SE 2.X MetaSr 1.0)','Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0','Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1',]
# 随机挑选一个 user_agentuser_agent = random.choice(user_agent_list)Referer= 'https://www.baidu.com/' # 伪装成从baiduheaders = {'Referer': Referer,'User-Agent': user_agent}# visitres = requests.get(url, headers=headers, proxies=proxie)return res.text
到此,西红柿演示了:使用代码ip访问网站,这是一个简单的蜘蛛原型。 基于这个加以优化,可以实现很多有意思的事情,嘿嘿嘿,点到为止。
