Oracle函数记录

一、各个函数介绍
1.OVER(PARTITION BY… ORDER BY…)--开窗函数
1.开窗函数用于为行定义一个窗口(这里的窗口是指运算将要操作的行的集合),它对一组 值进行操作,不需要使用GROUP BY子句对数据进行分组,能够在同一行中同时返回基础 行的列和聚合列。
2. 先把一组数据按照(PARTITION BY)指定的字段分割成各种组,然后组内按照某个字段 排序。(ORDER BY);
2.OVER()里头的分组以及排序的执行晚于 where 、group by、 早于order by 的执行;
常用组合:
- row_number() over(partition by ... order by ...) --分组排序- rank() over(partition by ... order by ...) --分组排序- dense_rank() over(partition by ... order by ...) --分组排序- count() over(partition by ... order by ...) --分组计数- max() over(partition by ... order by ...) --分组取最大值- min() over(partition by ... order by ...) --分组取最小值- sum() over(partition by ... order by ...) --分组求和- avg() over(partition by ... order by ...) --分组取平均值- first_value() over(partition by ... order by ...) --取分组第一条- last_value() over(partition by ... order by ...) --取分组最后一条- lag() over(partition by ... order by ...) --取出同一字段的前N行的数据- lead() over(partition by ... order by ...) --取出同一字段的前N行的数据
二、实际使用
row_number()over()
先说需求:树结构中只获取同一级目录的第一个数据信息,原因是分行与支行信息在同一级,这里我只需要分行的信息,不要支行的信息,具体情况如下图所示:
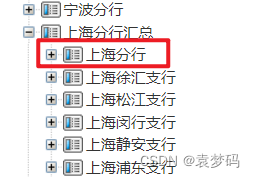
--目的:只获取同一级目录的第一个数据信息
SELECT JGBH,JGMC
FROM (--先根据父id进行分组,并将子id升序排序SELECT t.*, ROW_NUMBER() OVER (PARTITION BY SJJG ORDER BY JGBH) rnFROM GG_JGBH twhere SYBZ = 1 --这是我筛选的条件,可更改CONNECT BY PRIOR JGBH = SJJG --SJJG是父id,JGBH是子idSTART WITH SJJG IS NULL --从最高级的父id是空的开始
)
--再只获取每个分组的第一个数据
WHERE rn = 1;first_value()over()
first_value()over(partition by 列名1,列名2 order by 列名1,列名2)是求一组数据的第一个值
select distinct
a.date,
a.name,
first_value(date)over(partition by name order by date asc)as `每个人对应最早的date`
,
first_value(date)over(partition by name order by date desc)as `每个人对应最晚的date`
from
(
select '张三'as name,'2021-04-11' as date
union all
select '李四'as name,'2021-04-09' as date
union all
select '赵四'as name,'2021-04-16' as date
union all
select '张三'as name,'2021-03-10'as date
union all
select '李四'as name,'2020-01-01'as date
)a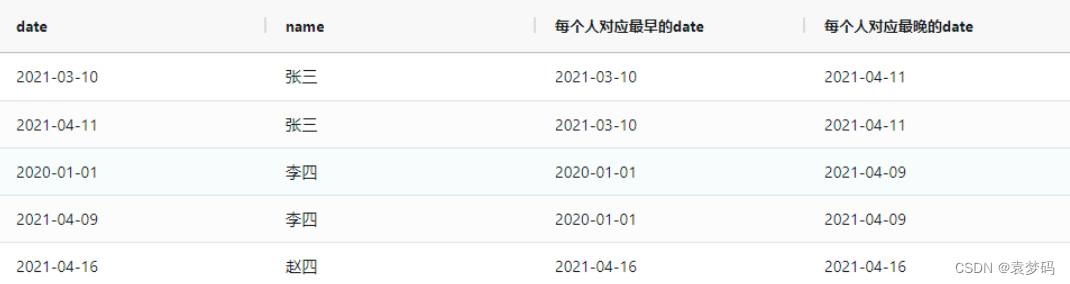
last_value()over()
last_value()over(partition by 列名1,列名2 order by 列名1,列名2)是求一组数据的最后一个值
last_value()默认是升序,如果限制了是降序,则等同于first_value()升序
select distinct a.date,a.name
,last_value(date)over(partition by name order by date asc)as `每个人对应最晚的date`
from
(
select '张三'as name,'2021-04-11' as date
union all
select '李四'as name,'2021-04-09' as date
union all
select '赵四'as name,'2021-04-16' as date
union all
select '张三'as name,'2021-03-10'as date
union all
select '李四'as name,'2020-01-01'as date
)a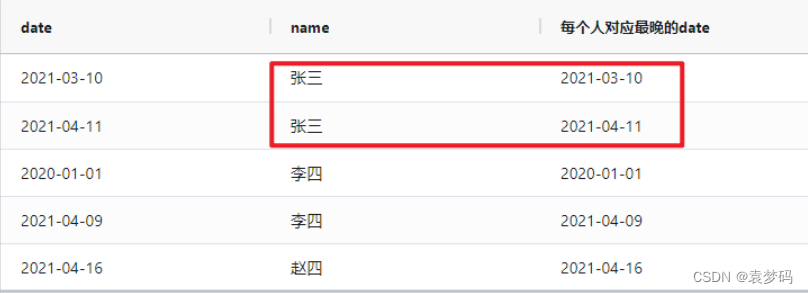
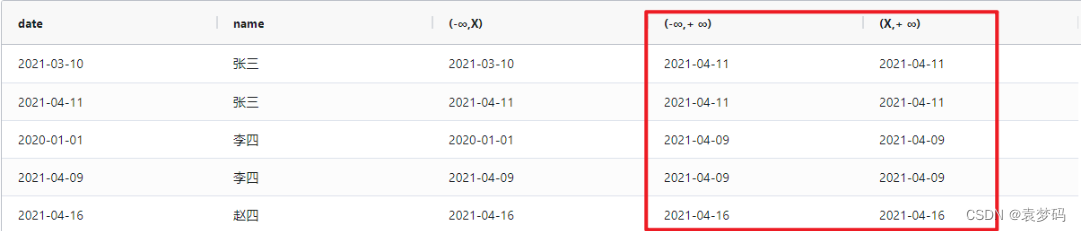
select distinct a.date,a.name
,last_value(date)over(partition by name order by date rows between unbounded preceding and current row)as `(-∞,X)`
,last_value(date)over(partition by name order by date rows between unbounded preceding and unbounded following)as `(-∞,+ ∞)`
,last_value(date)over(partition by name order by date rows between current row and unbounded following)as `(X,+ ∞)`
from
(
select '张三'as name,'2021-04-11' as date
union all
select '李四'as name,'2021-04-09' as date
union all
select '赵四'as name,'2021-04-16' as date
union all
select '张三'as name,'2021-03-10'as date
union all
select '李四'as name,'2020-01-01'as date
)a