基于redis实现分布式锁

结合java中的锁聊聊锁的本质中将锁的本质分成了两部分,来分析理解锁的本质,并结合了java中的锁从这两部分来分析理解
-
锁标志的存储
-
加锁时,遇到锁被占用该怎么办。
分布式锁的本质也是个锁,其实同样是从这两方面来分析。
-
锁标志的存储。
对于线程锁,锁标志的存储就需要放到所有线程都可以访问的地方,而线程都是共享进程的资源的,所以毫无疑问,锁标志都是放到进程中的,这样进程下的线程都是可以访问到。
而分布式环境下,进程可能分布在不同的机器节点上,锁的标志就必须放在所有进程都可以访问的地方,这个就已经脱离单节点操作系统的管辖了,必须去寻找外部的存储来存放这个锁标志。这也就是分布式锁的分布式的体现。当然也正式因为是以来外部存储,所以分布式锁边等更加复杂,更准确的说是对使用者更加复杂。
ps:线程锁一样的复杂,不过要么操作系统提供了一些机制、要么编译器提供了一些管程机制、或者编程语言提供了相应的sdk,复杂性都被操作系统或者语言给封装了,程序员其实都是拿来主义,直接使用就可以了。但是分布式锁不一样,因为以来外部存储,到目前为止,我还没有发现哪个语言会内置支持分布式锁的,所以这个复杂性不得不由程序员自己来cover了。
-
加锁时,遇到锁被占用该怎么办。
在来线程锁的时候我们不会特别关注,但是聊分布式锁的时候格外关注的几个点:
-
共享存储的高可靠
线程锁的锁标志是放在进程内存空间的,这个一定是可靠的。如果线程所在的内存都蹦了,进程都运行不下去崩了,那么进程下的所有线程也就不可能运行下去了。那就是系统都崩了,谈何分布式锁可用不可用
但是分布式锁就不一样了,以来的是外部存储。必须保证外部存储的高可用,或者说必须保证外部存储的可用性,不低于业务进程的可用性。简单粗暴点讲:不能因为分布式锁以来的外部存储gg了,导致业务进程运行不下去了。
-
加锁/释放锁要求是原子操作
-
加锁过程:读取、判断、加锁
-
释放锁过程:读取、判断、释放锁
线程锁也不会来讨论这个,因为线程锁的加锁和释放锁都是用的cpu的原子指令来保证的、或者操作系统的一些机制保证的,这个可以参考操作系统哲学这本书里降到的关于锁的两种实现方式:一种就是依赖操作系统的中断禁止来实现加锁/解锁的原子性、一种是利用cpu的CAS原子指令来实现。其实回到jdk的AQS,其实也是CAS指令实现的加锁/解锁。
但是分布式锁不一样,业务进程和分布式锁以来的外部存储都不在一个操作系统里运行,两者的交互往往还会有网络IO,所以操作系统和cpu原子指令都是用不上了,这个原子性就只能靠我们自己来保证的。
综合上述来看,实现分布式锁的第一步就是选择分布式锁以来的外部存储,基本条件就是:
-
这个存储组件的高可用
-
这个存储组件对外提供的api,能够原子的实现加锁/解锁
-
高性能:因为加锁/解锁过程都是和业务逻辑无关的,且在每个业务逻辑中都可能出现,如果性能不好会影响接口的响应。当然这个高性能也是相对的,看你系统的诉求。不用太刻意追求性能,比如你一个内部管理系统,用户一共就几十号人,那几乎就没必要考虑高性能问题,凡是现在还流行的存储组件毫无疑问都能满足你。
凡是满足这些条件的,都可以用来实现分布式锁的。不仅仅是一提起分布式锁,就习惯性的去了redis分布式锁、zk分布式锁。
实现分布式锁的第一步是选择分布式锁依赖的外部存储,那么第二步就是分布式锁的客户端api实现了。这个其实个人认为就是仁者见仁智者见智的一件事情了:
-
如果我们的目标是实现一个全行业/全集团都通用的分布式锁,那考虑的点可能就更多了,至少你实现的功能必须和现在大家对锁的认知是一致的,且使用习惯要和对应的语言提供的线程锁尽量保持一致,比如java就应该和jdk中的Lock接口一致。
-
如果我们的目标是实现满足我当前业务场景的,那个人认为还是怎么简单怎么来,有些棘手的问题,可以放弃,只要有方案能够保证不会出现问题就好。
ps:这里还是特别说明一下,在分布式环境中,经常会遇到的一个问题就是:一个请求过来后,可能要修改系统A、系统B、系统C的数据,很有可能就会出现系统AB成功了,但是系统C失败了,导致三个系统数据的不一致;以及rpc接口超时带来的未知结果等。这些问题本质上是个事务问题,所以在分布式环境中,解决这些问题的根本手段其实是分布式事务,但是目前的分布式事务技术还是比较重的操作,好使都是搞的,且使用成本也相对比较高。所以现在分布式事务的使用场景,其实基本还是在分布式数据库中,而分布式数据库对分布式锁的态度也是尽量优化成本地事务,比如通过一些数据分片数据的调度,将事务内修改的数据调度到同一个机器上去,那么事务就变成本地事务了,除非事务内操作的数据很多,调度成本高于了分布式锁成本,那就只能启用分布式锁,而这种情况,往往都是比较高的。所以在业务系统中,几乎每人会去真正使用分布式事务的,那这种怎么避免呢?
-
最简单且最有效的就是,接口必须保证幂等,然后重试。
-
有用户在场的,直接提示用户重试点击就好了。ps:网名已经被教育的非常好了。遇到问题刷新页面、疯狂点击已经是根深蒂固的了,不用担心偶发的失败需要重试会惹怒用户,只有一直重试一直失败才会惹怒用户。
-
没有用户在场的,系统巡检重试。保证数据最终是一致的,或者说最终透出给用户使用的数据是一致的。所以理论上讲,数据维护的生命期中,数据可以是分散到各个系统的,但是一定应该有一个出口系统对外负责,而这个系统用来控制状态机,最终的上架生效是原子性的就没有问题。比如:商品信息很多,包括基本信息、库存、价格等等,这些维护信息的维护可以是在各个系统重,但是商品的上架状态必须在一个支持事务的db中。只要没上架,各个系统重的数据不完整都ok,重试就好了。但是上架这个动作必须原子性,上架后对外展示的商品必须是完整的,不能缺胳膊少腿,那就不会有问题。
而对于分布式锁,解决的是多个进程同时进入临界区去操作受保护资源的问题。但是现在的OLTP场景,基本还是重度依赖底层的事务的,事务的隔离性的实现的一个重要手段其实就是锁,所以我们数据最终的正确性保证,还是重度依赖支持事务的db。只不过说如果我们的资源不是存储在支持事务的db种,又需要临界区来保护资源的访问,那分布式锁就排上用场了。
下面就从这些方面来分析怎么利用redis来实现分布式锁。
基于redis实现锁
-
高性能,不用多分析了,redis的性能杠杠的。
-
高可用,redis可以支持集群部署的。
-
加锁/释放锁的原子性。
-
redis的单线程执行单个命令对key-value的操作,那其实一定能保证单个命令对key-value的操作是原子的。
-
redis支持嵌入lua脚本,且执行lua脚本也是单线程来执行的,只有一个脚本执行完后,单线程才会干其他事情。所以执行lua脚本里的命令整体也是原子的。
所以,redis是有机制可以来实现加锁/释放锁的原子性的。
下面就来分析用单命令如何实现分布式锁,以及对应的问题,最终看Redisson怎么解决
加锁:setnx
释放锁:del
问题:如果setNx加锁成功,但是这个时候线程直接oom死掉了,甚至整个节点down了,就执行不到释放锁,或者执行del的时候偶发失败了。那就会导致这个锁一直不能释放
解决这个问题的办法:给锁对应的key加上一个过期时间,这样过期后这个key会自动删除,即自动释放掉。ps:这里需要注意,不能先setNx()然后再expire()设置过期时间,需要原子性操作,而setNx()在高版本中是可以直接指定过期时间的。
但是这个解决方式又引出另外两个问题:
-
锁保护的临界区逻辑执行时间超过了过期时间,那就可能存在多个进程进入到临界区执行。导致锁失效。
解决方式:租约。搞一个后台线程来监控锁,如果锁到期了还没释放,那就续租。其实这个租约的实现需要注意,在续租的时候,需要去判断到底是因为业务逻辑没有执行完就到期了、还是说业务逻辑已经执行完了删除key失败了导致到期了。如果是业务逻辑的执行时间大于了key的过期时间,那么应该续期;但如果是因为删除key导致的,那么就不应该续期,如果续了反而是有问题的。具体的可以参考redission
-
删除别人获取的锁。线程A执行setNx成功,开始执行临界区代码,但是临界区代码执行时间比较长,导致key过期失效了。这个时候线程B来执行setNx来获取锁,那么肯定就会成功。这个时候线程A执行完了临界区,就会执行del释放锁。这个时候他释放的其实就是线程B获取的锁。
或者说,线程A执行setNx加锁成功、线程B把锁当成一个普通的key-value给执行了del删除了,那么锁也就被释放了
解决方法:加锁的时候除了是指锁占用标识以外,还要带上客户端线程标识。释放锁的时候,判断是否是当前客户端加的锁。如果是,才能释放;如果不是就不能释放。
这种解决方式又带来了一个新的问题:redis的单个命令的执行在服务端是单线程完成的,所以单个命令是原子的。但是如果要先读取--判断--执行,那就需要另个命令,即先get、客户端判断、然后del,很明显这三个动作没办法保证原子的。
另外可重入问题:要支持可重入,单单只是个标记锁是否占用就是不够的,所以还需要记录同一线程加锁次数,加锁的时候,除了要setNx外,还需要incr技术值;释放锁的时候就需要判断是直接释放锁,还是只是decr计数值,而这些判断操作都是没有单命令可以来完成的。
解决方式:使用lua脚本来执行这三个操作。使用eval命令执行lua脚本时,redis会把整个lua脚本当成一个整体,在主线程中执行,因为是单线程执行,所以中间不会被打断,从而保证原子性。
单节点的可靠性比较差的问题,一旦故障,整个分布式锁就不可用了,所以需要不能使用单节点的redis,需要部署集群。
如果丢失的是数据是分布式锁的数据,那分布式锁就会失效。。
reids的集群主从同步是个异步过程,master切换可能丢失数据,如果只是当缓存使用,其实数据丢失是无所谓的。但是如果锁数据丢失,就有可能导致锁不住的问题。解决这个问题其实终极方案是改写redis的集群能力,像zk等一样,写入数据和master选举都要求大多数成功,去保证master切换不会有数据丢失(在分布式集群中,为了数据的可靠性,一般在日志复制的时候也都是会选择配置成,大多数副本复制成功后,才会认为数据写入成功,这样结合选举规则,保证数据的不丢失)。但是这么做就太重了。
这上面的问题,还都只是围绕着如何存储锁标志的问题(或者说如何原子性的去维护锁标志),锁的量大问题之二:遇到锁冲突要怎么办?还没涉及到
这个问题最简单的其实就是遇到锁失败了,直接返回失败,让业务方自己处理。其实很多分布式锁的使用场景,这个也就够了,所以自己实现的时候满足自己业务场景就好。如果要实现阻塞当前线程,参考下面的Redisson的实现。
redison实现分布式锁
Redssion是redis官方推荐的一个客户端之一,如果只是进行kv操作,个人认为jedis更好用,jedis对命令的封装和redis的cli命令保持一致的,使用起来其实更顺畅,但是Redission客户端基于Redlock算法实现了分布式锁。
而且Redisson在实现分布式锁的时候,是实现了jdk的Lock接口,这对使用者来说就非常棒,锁初始化后使用起来跟jdk的Lock一模一样,几乎没有额外的成本,但需要注意的是,它没有支持条件变量。
下面就大概看下Redisson是怎么依赖redis的key-value存储,以及redis提供的对外服务来实现一个分布式锁的,如下以常见的公平锁实现为例来学习期原理,明白了一个,那么再看其他的锁功能,就比较容易了。
Redission实现的分布式锁依赖redis存储的数据主要分为如下几个:
-
key=锁标记key,value=hashmap类型,field=加锁时候UUID生成的一个随机数+加锁线程id,fieldvalue=加锁次数。用这个方式来解决可重入的问题。
-
key=redisson_lock_queue:{lockkey},value是一个list类型。这个其实就是用来模拟阻塞队列的。当加锁的时候发现锁已经被占用,即key=锁标记key的数据存在,那么就说明锁已经被其他线程获取了,所以当前线程要么就直接返回、要么就需要最等待。这个队列就是用来支持最等待的,将因锁被占用而阻塞的线程放到这个list中,即list中的元素就是加锁时候UUID生成的一个随机数+加锁线程id。
-
key=redisson_lock_timeout:{lockkey},value是一个sortedset。里面存储的就是:member=加锁时候UUID生成的一个随机数+加锁线程id,score=锁等待超时的时间点。用来支持带超时时间等待的获取锁操作
-
一个订阅频道:channel=redisson_lock__channel:{lockkey}:随机数+加锁时候UUID生成的一个随机数+加锁线程id。用来支持获取锁如果锁占用阻塞当前线程,当锁释放的时候要通知线程唤醒。
执行加锁/释放锁的lua脚本的执行是在RedissonBaseLock#evalWriteAsync()中,这个方法会使用info命令获取到replication的信息,然后有多少个slave(connected_slaves)启动多少线程异步到salve上去执行lua脚本,这其实就是RedLock的一部分,防止集群master切换数据丢失导致的锁不住。
加锁
-
key=锁标记key,value=hashmap类型,field=加锁时候UUID生成的一个随机数+加锁线程id,fieldvalue=加锁次数。用这个方式来解决可重入的问题。
-
key=redisson_lock_timeout:{lockkey},value是一个sortedset。里面存储的就是:member=加锁时候UUID生成的一个随机数+加锁线程id,score=锁等待超时的时间点。用来支持带超时时间等待的获取锁擦欧洲欧。
-
key=redisson_lock_queue:{lockkey},value是一个list类型。这个其实就是用来模拟阻塞队列的。当加锁的时候发现锁已经被占用,即key=锁标记key的数据存在,那么就说明锁已经被其他线程获取了,所以当前线程要么就直接返回、要么就需要最等待。这个队列就是用来支持最等待的,将因锁被占用而阻塞的线程放到这个list中,即list中的元素就是加锁时候UUID生成的一个随机数+加锁线程id。
lock()的lua脚本
几个变量的值如下:
KEYS[1]:锁标记key,
KEYS[2]:阻塞队列:key=redisson_lock_queue:{lockkey},value是list,元素是加锁线程的唯一标识,取值=uuid随机数+线程号
KEYS[3]:等待锁阻塞时间:key=redisson_lock_timeout:{锁标记key},value=sortedset,member=加锁线程的唯一标识,socre=阻塞等待超时时间
ARGV[1]:租期时间,单位:ms
ARGV[2]:标识加锁线程的唯一标识,取值=uuid随机数+线程号
ARGV[3]:获取锁等待时间。
ARGV[4]:当前时间
while true do local firstThreadId2 = redis.call('lindex', KEYS[2], 0);if firstThreadId2 == false then break;end;local timeout = tonumber(redis.call('zscore', KEYS[3], firstThreadId2));if timeout <= tonumber(ARGV[4]) then // remove the item from the queue and timeout set// NOTE we do not alter any other timeoutredis.call('zrem', KEYS[3], firstThreadId2);redis.call('lpop', KEYS[2]);else break;end;
end;// 如下是获取锁成功的逻辑
if (redis.call('exists', KEYS[1]) == 0) and ((redis.call('exists', KEYS[2]) == 0) or (redis.call('lindex', KEYS[2], 0) == ARGV[2])) then // 将当前线程从阻塞队列和超时队列中移除redis.call('lpop', KEYS[2]);redis.call('zrem', KEYS[3], ARGV[2]);local keys = redis.call('zrange', KEYS[3], 0, -1);for i = 1, #keys, 1 do redis.call('zincrby', KEYS[3], -tonumber(ARGV[3]), keys[i]);end;// 获取锁成功。设置key=锁标志key那条数据的超时事件redis.call('hset', KEYS[1], ARGV[2], 1);redis.call('pexpire', KEYS[1], ARGV[1]);return nil;
end;// 可重入逻辑
if redis.call('hexists', KEYS[1], ARGV[2]) == 1 then redis.call('hincrby', KEYS[1], ARGV[2],1);redis.call('pexpire', KEYS[1], ARGV[1]);return nil;
end;// 如果是获取锁失败的逻辑
// 检查当前线程是否已经在阻塞队列中了
local timeout = redis.call('zscore', KEYS[3], ARGV[2]);
if timeout ~= false then return timeout - tonumber(ARGV[3]) - tonumber(ARGV[4]);
end;// 如果当前线程不在阻塞队列中,则会将当前线程添加到阻塞队列中
local lastThreadId = redis.call('lindex', KEYS[2], -1);
local ttl;
if lastThreadId ~= false and lastThreadId ~= ARGV[2] then ttl = tonumber(redis.call('zscore', KEYS[3], lastThreadId)) - tonumber(ARGV[4]);
else ttl = redis.call('pttl', KEYS[1]);
end;
local timeout = ttl tonumber(ARGV[3]) tonumber(ARGV[4]);
if redis.call('zadd', KEYS[3], timeout, ARGV[2]) == 1 then redis.call('rpush', KEYS[2], ARGV[2]);
end;
return ttl;在使用lock()加锁的时候,除了使用lua脚本去操作了redis的三个key以外。如果发现锁被占用而导致加锁不成功。Redisson就会订阅一个redis的channel,然后将当前线程阻塞在Semaphore上(这个信号量其实就和冲入次数是对应的)。在unlock()的lua脚本中,会给加锁进程/线程发送一个锁释放的消息。当订阅线程收到这个信号的时候,就会Semaphore.release(),当Semaphore信号量变成0的时候,当前线程接触阻塞。
代码在RedissonLock#lock():
ps:while()循环获得锁后,是需要从channel上注销的,截图没有截全
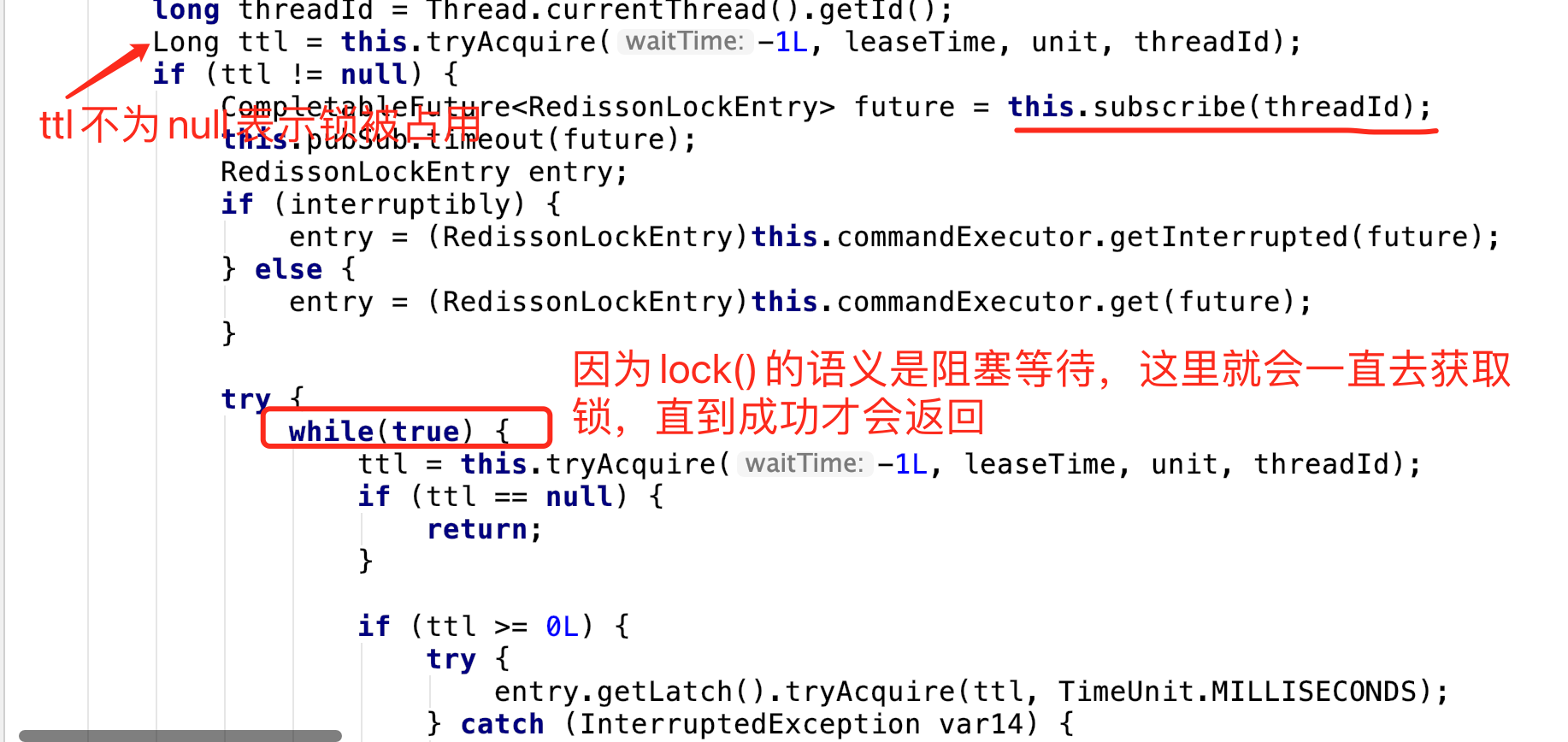
ps:进程内的线程锁,jdk的Lock自己在AQS里为锁实现了阻塞等待队列,而lock#unlock()的时候是调用了notify()来唤醒阻塞在锁上的线程的。只不过redis这里利用订阅频道实现了一个分布式版本。
trylock()的lua脚本
KEYS[1]:锁标记key,
KEYS[2]:阻塞队列:key=redisson_lock_queue:{lockkey},value是list,元素是加锁线程的唯一标识,取值=uuid随机数+线程号
KEYS[3]:等待锁阻塞时间:key=redisson_lock_timeout:{锁标记key},value=sortedset,member=加锁线程的唯一标识,socre=阻塞等待超时时间
ARGV[1]:租期时间,单位:ms
ARGV[2]:标识加锁线程的唯一标识,取值=uuid随机数+线程号
ARGV[3]:当前时间
ARGV[4]:获取锁等待时间。
while true do local firstThreadId2 = redis.call('lindex', KEYS[2], 0); if firstThreadId2 == false then break; end; local timeout = tonumber(redis.call('zscore', KEYS[3], firstThreadId2)); if timeout <= tonumber(ARGV[3]) then redis.call('zrem', KEYS[3], firstThreadId2); redis.call('lpop', KEYS[2]); else break; end;
end; if (redis.call('exists', KEYS[1]) == 0) and ((redis.call('exists', KEYS[2]) == 0) or (redis.call('lindex', KEYS[2], 0) == ARGV[2])) then redis.call('lpop', KEYS[2]); redis.call('zrem', KEYS[3], ARGV[2]); // decrease timeouts for all waiting in the queuelocal keys = redis.call('zrange', KEYS[3], 0, -1); for i = 1, #keys, 1 do redis.call('zincrby', KEYS[3], -tonumber(ARGV[4]), keys[i]); end; redis.call('hset', KEYS[1], ARGV[2], 1); redis.call('pexpire', KEYS[1], ARGV[1]); return nil;
end;
if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then redis.call('hincrby', KEYS[1], ARGV[2], 1); redis.call('pexpire', KEYS[1], ARGV[1]); return nil;
end;
return 1;trylock()只是去尝试获取锁,哪怕是锁被占用也不会阻塞当前线程,直接返回,所以就不会有订阅reids的channel以及无限重试逻辑了。
锁的租期续租
但是不管是lock()还是trylock(),加锁成功后,都提供了锁的续租机制。只是说需要注意,这个机制是在初始化锁的时候,没有指定过期时间才会启用的。
在lock()/tryLock()接口中,都有一个指定leaseTime的重载方法,即锁的租期时间,加锁的时候会用expire将这个时间设置为key-value的过期时间。也就是说自动续租机制是没有指定这个值才会启用的。

但也需要注意的是,不是说不指定,锁key对应的数据就是不过期的,而是有个默认值(30s),当然可以通过配置来修改这个参数,只是这个不能是在加锁的时候指定。

scheduleExpirationRenewal()中可以发现:
-
每次续租就是配置的租期时间,即默认30s
-
定时任务是每隔租期的三分之一时间就去取执行一次续租。即默认情况下是10s
-
只要续租报错、或者lua脚本返回key已经不存在了,那就不会在执行续租了
续租lua脚本
KEYS[1]:锁标记key
VRGV[1]:租期时间
VRGV[2]:加锁线程的唯一标识,取值=uuid+线程id
if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) thenredis.call('pexpire', KEYS[1], ARGV[1]);return 1;
end;
return 0;释放锁
unluck()的lua脚本
KEYS[1]:锁标记key,
KEYS[2]:阻塞队列:key=redisson_lock_queue:{lockkey},value是list,元素是加锁线程的唯一标识,取值=uuid随机数+线程号
KEYS[3]:等待锁阻塞时间:key=redisson_lock_timeout:{锁标记key},value=sortedset,member=加锁线程的唯一标识,socre=阻塞等待超时时间KEYS[4]
KEYS[3]:订阅频道。当因为等待锁挂起的时候,用于解锁时通知挂起线程。
ARGV[1]:给订阅频道发送的消息内容。这些写死的是0,表示解锁消息
ARGV[2]:租期时间
ARGV[3]:加锁线程的唯一标识,取值=uuid随机数+线程号
ARGV[4]:当前时间
while true do local firstThreadId2 = redis.call('lindex', KEYS[2], 0);if firstThreadId2 == false then break;end; local timeout = tonumber(redis.call('zscore', KEYS[3], firstThreadId2));if timeout <= tonumber(ARGV[4]) then redis.call('zrem', KEYS[3], firstThreadId2); redis.call('lpop', KEYS[2]); else break;end;
end;if (redis.call('exists', KEYS[1]) == 0) then local nextThreadId = redis.call('lindex', KEYS[2], 0); if nextThreadId ~= false then redis.call('publish', KEYS[4] .. ':' .. nextThreadId, ARGV[1]); end; return 1; end; if (redis.call('hexists', KEYS[1], ARGV[3]) == 0) then return nil; end; local counter = redis.call('hincrby', KEYS[1], ARGV[3], -1); if (counter > 0) then redis.call('pexpire', KEYS[1], ARGV[2]); return 0; end; redis.call('del', KEYS[1]); local nextThreadId = redis.call('lindex', KEYS[2], 0); if nextThreadId ~= false then redis.call('publish', KEYS[4] .. ':' .. nextThreadId, ARGV[1]); end;
return 1; 快速看懂redssion的几个技术点:
-
redis的evl命令执行lua脚本,以及简单的lua脚本阅读。
-
redis的suscribe订阅机制
-
jdk里的信号量Semaphore,以及juc里的CompletableFuture
使用zk实现分布式锁
zookeeper本身是雅虎开发的一个用于分布式锁解决方案的组件,开源后叫zookeeper。因为zk本身的一些特性,其实实现分布式锁就相对容易一些,比如zk本身的高可用高可靠,就不需要RedLock机制了等。同样已经有现成的zk客户端提供了分布式锁的现成实现。