Spark对正常日志文件清洗并分析

目录
日志文件准备:
一.日志数据清洗:
第一步:数据清洗需求分析:
二.代码实现
2.1 代码和其详解
2.2创建jdbcUtils来连接Mysql数据库
2.3 运行后结果展示:
三、留存用户分析
3.1需求概览
3.2.代码实现
3.3 运行后结果展示:
四、活跃用户分析
4.1需求概览
4.2代码实现
日志文件准备:
链接:https://pan.baidu.com/s/1dWjIGMttVJALhniJyS6R4A?pwd=h4ec
提取码:h4ec
--来自百度网盘超级会员V5的分享
一.日志数据清洗:
第一步:数据清洗需求分析:
1.读入日志文件并转化为Row类型
- 按照Tab切割数据
- 过滤掉字段数量少于8个的
2.对数据进行清洗
- 按照第一列和第二列对数据进行去重
- 过滤掉状态码非200
- 过滤掉event_time为空的数据
- 将url按照”&”以及”=”切割
3.保存数据
- 将数据写入mysql表中
- 将其分成多个字段

二.代码实现
2.1 代码和其详解
def main(args: Array[String]): Unit = {val conf: SparkConf = new SparkConf().setAppName("detlDemo").setMaster("local[*]")val spark: SparkSession = SparkSession.builder().config(conf).getOrCreate()val sc: SparkContext = spark.sparkContextimport spark.implicits._//TODO 加载日志文件数据,按照\\t分组,过滤出长度小于8的数据,将数据封装到 Row对象中,创建DF//创建Row对象val rowRdd: RDD[Row] = sc.textFile("in/test.log").map(x => x.split("\\t")).filter(x => x.length >= 8).map(x => Row(x(0), x(1), x(2), x(3), x(4), x(5), x(6), x(7)))//创建Schemaval schema: StructType = StructType(Array(StructField("event_time", StringType),StructField("url", StringType),StructField("method", StringType),StructField("status", StringType),StructField("sip", StringType),StructField("user_uip", StringType),StructField("action_prepend", StringType),StructField("action_client", StringType)))//创建DataFrameval logDF: DataFrame = spark.createDataFrame(rowRdd, schema)logDF.printSchema()logDF.show(3)//TODO 删除重复数据,过滤掉状态码非200val filterLogs: Dataset[Row] = logDF.dropDuplicates("event_time", "url").filter(x => x(3) == "200").filter(x => StringUtils.isNotEmpty(x(0).toString))//单独处理url,并转为Row对象val full_logs_rdd: RDD[Row] = filterLogs.map(line => {val str: String = line.getAs[String]("url")val paramsArray: Array[String] = str.split("\\\\?")var paramsMap: Map[String, String] = nullif (paramsArray.length == 2) {val tuples: Array[(String, String)] = paramsArray(1).split("&").map(x => x.split("=")).filter(x => x.length == 2).map(x => (x(0), x(1)))paramsMap = tuples.toMap}(line.getAs[String]("event_time"),paramsMap.getOrElse[String]("userUID", ""),paramsMap.getOrElse[String]("userSID", ""),paramsMap.getOrElse[String]("actionBegin", ""),paramsMap.getOrElse[String]("actionEnd", ""),paramsMap.getOrElse[String]("actionType", ""),paramsMap.getOrElse[String]("actionName", ""),paramsMap.getOrElse[String]("actionValue", ""),paramsMap.getOrElse[String]("actionTest", ""),paramsMap.getOrElse[String]("ifEquipment", ""),line.getAs[String]("method"),line.getAs[String]("status"),line.getAs[String]("sip"),line.getAs[String]("user_uip"),line.getAs[String]("action_prepend"),line.getAs[String]("action_client"))}).toDF().rdd// frame.withColumnRenamed("_1","event_time").printSchema()//再次创建Schemaval full_logs_schema: StructType = StructType(Array(StructField("event_time", StringType),StructField("userUID", StringType),StructField("userSID", StringType),StructField("actionBegin", StringType),StructField("actionEnd", StringType),StructField("actionType", StringType),StructField("actionName", StringType),StructField("actionValue", StringType),StructField("actionTest", StringType),StructField("ifEquipment", StringType),StructField("method", StringType),StructField("status", StringType),StructField("sip", StringType),StructField("user_uip", StringType),StructField("action_prepend", StringType),StructField("action_client", StringType),))//再次创建DataFrameval full_logDF: DataFrame = spark.createDataFrame(full_logs_rdd, full_logs_schema)full_logDF.printSchema()full_logDF.show(2, true)// filterLogs.write// jdbcUtils.dataFrameToMysql(filterLogs, jdbcUtils.table_access_logs, 1)jdbcUtils.dataFrameToMysql( full_logDF, jdbcUtils.table_full_access_logs, 1)spark.close()}2.2创建jdbcUtils来连接Mysql数据库
object jdbcUtils {val url = "jdbc:mysql://192.168.61.141:3306/jsondemo?createDatabaseIfNotExist=true"val driver = "com.mysql.cj.jdbc.Driver"val user = "root"val password = "root"val table_access_logs: String = "access_logs"val table_full_access_logs: String = "full_access_logs"val table_day_active:String="table_day_active"val table_retention:String="retention"val table_loading_json="loading_json"val table_ad_json="ad_json"val table_notification_json="notification_json"val table_active_background_json="active_background_json"val table_comment_json="comment_json"val table_praise_json="praise_json"val table_teacher_json="teacher_json"val properties = new Properties()properties.setProperty("user", jdbcUtils.user)properties.setProperty("password", jdbcUtils.password)properties.setProperty("driver", jdbcUtils.driver)def dataFrameToMysql(df: DataFrame, table: String, op: Int = 1): Unit = {if (op == 0) {df.write.mode(SaveMode.Append).jdbc(jdbcUtils.url, table, properties)} else {df.write.mode(SaveMode.Overwrite).jdbc(jdbcUtils.url, table, properties)}}def getDataFtameByTableName(spark:SparkSession,table:String):DataFrame={val frame: DataFrame = spark.read.jdbc(jdbcUtils.url, table, jdbcUtils.properties)frame}}
2.3 运行后结果展示:
初次清理后的日志数据

清理完url的数据

三、留存用户分析
3.1需求概览
1.计算用户的次日留存率
- 求当天新增用户总数n
- 求当天新增的用户ID与次日登录的用户ID的交集,得出新增用户次日登录总数m (次日留存数)
- m/n*100%
2.计算用户的次周留存率
3.2.代码实现
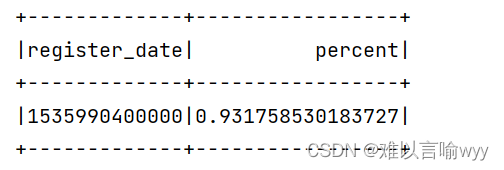
object Retention {def main(args: Array[String]): Unit = {val conf: SparkConf = new SparkConf().setAppName("retentionDemo").setMaster("local[*]")val spark: SparkSession = SparkSession.builder().config(conf).getOrCreate()val sc: SparkContext = spark.sparkContextimport spark.implicits._import org.apache.spark.sql.functions._val logs: DataFrame = jdbcUtils.getDataFtameByTableName(spark, jdbcUtils.table_full_access_logs)logs.printSchema()logs.show(3, false)// logs.createOrReplaceTempView("logs"):// 过滤出所有的事件为Registered的日志,并且修改事件时间(event_time)为注册时间(registered——time)// 找出注册用户id和注册时间val registered: DataFrame = logs.filter('actionName === "Registered").withColumnRenamed("event_time", "register_time").select("userUID", "register_time")registered.printSchema()registered.show(3, false)// 找出ActionName为Signin的日志数据val signin: DataFrame = logs.filter('actionName === "Signin").withColumnRenamed("event_time", "signin_time").select("userUID", "signin_time")signin.printSchema()signin.show(3, false)// 两个DF关联(几种写法和可能出现的问题)val joined: DataFrame = registered.join(signin, Seq("userUID"), "left")// registered.join(signin,$"userUID","left") 显示是模棱两可的得先使两表userUID相等// val joined2: DataFrame = registered.as("r1").join(signin.as("s1"), $"r1.userUID" === $"s1.userUID", "left")// joined2.printSchema()// joined2.show(3,false) //会显示相同的id,在后续的操作中会有两个userUID,再次使用很难使用// joined.printSchema()// joined.show(3, false)val dateFormat = new SimpleDateFormat("yyyy-MM-dd")val mydefDataformat: UserDefinedFunction = spark.udf.register("mydefDataformat", (event_time: String) => {if (StringUtils.isEmpty(event_time))0elsedateFormat.parse(event_time).getTime})val joinedFrame: DataFrame = joined.withColumn("register_date", mydefDataformat($"register_time")).withColumn("signin_date", mydefDataformat($"signin_time"))// .drop("")joinedFrame.printSchema()joinedFrame.show(3, false)// 求出前一天注册,当天登录的用户数量,过滤注册时间加上86400000查询第二天登录的用户,filter操作==需要变成===val signinNumDF: DataFrame = joinedFrame.filter('register_date + 86400000 === 'signin_date).groupBy($"register_date").agg(countDistinct('userUID).as("signNum"))signinNumDF.printSchema()signinNumDF.show(3, false)// 求出当前注册用户的数量val registerNumDF: DataFrame = joinedFrame.groupBy('register_date).agg(countDistinct("userUID").as("registerNum"))registerNumDF.printSchema()registerNumDF.show(3, false)// 求出留存率val joinRegisAndSigninDF: DataFrame = signinNumDF.join(registerNumDF, Seq("register_date"))joinRegisAndSigninDF.printSchema()joinRegisAndSigninDF.show(3, false)val resultRetention: DataFrame = joinRegisAndSigninDF.select('register_date, ('signNum / 'registerNum).as("percent"))resultRetention.show()jdbcUtils.dataFrameToMysql(resultRetention,jdbcUtils.table_retention,1)spark.close()}}3.3 运行后结果展示:
四、活跃用户分析
4.1需求概览
- 读取数据库,统计每天的活跃用户数
- 统计规则:有看课和买课行为的用户才属于活跃用户
- 对UID进行去重
4.2代码实现
object Active {def main(args: Array[String]): Unit = {val conf: SparkConf = new SparkConf().setAppName("activeDemo").setMaster("local[*]")val spark: SparkSession = SparkSession.builder().config(conf).getOrCreate()val sc: SparkContext = spark.sparkContextimport spark.implicits._import org.apache.spark.sql.functions._// 读取清洗后的日志数据并过滤出活跃用户val logs: DataFrame = jdbcUtils.getDataFtameByTableName(spark, jdbcUtils.table_full_access_logs)val ds: Dataset[Row] = logs.filter($"actionName" === "BuyCourse" || $"actionName" === "StartLearn")ds.printSchema()ds.show(3,false)
// 修改DataSet=>二元组val ds2: Dataset[(String, String)] = ds.map(x =>(x.getAs[String]("userSID"),x.getAs[String]("event_time").substring(0, 10)))ds2.show()// 按天进行聚合,求出活跃用户数并去重val frame: DataFrame = ds2.withColumnRenamed("_2", "date").withColumnRenamed("_1", "userid").groupBy($"date").agg(countDistinct("userid").as("activeNum"))frame.printSchema()frame.show(3,false)
// JdbcUtils中新增活跃用户变量jdbcUtils.dataFrameToMysql(frame,jdbcUtils.table_day_active,1)println("操作结束")spark.close()}}4.3 运行后结果展示:
