推荐系统概述

1.推荐系统的意义
随着移动互联网的飞速发展,人们已经处于一个信息过载的时代。在这个时代中,信息的生产者很难将信息呈现在对它们感兴趣的信息消费者面前,而对于信息消费者也很难从海量的信息中找到自己感兴趣的信息。推荐系统就是一个将信息生产者和信息消费者连接起来的桥梁。 平台往往会作为推荐系统的载体,实现信息生产者和消费者之间信息的匹配。上述提到的平台方、信息生产者和消费者可以分别用平台方(如:腾讯视频、淘宝、网易云音乐等)、物品(如:视频、商品、音乐等)和用户和来指代。下面分别从这三方需求(平台方、信息生产者和信息消费者)出发,介绍推荐系统的存在的意义。
1.1 平台方
平台方一般是为信息生产者提供物品展示的位置,然后通过不同的方式吸引用户来到平台上寻找他们感兴趣的物品。平台通过商家对物品的展示以及用户的浏览、观看或下单等行为,就产生了所谓的"流量"。
对平台方而言,流量的高效利用是推荐系统存在的重要原因。 以典型的电商网站一般具有如图所示的树状拓扑结构,树状结构在连通性方面有着天然的劣势,阻碍这流量的高效流通。推荐系统的出现使得原本的树状结构变成网络拓扑结构,大大增强了整个网络的连通性。 推荐模块不仅使用户在当前页面有了更好的选择路径,同时也给了每个商品增加入口和展示机会,进而提高了成交概率。而推荐质量的好坏,直接决定了用户选择这条路径的可能性,进而影响着流量的利用效率。

推荐系统解决产品能够最大限度地吸引用户、留存用户、增加用户粘性、提高用户转化率的问题,从而达到平台商业目标增长的目的。 不同平台的目标取决于其商业的盈利目的,例如对于YouTube,其商业目标是最大化视频被点击(点击率)以及用户观看的时长(完播率),同时也会最大化内置广告的点击率;对于淘宝等电商平台,除了最大化商品的点击率外,最关键的目标则是最大化用户的转化率,即由点击到完成商品购买的指标。
1.2 信息生产者(物品)
在互联网大数据时代下,物品的长尾性和二八原则是非常严重的。具体而言,对于一个平台而言80%的销售额可能是那些最畅销20%的物品。但是那20%的物品其实仅仅能满足一小部分人的需求,对于绝大多数的用户而言,是要从那80%的长尾物品中去满足他们的需求。虽然长尾物品的总销售额占比不大,但是因为长尾物品的数量庞大,如果可以充分挖掘长尾物品,那这些长尾物品的销售额的总量有可能会超过热门商品。
物品只是信息生产者的产物,对于信息生产者而言,例如商家、视频创作者等,他们更希望自己生产的内容可以得到更多的曝光,尤其是对于新的商家或者视频创作者,这样可以激发他们创作的热情,进而产出出更多的商品或者视频,让更多的用户的需求得到满足。
对于一个平台而言,无论是否靠平台上的物品直接盈利,其将平台上的内容与用户进行匹配的能力都是衡量平台好坏的重要标准之一,推荐系统的好坏很大程度上决定了平台匹配需求和供给的能力。推荐系统匹配需求和供给的能力决定了其最终的商业价值。
1.3 信息消费者(用户)
推荐系统对于用户而言,除了将平台上的需求和供给进行匹配外,还需要尽可能地提高用户的体验,但是对于一个平台来说,影响用户体验的因素非常多(产品设计、广告数量等)。对于一个有明确需求的用户而言,用户在平台上可以直接通过搜索来快速满足自己的需求,但这也仅仅是一个平台最基础的用户体验(平台做的好是应该的,但是做的不好可能会被喷)。对于一个没有明确需求的用户而言,用户会通过浏览平台上的推荐页来获取一些额外的惊喜需求。因为用户没有明确的需求,也就对推荐页浏览的内容没有明确的预期,但是并不说明用户没有期待。我们每天都希望自己的一天中充满惊喜,这样生活才会感觉更加的多姿多彩。推荐系统可以像为用户准备生日礼物一样,让呈现的内容给用户带来惊喜,进而增强用户对平台的依赖。 此外,在给用户带来惊喜的同时,也会提高平台的转化率。
1.4 推荐和搜索的区别
搜索和推荐都是解决互联网大数据时代信息过载的手段,但是它们也存在着许多的不同:
- 用户意图:对于搜索而言,用户意图是非常明确的,用户通过查询的关键词主动发起搜索请求。对于推荐而言,用户的需求是不明确的,推荐系统在通过对用户历史兴趣的分析给用户推荐他们可能感兴趣的内容。
- 个性化程度:对于搜索而言,由于限定的了搜索词,所以展示的内容对于用户来说是有标准答案的,所以搜索的个性化程度较低。而对于推荐来说,推荐的内容本身就是没有标准答案的,每个人都有不同的兴趣,所以每个人展示的内容,个性化程度比较高。
- 优化目标:对于搜索系统而言,更希望可以快速地、准确地定位到标准答案,故搜索结果中答案越靠前越好,通常评价指标有:归一化折损累计收益(NDCG)、精确率(Precision)和召回率(Recall)。对于推荐系统而言,因为没有标准的答案,所以优化目标可能会更宽泛。例如用户停留时长、点击、多样性,评分等。不同的优化目标又可以拆解成具体的不同的评价指标。
- 马太效应和长尾理论:对于搜索系统来说,用户的点击基本都集中在排列靠前的内容上,对于排列靠后的很少会被关注,这就是马太效应。而对于推荐系统来说,热门物品被用户关注更多,冷门物品不怎么被关注的现象也是存在的,所以也存在马太效应。此外,在推荐系统中,冷门物品的数量远远高于热门物品的数量,所以物品的长尾性非常明显。
对于搜索、推荐、广告这三个领域的区别和联系可以参考王喆老师写的排得更好VS估得更准VS搜的更全「推荐、广告、搜索」算法间到底有什么区别?
1.5 推荐系统的应用
个性化推荐系统通过分析用户的行为日志,得到用户当前的甚至未来可能的兴趣,给不同的用户展示不同的(个性化)的页面,来提高网站或者app的点击率、转化率、留存率等指标。 推荐系统被广泛应用在广告、电商、影视、音乐、社交、饮食、阅读等地方。下面简单地通过不同的app的推荐页来感受一哈推荐系统在各个内容平台的存在形式。
-
电商首页推荐(淘宝、京东、拼多多)

-
视频推荐(抖音、快手、B站、爱奇艺)
-
饮食推荐(美团、饿了么、叮咚买菜)
- 音乐电台(网易云音乐、QQ音乐、喜马拉雅)
- 资讯、阅读(今日头条、知乎、豆瓣)

2.推荐系统的架构
推荐和搜索系统核心的的任务是从海量物品中找到用户感兴趣的物品。在这个背景下,推荐系统包含非常多的模块,每个模块将会有很多专业研究的工程和研究工程师,作为刚入门的同学而言很难对每个模块都有很深的理解,实际上也大可不必,我们完全可以从学习好一个模块技术后,以点带面学习整个系统,虽然正式工作中,每个人将只会负责的也是整个系统的一部分。但是掌握推荐系统最重要的还是梳理清楚整个推荐系统的架构,知道每一个部分需要完成哪些任务,是如何做的,主要的技术栈是什么,有哪些局限和可以研究的问题,能够对我们学习推荐系统有一个提纲挈领的作用。
本文将从系统架构和算法架构两个角度出发解析推荐系统通用架构。系统架构设计思想是大数据背景下如何有效利用海量和实时数据,将推荐系统按照对数据利用情况和系统响应要求出发,将整个架构分为离线层、近线层、在线层三个模块。进而分析这三个模块分别承担推荐系统什么任务,有什么制约要求。这和通俗我们理解算法架构(召回、排序)不同,因为更多的是考虑推荐算法在工程技术实现上的问题,系统架构是如何权衡利弊,如何利用各种技术工具帮助我们达到想要的目的的,方便理解推荐系统这样设计的原因。
架构设计是一个非常大的话题,设计的核心在于平衡和妥协。在推荐系统不同时期、不同的环境、不同的数据,架构都会面临不一样的问题。 Netfliex 官方博客有一段总结:
We want the ability to use sophisticated machine learning algorithms that can grow to arbitrary complexity and can deal with huge amounts of data. We also want an architecture that allows for flexible and agile innovation where new approaches can be developed and plugged-in easily. Plus, we want our recommendation results to be fresh and respond quickly to new data and user actions. Finding the sweet spot between these desires is not trivial: it requires a thoughtful analysis of requirements, careful selection of technologies, and a strategic decomposition of recommendation algorithms to achieve the best outcomes for our members.
“我们需要具备使用复杂机器学习算法的能力,这些算法要可以适应高度复杂性,可以处理大量数据。我们还要能够提供灵活、敏捷创新的架构,新的方法可以很容易在其基础上开发和插入。而且,我们需要我们的推荐结果足够新,能快速响应新的数据和用户行为。找到这些要求之间恰当的平衡并不容易,需要深思熟虑的需求分析,细心的技术选择,战略性的推荐算法分解,最终才能为客户达成最佳的结果。”
在思考推荐系统架构时的第一个问题是确定边界:知道推荐系统要负责哪部分问题,这就是边界内的部分。在这个基础上,架构要分为哪几个部分,每一部分需要完成的子功能是什么,每一部分依赖外界的什么。了解推荐系统架构也和上文讲到的思路一样,我们需要知道的是推荐系统要负责的是怎么问题,每一个子模块分别承担了哪些功能,它们的主流技术栈是什么。
2.1 系统架构以及设计思想
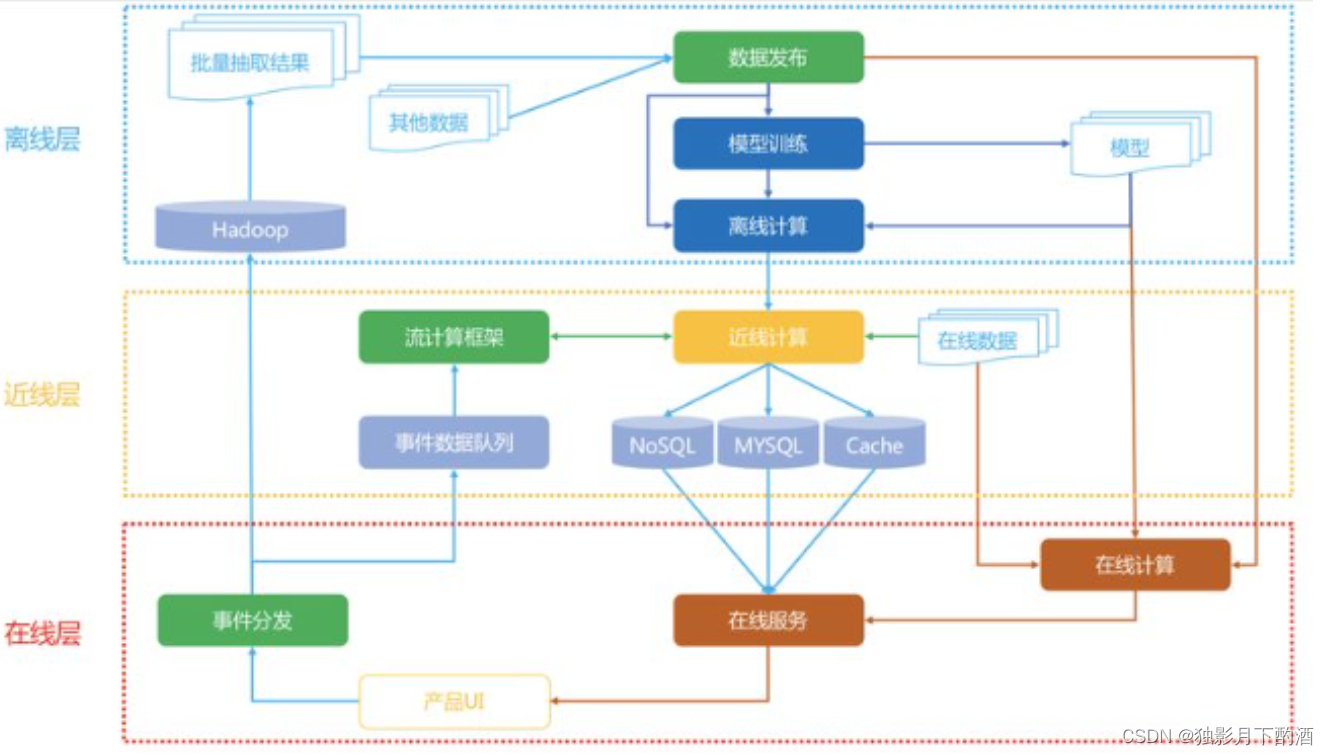
推荐系统架构,首先从数据驱动角度,对于数据,最简单的方法是存下来,留作后续离线处理,离线层就是用来管理离线作业的部分架构。在线层能更快地响应最近的事件和用户交互,但必须实时完成。这会限制使用算法的复杂性和处理的数据量。离线计算对于数据数量和算法复杂度限制更少,因为它可以批量方式完成,没有很强的时间要求。不过,由于没有及时加入最新的数据,所以很容易过时。
个性化架构的关键问题,就是如何以无缝方式结合、管理在线和离线计算过程。近线层介于两种方法之间,可以执行类似于在线计算的方法,但又不必以实时方式完成。这种设计思想最经典的就是Netflix在2013年提出的架构,整个架构分为
- 离线层:不用实时数据,不提供实时响应;
- 近线层:使用实时数据,不保证实时响应;
- 在线层:使用实时数据,保证实时在线服务;
Netflix的架构为什么这样设计呢?
本质上是因为推荐系统是由大量数据驱动的,大数据框架最经典的就是lambda架构和kappa架构。推荐系统在不同环节所使用的数据、处理数据的量级、需要的读取速度都是不同的,目前的技术还是很难实现一套端到端的及时响应系统,所以这种架构的设计本质上还是一种权衡后的产物,所以有下图这种模型:
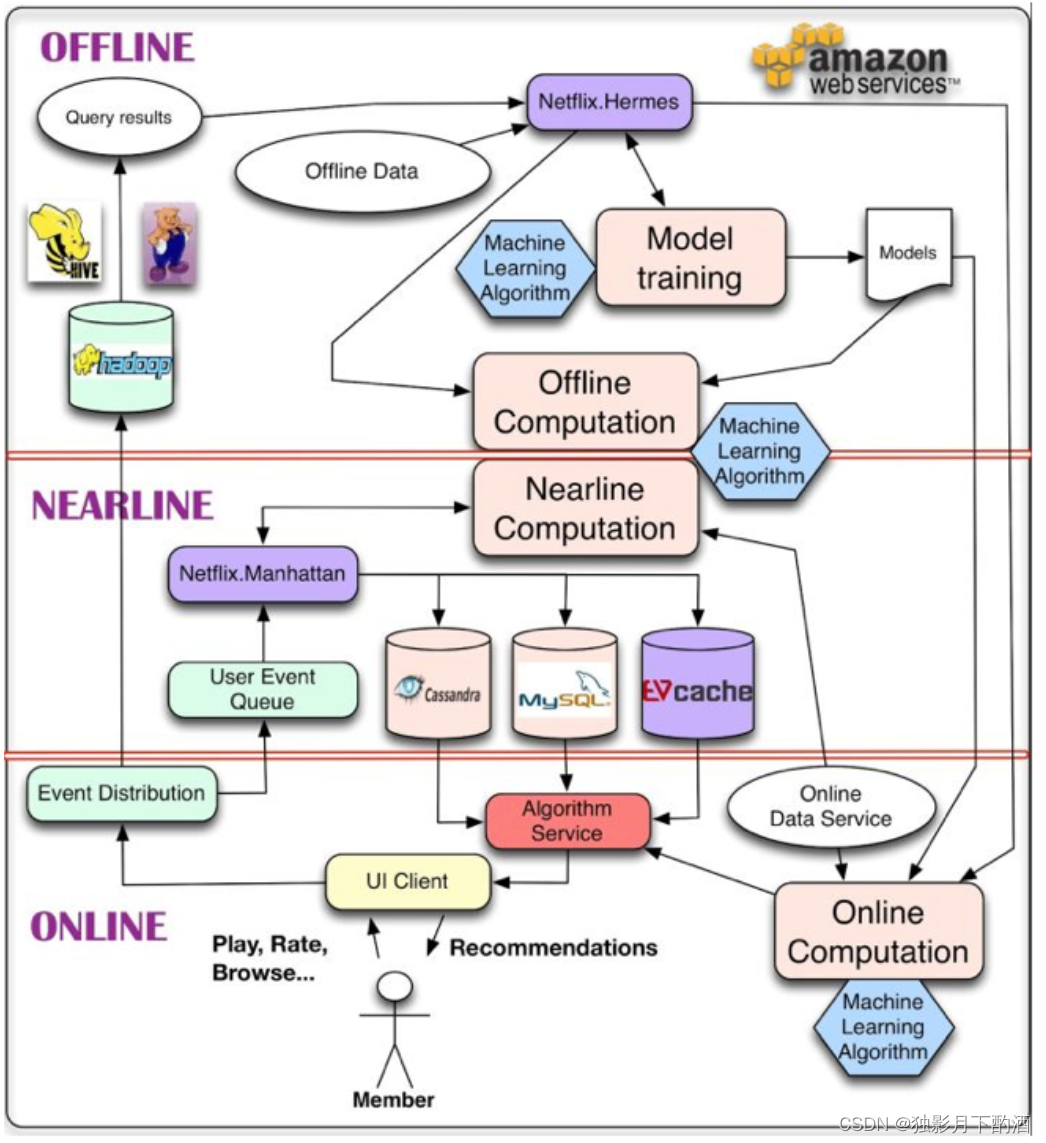
抽象出来的结构如下图:
整个数据部分其实是一整个链路,主要是三块,分别是客户端及服务器实时数据处理、流处理平台准实时数据处理和大数据平台离线数据处理这三个部分。
为什么数据处理需要这么多步骤?这些步骤都是干嘛的,存在的意义是什么?
首先是客户端和服务端的实时数据处理。 该步骤的工作就是记录。将用户在平台上真实的行为记录下来,比如用户看到了哪些内容,和哪些内容发生了交互,和哪些没有发生了交互。如果再精细一点,还会记录用户停留的时间,用户使用的设备等等。除此之外还会记录行为发生的时间,行为发生的session等其他上下文信息。 该步骤主要是后端和客户端完成,行业术语叫做埋点。所谓的埋点其实就是记录点,因为数据这种东西需要工程师去主动记录,不记录就没有数据,记录了才有数据。既然我们要做推荐系统,要分析用户行为,还要训练模型,显然需要数据。需要数据,就需要记录。
然后是流处理平台准实时数据处理,这一步其实也是记录数据,不过是记录一些准实时的数据。准实时是什么意思呢?准实时的意思也是实时,只不过没有那么即时,比如可能存在几分钟的误差。这样存在误差的即时数据,行业术语叫做准实时。那什么样的准实时数据需要记录呢?在推荐领域基本上只有一个类别,就是用户行为数据。也就是用户在观看这个内容之前还看过哪些内容,和哪些内容发生过交互。理想情况这部分数据也需要做成实时,但由于这部分数据量比较大,并且逻辑也相对复杂,所以很难做到非常实时,一般都是通过消息队列加在线缓存的方式做成准实时。
最后是离线数据处理,离线也就是线下处理,基本上就没有时限的要求了。 一般来说,离线处理才是数据处理的大头。所有“脏活累活”复杂的操作都是在离线完成的,比如一些join操作。后端只是记录了用户交互的商品id,我们需要商品的详细信息怎么办?需要去和商品表关联查表。显然数据关联是一个非常耗时的操作,所以只能放到离线来做。
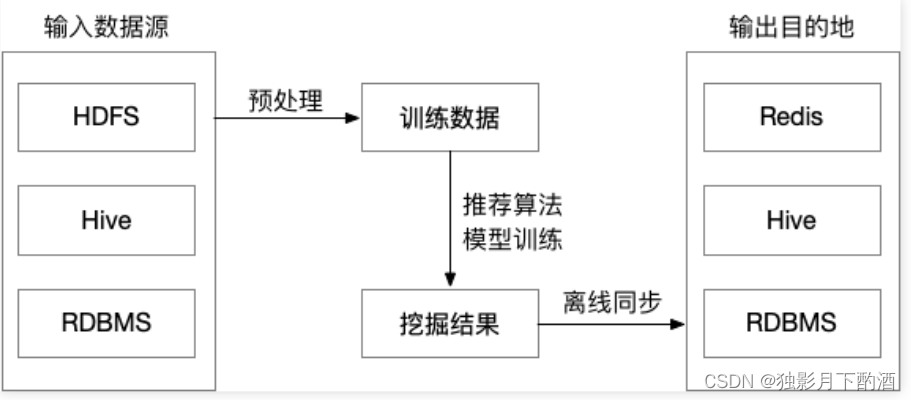
2.1.1 离线层(offline)
离线层是计算量最大的一个部分,它的特点是不依赖实时数据,也不需要实时提供服务。需要实现的主要功能模块是:
- 数据处理、数据存储;
- 特征工程、离线特征计算;
- 离线模型的训练;
离线任务一般会按照天或者更久运行,比如每天晚上定期更新这一天的数据,然后重新训练模型,第二天上线新模型。
离线层的优缺点
离线层数据量级是最大的,面临主要的问题是海量数据存储、大规模特征工程、多机分布式机器学习模型训练。目前主流的做法是收集到我们所有的业务数据,存储在HDFS上, 通过HIVE等工具,从全量数据中抽取出需要的数据,进行相应的ETL,离线阶段主流使用的分布式框架一般是Spark。
优点:
- 可以处理大量的数据,进行大规模特征工程;
- 可以进行批量处理和计算;
- 不用有响应时间要求;
缺点:
- 无法反应用户的实时兴趣变化,这就促使了近线层的产生。
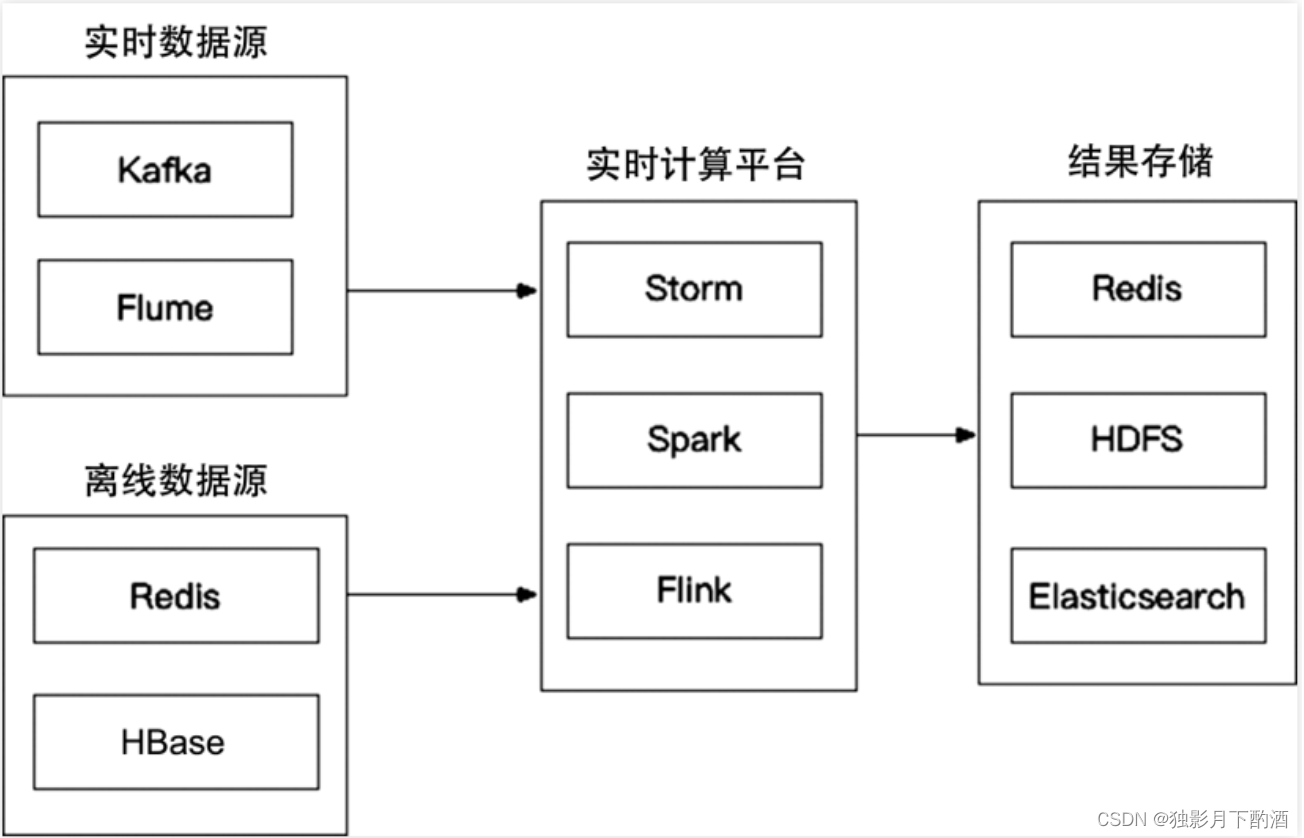
2.1.2 近线层(nearline)
近线层的主要特点是准实时,它可以获得实时数据,然后快速计算提供服务,但并不要求它和在线层一样达到几十毫秒这种延时要求。近线层的产生是同时想要弥补离线层和在线层的不足,折中的产物。
适合处理一些对延时比较敏感的任务,比如:
-
特征的实时更新计算:例如统计用户对不同分类文章的点击率,推荐系统一个老生常谈的问题就是特征分布不一致怎么办,如果使用离线已算好的特征就容易出现这个问题。近线层能够获取实时数据,按照用户的实时兴趣计算就能避免这个问题。
-
实时训练数据的获取:比如在使用DIN、DSIN这行网络会依赖于用户的实时兴趣变化,用户几分钟前的点击就可以通过近线层获取特征输入模型。
-
模型实时训练:可以通过在线学习的方法更新模型,实时推送到线上;
2.1.3 在线层(online)
在线层,即直接面向用户的那一层。最大的特点是对响应延时有要求;因为它是直接面对用户群体,想象你打开抖音淘宝等界面,几乎都是秒刷出来给你的推荐结果,不会说还需要让你等待几秒。所有的用户请求都会发送到在线层,在线层需要快速返回结果。它主要承担的工作有:
- 模型在线服务;包括了快速召回和排序;
- 在线特征快速处理拼接:根据传入的用户ID和场景,快速读取特征和处理拼接;
- AB实验或者分流:根据不同用户群体采用不同的模型,比如冷启动用户和正常服务模型;
- 运筹优化和业务干预:比如要对特殊商家流量扶持、对某些内容限流;
典型的在线服务是用过RESTful/RPC等提供服务,一般是公司后台服务部门调用在线层的服务,返回给前端。具体部署应用比较多的方式就是使用Docker在K8S部署。而在线服务的数据源就是在离线层计算好的每个用户和商品特征(事先存放在数据库中),在线层只需要实时拼接,不进行复杂的特征运算,然后输入近线层或者离线层已经训练好的模型,根据推理结果进行排序,最后返回给后台服务器,后台服务器根据我们对每一个用户的打分,结合业务以及不同策略再将推荐结果再返回给用户。
在线层最大的问题就是对实时性要求特别高,一般来说是几十毫秒,这就限制了我们能做的工作,很多任务往往无法及时完成,需要近线层协助。
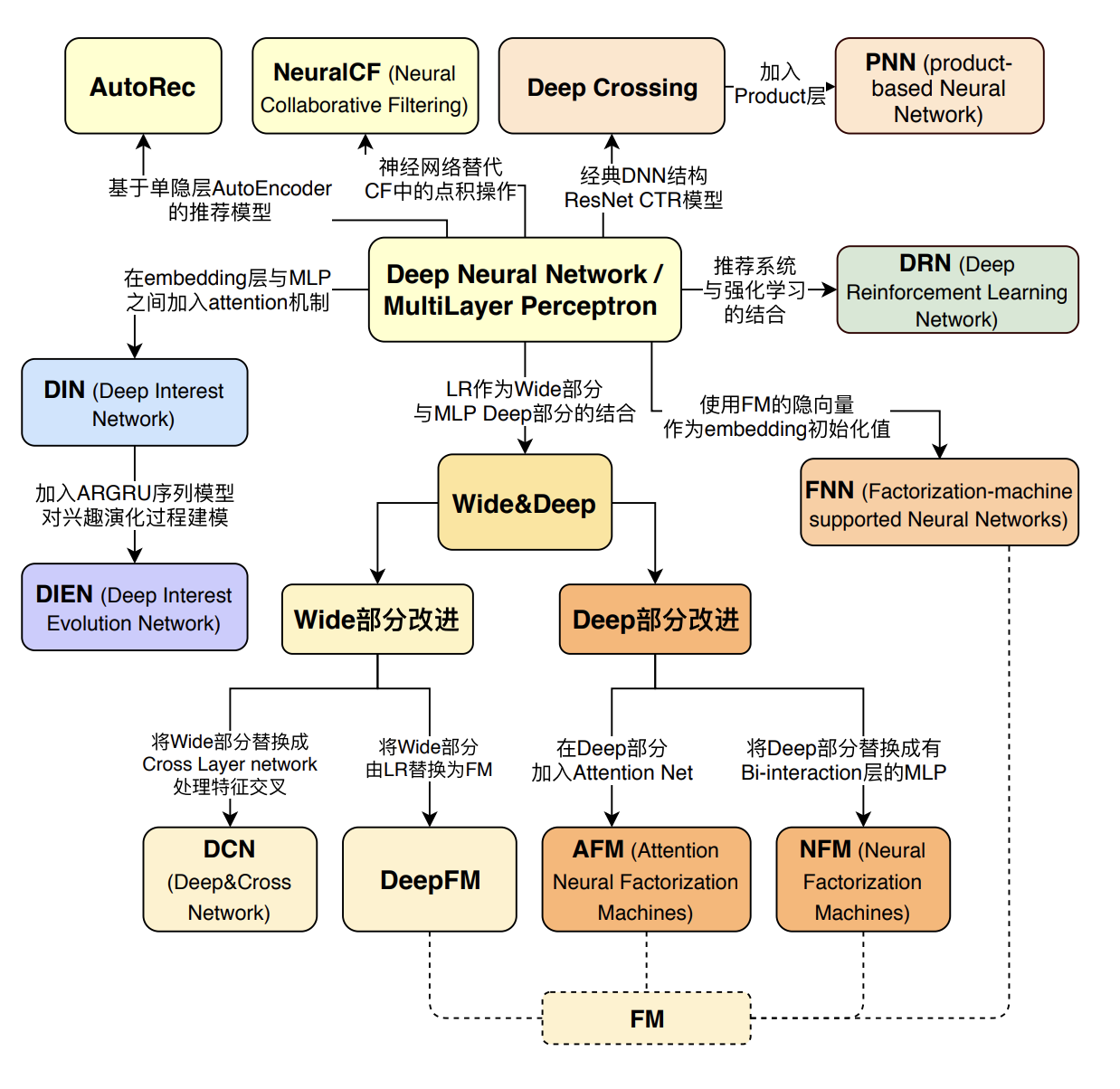
2.2 算法架构
在入门学习推荐系统的时候,更加关注的是哪个模型AUC更高、topK效果好,哪个模型更加牛逼的问题,从基本的协同过滤到点击率预估算法,从深度学习到强化学习,学术界都始终走在最前列。一个推荐算法从出现到在业界得到广泛应用是一个长期的过程,因为在实际的生产系统中,首先需要保证的是稳定、实时地向用户提供推荐服务,在这个前提下才能追求推荐系统的效果。
算法架构的设计思想就是在实际的工业场景中,不管是用户维度、物品维度还是用户和物品的交互维度,数据都是极其丰富的,学术界对算法的使用方法不能照搬到工业界。当一个用户访问推荐模块时,系统不可能针对该用户对所有的物品进行排序,那么推荐系统是怎么解决的呢?对应的商品众多,如何决定将哪些商品展示给用户?对于排序好的商品,如何合理地展示给用户?
工业推荐系统,如果粗分的话,有两个阶段。首先是召回,主要根据用户部分特征,从海量的物品库里,快速找回一小部分用户潜在感兴趣的物品,然后交给排序环节,排序环节可以融入较多特征,使用复杂模型,来精准地做个性化推荐。召回强调快,排序强调准。当然,这是传统角度看推荐这个事情。
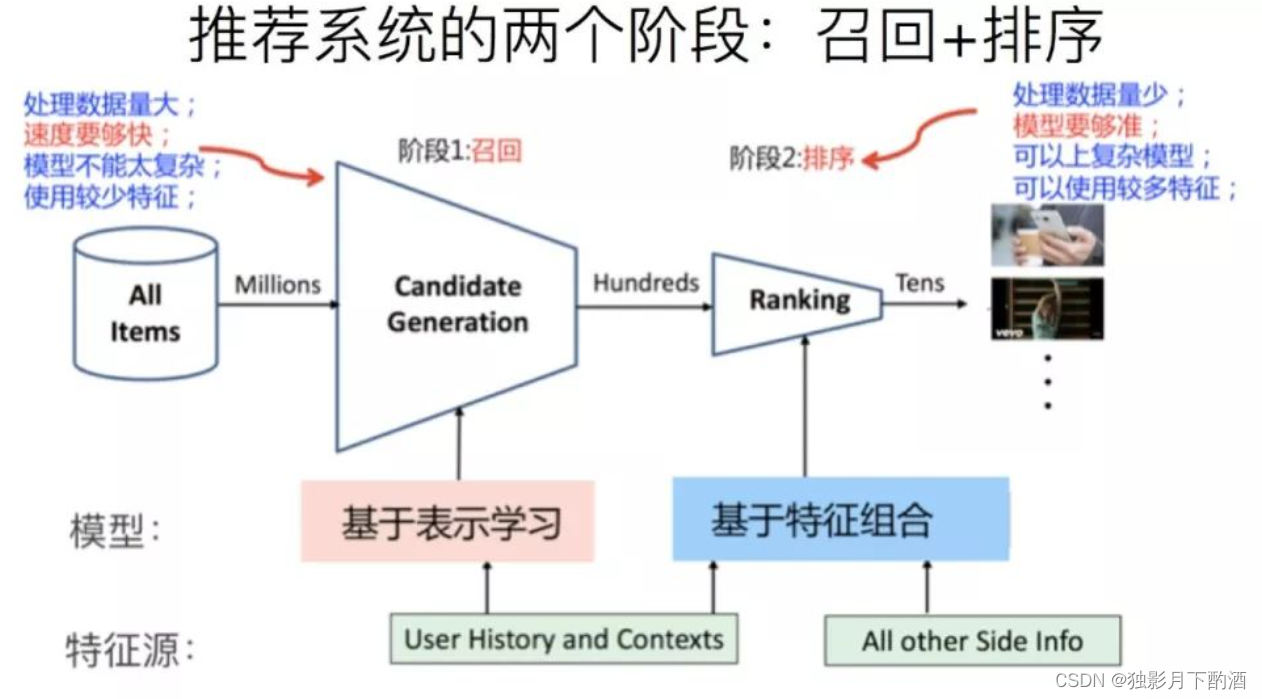
但是,如果我们更细致地看实用的推荐系统,一般会有四个环节,如下图所示:
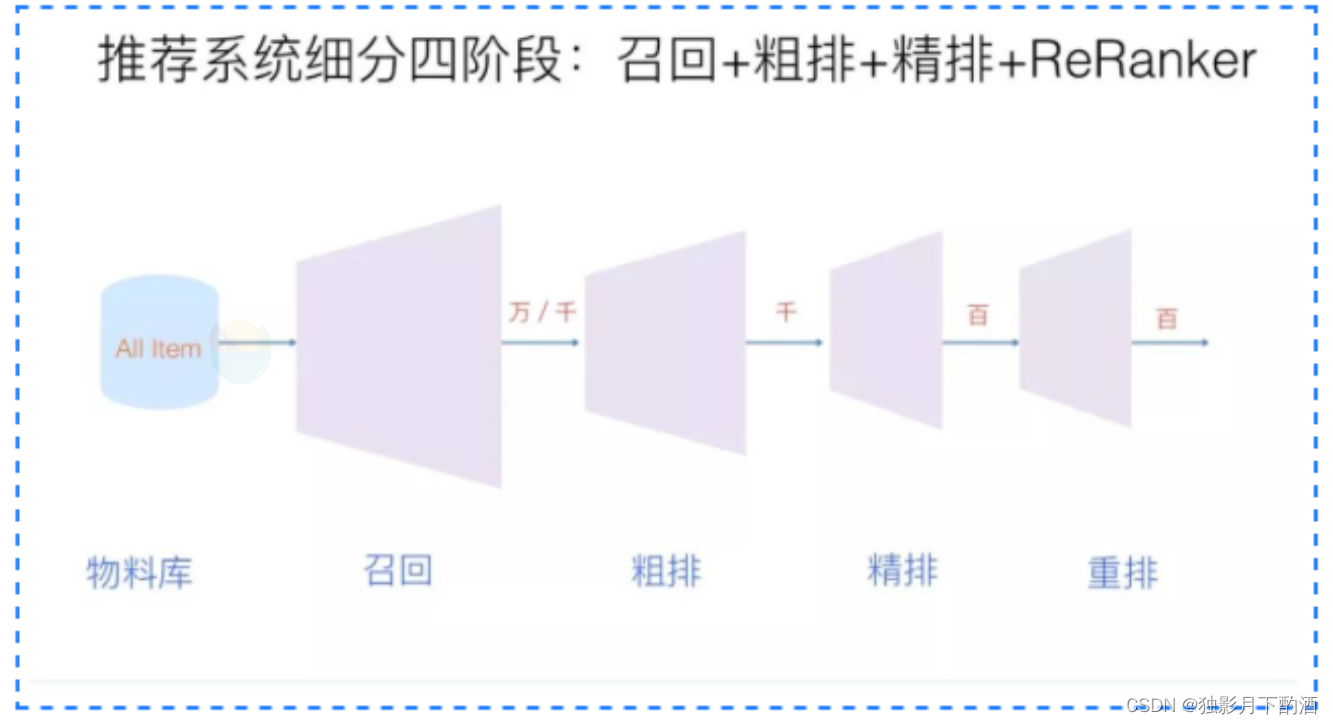
2.2.1 召回
召回层的主要目标是从推荐候选池中选取几千上万的item,送给后面的排序模块。由于召回面对的候选集十分大,且一般需要在线输出,故召回模块必须轻量快速低延迟。由于还有排序模块作为保障,召回不需要十分准确,但不可遗漏。
目前基本上采用多路召回解决范式,分为非个性化召回和个性化召回。个性化召回又有content-based、behavior-based、feature-based等多种方式。
召回主要考虑的内容有:
- 考虑用户层面:用户兴趣的多元化,用户需求与场景的多元化:例如:新闻需求,重大要闻,相关内容沉浸阅读等等
- 考虑系统层面:增强系统的鲁棒性;部分召回失效,其余召回队列兜底不会导致整个召回层失效;排序层失效,召回队列兜底不会导致整个推荐系统失效
- 系统多样性内容分发:图文、视频、小视频;精准、试探、时效一定比例;召回目标的多元化,例如:相关性,沉浸时长,时效性,特色内容等等
- 可解释性推荐一部分召回是有明确推荐理由的:很好的解决产品性数据的引入;
2.2.2 粗排
粗排的原因是有时候召回的结果还是太多,精排层速度还是跟不上,所以加入粗排。粗排可以理解为精排前的一轮过滤机制,减轻精排模块的压力。粗排介于召回和精排之间,要同时兼顾精准性和低延迟。目前粗排一般也都模型化了,其训练样本类似于精排,选取曝光点击为正样本,曝光未点击为负样本。但由于粗排一般面向上万的候选集,而精排只有几百上千,其解空间大很多。
粗排阶段的架构设计主要是考虑三个方面,一个是根据精排模型中的重要特征,来做候选集的截断,另一部分是有一些召回设计,比如热度或者语义相关的这些结果,仅考虑了item侧的特征,可以用粗排模型来排序跟当前User之间的相关性,据此来做截断,这样是比单独的按照item侧的倒排分数截断得到更加个性化的结果,最后是算法的选型要在在线服务的性能上有保证,因为这个阶段在pipeline中完成从召回到精排的截断工作,在延迟允许的范围内能处理更多的召回候选集理论上与精排效果正相关。
2.2.3 精排
精排层,也是我们学习推荐系统入门最常常接触的层,我们所熟悉的算法很大一部分都来自精排层。这一层的任务是获取粗排模块的结果,对候选集进行打分和排序。精排需要在最大时延允许的情况下,保证打分的精准性,是整个系统中至关重要的一个模块,也是最复杂,研究最多的一个模块。
精排是推荐系统各层级中最纯粹的一层,目标比较单一且集中,一门心思的实现目标的调优即可。最开始精排模型的常见目标是ctr,后续逐渐发展了cvr等多类目标。精排和粗排层的基本目标是一致的,都是对商品集合进行排序,但是和粗排不同的是,精排只需要对少量的商品(即粗排输出的商品集合的topN)进行排序即可。因此,精排中可以使用比粗排更多的特征,更复杂的模型和更精细的策略(用户的特征和行为在该层的大量使用和参与也是基于这个原因)。
精排层模型是推荐系统中涵盖的研究方向最多,有非常多的子领域值得研究探索,这也是推荐系统中技术含量最高的部分,毕竟它是直接面对用户,产生的结果对用户影响最大的一层。目前精排层深度学习已经一统天下了,精排阶段采用的方案相对通用,首先一天的样本量是几十亿的级别,我们要解决的是样本规模的问题,尽量多的喂给模型去记忆,另一个方面时效性上,用户的反馈产生时,怎么尽快的把新的反馈给到模型去学习到最新的知识。
2.2.4 重排
常见的有三种优化目标:Point Wise、Pair Wise 和 List Wise。重排序阶段对精排生成的Top-N个物品的序列进行重新排序,生成一个Top-K个物品的序列,作为排序系统最后的结果,直接展现给用户。 重排序的原因是因为多个物品之间往往是相互影响的,而精排序是根据Point Wise得分,容易造成推荐结果同质化严重,有很多冗余信息。而重排序面对的挑战就是海量状态空间如何求解的问题,一般在精排层我们使用AUC作为指标,但是在重排序更多关注NDCG等指标。
重排序在业务中,获取精排的排序结果,还会根据一些策略、运营规则参与排序,比如强制去重、间隔排序、流量扶持等、运营策略、多样性、context上下文等,重新进行一个微调。重排序更多的是List Wise作为优化目标的,它关注的是列表中商品顺序的问题来优化模型,但是一般List Wise因为状态空间大,存在训练速度慢的问题。
由于精排模型一般比较复杂,基于系统时延考虑,一般采用Point Wise方式,并行对每个item进行打分。这就使得打分时缺少了上下文感知能力。用户最终是否会点击购买一个商品,除了和它自身有关外,和它周围其他的item也息息相关。重排一般比较轻量,可以加入上下文感知能力,提升推荐整体算法效率。比如三八节对美妆类目商品提权,类目打散、同图打散、同卖家打散等保证用户体验措施。重排中规则比较多,但目前也有不少基于模型来提升重排效果的方案。
pairwise、pointwise 、 listwise算法是什么?怎么理解?主要区别是什么?https://blog.csdn.net/pearl8899/article/details/102920628
2.2.5 混排
多个业务线都想在Feeds流中获取曝光,则需要对它们的结果进行混排。比如推荐流中插入广告、视频流中插入图文和banner等。可以基于规则策略(如广告定坑)和强化学习来实现。
3.总结
- 推荐系统的背景:信息过载或者用户难以找到感兴趣的物品。
- 推荐与搜索的区别:用户意图、个性化程度、优化目标以及马太效应和长尾理论。
- Netfliex的经典推荐系统架构,整个架构更多是偏向实时性能和效果之间tradeoff的结果。
- 推荐系统三层设计:离线层(管理离线作业)、近线层(执行类似于在线计算的方法,但又不必以实时方式完成)、在线层(快速地响应最近的事件和用户交互,必须实时完成)。
- 推荐系统四个环节:召回(万/千)、粗排(千)、精排(百)、重排(百)
本文仅作为个人学习记录使用, 不用于商业用途, 谢谢您的理解合作。
参考链接:https://datawhalechina.github.io/fun-rec/#/