Flink系列-6、Flink DataSet的Transformation

版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
大数据系列文章目录
官方网址:https://flink.apache.org/
学习资料:https://flink-learning.org.cn/

目录
- Flink 算子
- Map
- FlatMap
- Filter
- Reduce
- reduceGroup
- Aggregate
-
- Aggregate的简写形式
- minBy和maxBy
- Aggregate 和 minBy maxBy的区别
- distinct去重
- Join
- Union
- Rebalance
- 分区
-
- partitionByHash
- sortPartition
Flink 算子
dataSet包括一系列的Transformation操作:
https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/batch/dataset_transformations.html
Map
将DataSet中的每一个元素转换为另外一个元素
示例
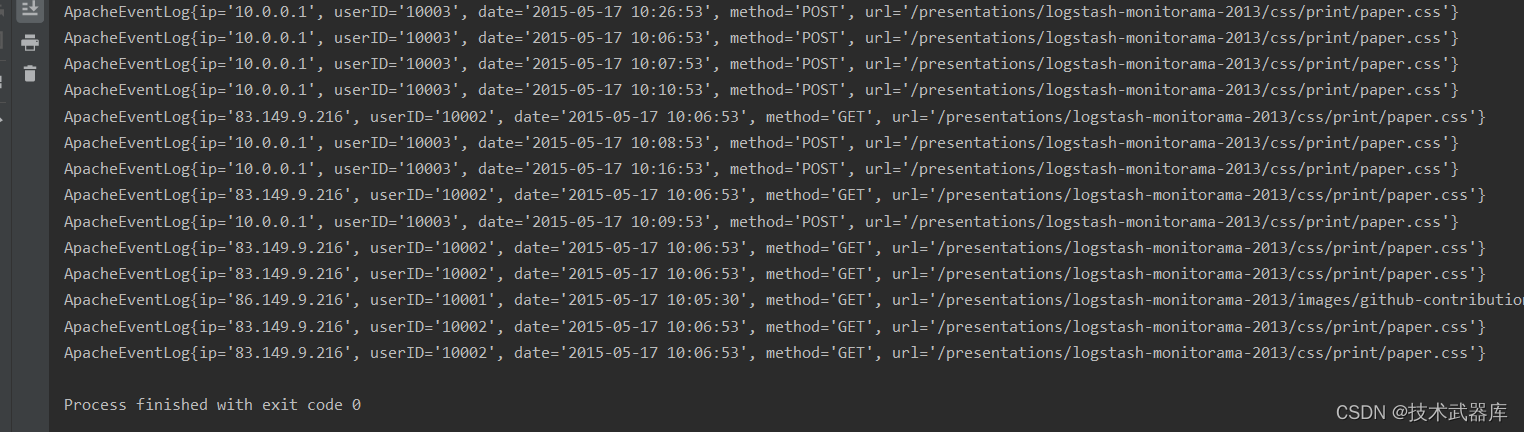
使用map操作,读取apache.log文件中的字符串数据转换成ApacheLogEvent对象
如:
86.149.9.216 10001 17/05/2015:10:05:30 GET /presentations/logstash-monitorama-2013/images/github-contributions.png
83.149.9.216 10002 17/05/2015:10:06:53 GET /presentations/logstash-monitorama-2013/css/print/paper.css
83.149.9.216 10002 17/05/2015:10:06:53 GET /presentations/logstash-monitorama-2013/css/print/paper.css
83.149.9.216 10002 17/05/2015:10:06:53 GET /presentations/logstash-monitorama-2013/css/print/paper.css
83.149.9.216 10002 17/05/2015:10:06:53 GET /presentations/logstash-monitorama-2013/css/print/paper.css
83.149.9.216 10002 17/05/2015:10:06:53 GET /presentations/logstash-monitorama-2013/css/print/paper.css
83.149.9.216 10002 17/05/2015:10:06:53 GET /presentations/logstash-monitorama-2013/css/print/paper.css
10.0.0.1 10003 17/05/2015:10:06:53 POST /presentations/logstash-monitorama-2013/css/print/paper.css
10.0.0.1 10003 17/05/2015:10:07:53 POST /presentations/logstash-monitorama-2013/css/print/paper.css
10.0.0.1 10003 17/05/2015:10:08:53 POST /presentations/logstash-monitorama-2013/css/print/paper.css
10.0.0.1 10003 17/05/2015:10:09:53 POST /presentations/logstash-monitorama-2013/css/print/paper.css
10.0.0.1 10003 17/05/2015:10:10:53 POST /presentations/logstash-monitorama-2013/css/print/paper.css
10.0.0.1 10003 17/05/2015:10:16:53 POST /presentations/logstash-monitorama-2013/css/print/paper.css
10.0.0.1 10003 17/05/2015:10:26:53 POST /presentations/logstash-monitorama-2013/css/print/paper.css
步骤
- 获取ExecutionEnvironment运行环境
- 使用readTextFile读取数据构建数据源
- 创建一个ApacheLogEvent类
- 使用map操作执行转换
- 打印测试
package batch.transformation;import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.operators.MapOperator;import java.text.SimpleDateFormat;/* 演示Flink map算子*/
public class MapDemo {public static void main(String[] args) throws Exception {// 0. EnvExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();// 1. SourceDataSource<String> logSource = env.readTextFile("data/input/apache.log");// 2. 使用map 转换字符串为 JavaBean对象MapOperator<String, ApacheEventLog> result = logSource.map(new MapFunction<String, ApacheEventLog>() {// 注意: 当前的日期转换对象, 是运行在TaskManager中的 也就是被分布式执行的// 构建日期转换 17/05/2015:10:05:30final SimpleDateFormat inputSDF = new SimpleDateFormat("dd/MM/yyyy:HH:mm:ss");final SimpleDateFormat outSDF = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");@Overridepublic ApacheEventLog map(String value) throws Exception {String[] arr = value.split(" ");String ip = arr[0];String userID = arr[1];String date = outSDF.format(inputSDF.parse(arr[2]).getTime());String method = arr[3];String url = arr[4];ApacheEventLog apacheEventLog = new ApacheEventLog(ip, userID, date, method, url);return apacheEventLog;}});result.print();}public static class ApacheEventLog{private String ip;private String userID;private String date;private String method;private String url;public ApacheEventLog() {}public ApacheEventLog(String ip, String userID, String date, String method, String url) {this.ip = ip;this.userID = userID;this.date = date;this.method = method;this.url = url;}public String getIp() {return ip;}public void setIp(String ip) {this.ip = ip;}public String getUserID() {return userID;}public void setUserID(String userID) {this.userID = userID;}public String getDate() {return date;}public void setDate(String date) {this.date = date;}public String getMethod() {return method;}public void setMethod(String method) {this.method = method;}public String getUrl() {return url;}public void setUrl(String url) {this.url = url;}@Overridepublic String toString() {return "ApacheEventLog{" +"ip='" + ip + '\\'' +", userID='" + userID + '\\'' +", date='" + date + '\\'' +", method='" + method + '\\'' +", url='" + url + '\\'' +'}';}}
}
FlatMap
将DataSet中的每一个元素转换为0…n个元素
示例
读取flatmap.log文件中的数据
如:
张三,苹果手机,联想电脑,华为平板
李四,华为手机,苹果电脑,小米平板
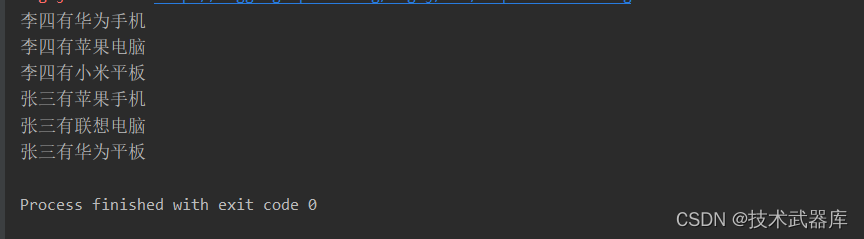
转换为
张三有苹果手机
张三有联想电脑
张三有华为平板
李四有…
…
…思路
以上数据为一条转换为三条,显然,应当使用flatMap来实现分别在flatMap函数中构建三个数据,并放入到一个列表中
步骤
- 构建批处理运行环境
- 构建本地集合数据源
- 使用flatMap将一条数据经过处理转换为三条数据
- 使用逗号分隔字段
- 分别构建三条数据
- 打印输出
package batch.transformation;import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.operators.FlatMapOperator;
import org.apache.flink.util.Collector;/* 演示FlatMap* 需求是将一行数据变成多行返回的时候不要嵌套list* 可以用flatMap*/
public class FlatMapDemo {public static void main(String[] args) throws Exception {// 0. EnvExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();// env.setParallelism(1);// 1. SourceDataSource<String> fileSource = env.readTextFile("data/input/flatmap.log");// 2. flatMap转换FlatMapOperator<String, String> result = fileSource.flatMap(new FlatMapFunction<String, String>() {@Override/* flatMap 没有返回值* 多行的输出就通过调用Collector对象的collect方法进行传递即可*/public void flatMap(String value, Collector<String> out) throws Exception {String[] arr = value.split(",");String name = arr[0];out.collect(name + "有" + arr[1]);out.collect(name + "有" + arr[2]);out.collect(name + "有" + arr[3]);}});result.print();}
}
Filter
过滤出来一些符合条件的元素
示例
读取apache.log文件中的访问日志数据,过滤出来以下访问IP是83.149.9.216的访问日志。
86.149.9.216 10001 17/05/2015:10:05:30 GET /presentations/logstash-monitorama-2013/images/github-contributions.png
83.149.9.216 10002 17/05/2015:10:06:53 GET /presentations/logstash-monitorama-2013/css/print/paper.css
83.149.9.216 10002 17/05/2015:10:06:53 GET /presentations/logstash-monitorama-2013/css/print/paper.css
83.149.9.216 10002 17/05/2015:10:06:53 GET /presentations/logstash-monitorama-2013/css/print/paper.css
83.149.9.216 10002 17/05/2015:10:06:53 GET /presentations/logstash-monitorama-2013/css/print/paper.css
83.149.9.216 10002 17/05/2015:10:06:53 GET /presentations/logstash-monitorama-2013/css/print/paper.css
83.149.9.216 10002 17/05/2015:10:06:53 GET /presentations/logstash-monitorama-2013/css/print/paper.css
10.0.0.1 10003 17/05/2015:10:06:53 POST /presentations/logstash-monitorama-2013/css/print/paper.css
10.0.0.1 10003 17/05/2015:10:07:53 POST /presentations/logstash-monitorama-2013/css/print/paper.css
10.0.0.1 10003 17/05/2015:10:08:53 POST /presentations/logstash-monitorama-2013/css/print/paper.css
10.0.0.1 10003 17/05/2015:10:09:53 POST /presentations/logstash-monitorama-2013/css/print/paper.css
10.0.0.1 10003 17/05/2015:10:10:53 POST /presentations/logstash-monitorama-2013/css/print/paper.css
10.0.0.1 10003 17/05/2015:10:16:53 POST /presentations/logstash-monitorama-2013/css/print/paper.css
10.0.0.1 10003 17/05/2015:10:26:53 POST /presentations/logstash-monitorama-2013/css/print/paper.css步骤
- 获取ExecutionEnvironment运行环境
- 使用fromCollection构建数据源
- 使用filter操作执行过滤
- 打印测试
package batch.transformation;import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.operators.FilterOperator;public class FilterDemo {public static void main(String[] args) throws Exception {ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();DataSource<String> logSource = env.readTextFile("data/input/apache.log");// filter过滤FilterOperator<String> result = logSource.filter(new FilterFunction<String>() {@Overridepublic boolean filter(String value) throws Exception {String ip = value.split(" ")[0];return ip.equals("83.149.9.216");}});result.print();}
}Reduce
可以对一个 dataset 或者一个 group 来进行聚合计算,最终聚合成一个元素
示例
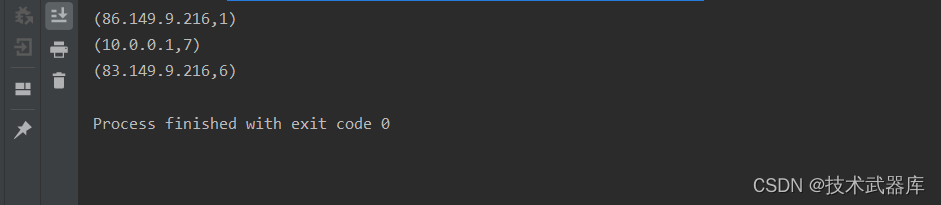
读取apache.log日志,统计ip地址访问pv数量,使用 reduce 操作聚合成一个最终结果
86.149.9.216 10001 17/05/2015:10:05:30 GET /presentations/logstash-monitorama-2013/images/github-contributions.png
83.149.9.216 10002 17/05/2015:10:06:53 GET /presentations/logstash-monitorama-2013/css/print/paper.css
83.149.9.216 10002 17/05/2015:10:06:53 GET /presentations/logstash-monitorama-2013/css/print/paper.css
83.149.9.216 10002 17/05/2015:10:06:53 GET /presentations/logstash-monitorama-2013/css/print/paper.css
83.149.9.216 10002 17/05/2015:10:06:53 GET /presentations/logstash-monitorama-2013/css/print/paper.css
83.149.9.216 10002 17/05/2015:10:06:53 GET /presentations/logstash-monitorama-2013/css/print/paper.css
83.149.9.216 10002 17/05/2015:10:06:53 GET /presentations/logstash-monitorama-2013/css/print/paper.css
10.0.0.1 10003 17/05/2015:10:06:53 POST /presentations/logstash-monitorama-2013/css/print/paper.css
10.0.0.1 10003 17/05/2015:10:07:53 POST /presentations/logstash-monitorama-2013/css/print/paper.css
10.0.0.1 10003 17/05/2015:10:08:53 POST /presentations/logstash-monitorama-2013/css/print/paper.css
10.0.0.1 10003 17/05/2015:10:09:53 POST /presentations/logstash-monitorama-2013/css/print/paper.css
10.0.0.1 10003 17/05/2015:10:10:53 POST /presentations/logstash-monitorama-2013/css/print/paper.css
10.0.0.1 10003 17/05/2015:10:16:53 POST /presentations/logstash-monitorama-2013/css/print/paper.css
10.0.0.1 10003 17/05/2015:10:26:53 POST /presentations/logstash-monitorama-2013/css/print/paper.css结果类似:
(86.149.9.216,1)
(10.0.0.1,7)
(83.149.9.216,6)
步骤
- 获取 ExecutionEnvironment 运行环境
- 使用 readTextFile 构建数据源
- 使用 reduce 执行聚合操作
- 打印测试
package batch.transformation;import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.operators.MapOperator;
import org.apache.flink.api.java.operators.ReduceOperator;
import org.apache.flink.api.java.operators.UnsortedGrouping;
import org.apache.flink.api.java.tuple.Tuple2;public class ReduceDemo {public static void main(String[] args) throws Exception {ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();DataSource<String> logSource = env.readTextFile("data/input/apache.log");// 提取IP, 后面都跟上1(作为元组返回)MapOperator<String, Tuple2<String, Integer>> ipWithOne = logSource.map(new MapFunction<String, Tuple2<String, Integer>>() {@Overridepublic Tuple2<String, Integer> map(String value) throws Exception {String ip = value.split(" ")[0];return Tuple2.of(ip, 1);}});// 分组 + reduce聚合UnsortedGrouping<Tuple2<String, Integer>> grouped = ipWithOne.groupBy(0);// reduce 聚合ReduceOperator<Tuple2<String, Integer>> result = grouped.reduce(new ReduceFunction<Tuple2<String, Integer>>() {@Overridepublic Tuple2<String, Integer> reduce(Tuple2<String, Integer> value1, Tuple2<String, Integer> value2) throws Exception {return Tuple2.of(value1.f0, value1.f1 + value2.f1);}});result.print();}
}
reduceGroup
可以对一个dataset或者一个group来进行聚合计算,最终聚合成一个元素
reduce和reduceGroup的 区别
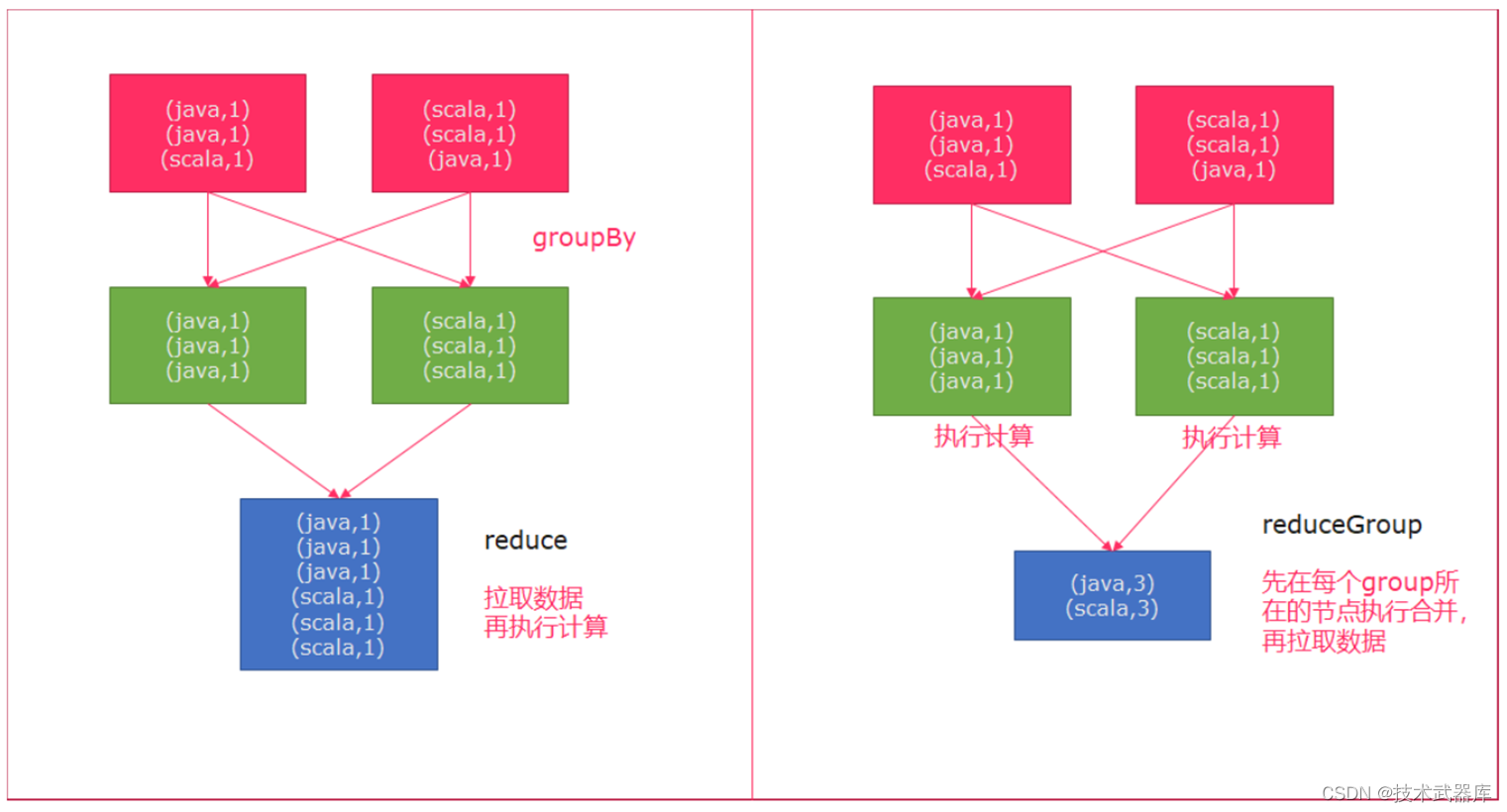
首先groupBy函数会将一个个的单词进行分组,分组后的数据被reduce一个个的拉取过来,这种方式如果数据量大的情况下,拉取的数据会非常多,增加了网络IO
reduceGroup是reduce的一种优化方案;
它会先分组reduce,然后在做整体的reduce;这样做的好处就是可以减少网络IO;
示例
读取apache.log日志,统计ip地址访问pv数量,使用 reduceGroup 操作聚合成一个最终结果
步骤
- 获取 ExecutionEnvironment 运行环境
- 使用 readTextFile 构建数据源
- 使用 groupBy 按照单词进行分组
- 使用 reduceGroup 对每个分组进行统计
- 打印测试
package batch.transformation;import org.apache.flink.api.common.functions.GroupReduceFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.*;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;public class ReduceGroupDemo {public static void main(String[] args) throws Exception {ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();DataSource<String> logSource = env.readTextFile("data/input/apache.log");// 提取IP, 后面都跟上1(作为元组返回)MapOperator<String, Tuple2<String, Integer>> ipWithOne = logSource.map(new MapFunction<String, Tuple2<String, Integer>>() {@Overridepublic Tuple2<String, Integer> map(String value) throws Exception {String ip = value.split(" ")[0];return Tuple2.of(ip, 1);}});// 分组UnsortedGrouping<Tuple2<String, Integer>> grouped = ipWithOne.groupBy(0);// reduceGroup聚合: 一次聚合一整个分区 节省海量的网络IO请求次数GroupReduceOperator<Tuple2<String, Integer>, Tuple2<String, Integer>> result = grouped.reduceGroup(new GroupReduceFunction<Tuple2<String, Integer>, Tuple2<String, Integer>>() {@Overridepublic void reduce(Iterable<Tuple2<String, Integer>> allGroupData, Collector<Tuple2<String, Integer>> out) throws Exception {String key = "";int counter = 0;for (Tuple2<String, Integer> tuple : allGroupData) {key = tuple.f0;counter += tuple.f1;}out.collect(Tuple2.of(key, counter));}});result.print();}
}
Aggregate
按照内置的方式来进行聚合。例如:SUM/MIN/MAX…
示例
读取apache.log日志,统计ip地址访问pv数量,使用 aggregate 操作进行PV访问量统计
86.149.9.216 10001 17/05/2015:10:05:30 GET /presentations/logstash-monitorama-2013/images/github-contributions.png
83.149.9.216 10002 17/05/2015:10:06:53 GET /presentations/logstash-monitorama-2013/css/print/paper.css
83.149.9.216 10002 17/05/2015:10:06:53 GET /presentations/logstash-monitorama-2013/css/print/paper.css
83.149.9.216 10002 17/05/2015:10:06:53 GET /presentations/logstash-monitorama-2013/css/print/paper.css
83.149.9.216 10002 17/05/2015:10:06:53 GET /presentations/logstash-monitorama-2013/css/print/paper.css
83.149.9.216 10002 17/05/2015:10:06:53 GET /presentations/logstash-monitorama-2013/css/print/paper.css
83.149.9.216 10002 17/05/2015:10:06:53 GET /presentations/logstash-monitorama-2013/css/print/paper.css
10.0.0.1 10003 17/05/2015:10:06:53 POST /presentations/logstash-monitorama-2013/css/print/paper.css
10.0.0.1 10003 17/05/2015:10:07:53 POST /presentations/logstash-monitorama-2013/css/print/paper.css
10.0.0.1 10003 17/05/2015:10:08:53 POST /presentations/logstash-monitorama-2013/css/print/paper.css
10.0.0.1 10003 17/05/2015:10:09:53 POST /presentations/logstash-monitorama-2013/css/print/paper.css
10.0.0.1 10003 17/05/2015:10:10:53 POST /presentations/logstash-monitorama-2013/css/print/paper.css
10.0.0.1 10003 17/05/2015:10:16:53 POST /presentations/logstash-monitorama-2013/css/print/paper.css
10.0.0.1 10003 17/05/2015:10:26:53 POST /presentations/logstash-monitorama-2013/css/print/paper.css步骤
- 获取 ExecutionEnvironment 运行环境
- 使用 readTextFile 构建数据源
- 使用 groupBy 按照单词进行分组
- 使用 aggregate 对每个分组进行 SUM 统计
- 打印测试
reduceGroupedSource.aggregate(Aggregations.MAX, 1);
Aggregate只能作用于元组上

如图:注意,只可用于元组进行Aggregate
package batch.transformation;import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.aggregation.Aggregations;
import org.apache.flink.api.java.operators.AggregateOperator;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.operators.MapOperator;
import org.apache.flink.api.java.operators.UnsortedGrouping;
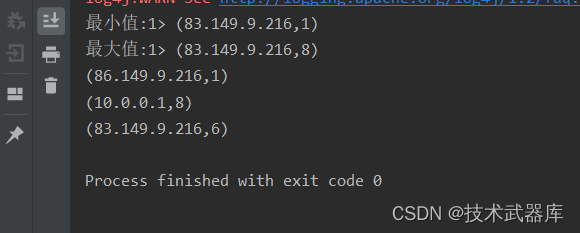
import org.apache.flink.api.java.tuple.Tuple2;public class AggregateDemo {public static void main(String[] args) throws Exception {ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();DataSource<String> logSource = env.readTextFile("data/input/apache.log");// 提取IP, 后面都跟上1(作为元组返回)MapOperator<String, Tuple2<String, Integer>> ipWithOne = logSource.map(new MapFunction<String, Tuple2<String, Integer>>() {@Overridepublic Tuple2<String, Integer> map(String value) throws Exception {String ip = value.split(" ")[0];return Tuple2.of(ip, 1);}});// 分组UnsortedGrouping<Tuple2<String, Integer>> grouped = ipWithOne.groupBy(0);// 求和操作AggregateOperator<Tuple2<String, Integer>> sumResult = grouped.aggregate(Aggregations.SUM, 1);// 这个就是aggregate算子的快捷写法AggregateOperator<Tuple2<String, Integer>> sumResult2 = grouped.sum(1);// 求最大值 最小值// print方法中 传入字符串可以作为输出的前缀, minBy maxBysumResult.aggregate(Aggregations.MIN, 1).print("最小值");sumResult.aggregate(Aggregations.MAX, 1).print("最大值");// 快捷写法sumResult2.min(1);sumResult2.max(1);env.execute();}
}
Aggregate的简写形式
注意:aggregate有简写的形式,比如:
reduceGroupedSource.aggregate(Aggregations.MAX, 1);
可以写成reduceGroupedSource.max(1);
max方法本质上还是调用的aggregate方法, 这是一种简单写法
min, sum 同理

从源码中可见, max方法还是调用的aggregate
minBy和maxBy
获取指定字段的最大值、最小值
示例
读取apache.log日志,统计ip地址访问pv数量,使用 minBy、maxBy操作进行PV访问量统计
86.149.9.216 10001 17/05/2015:10:05:30 GET /presentations/logstash-monitorama-2013/images/github-contributions.png
83.149.9.216 10002 17/05/2015:10:06:53 GET /presentations/logstash-monitorama-2013/css/print/paper.css
83.149.9.216 10002 17/05/2015:10:06:53 GET /presentations/logstash-monitorama-2013/css/print/paper.css
83.149.9.216 10002 17/05/2015:10:06:53 GET /presentations/logstash-monitorama-2013/css/print/paper.css
83.149.9.216 10002 17/05/2015:10:06:53 GET /presentations/logstash-monitorama-2013/css/print/paper.css
83.149.9.216 10002 17/05/2015:10:06:53 GET /presentations/logstash-monitorama-2013/css/print/paper.css
83.149.9.216 10002 17/05/2015:10:06:53 GET /presentations/logstash-monitorama-2013/css/print/paper.css
10.0.0.1 10003 17/05/2015:10:06:53 POST /presentations/logstash-monitorama-2013/css/print/paper.css
10.0.0.1 10003 17/05/2015:10:07:53 POST /presentations/logstash-monitorama-2013/css/print/paper.css
10.0.0.1 10003 17/05/2015:10:08:53 POST /presentations/logstash-monitorama-2013/css/print/paper.css
10.0.0.1 10003 17/05/2015:10:09:53 POST /presentations/logstash-monitorama-2013/css/print/paper.css
10.0.0.1 10003 17/05/2015:10:10:53 POST /presentations/logstash-monitorama-2013/css/print/paper.css
10.0.0.1 10003 17/05/2015:10:16:53 POST /presentations/logstash-monitorama-2013/css/print/paper.css
10.0.0.1 10003 17/05/2015:10:26:53 POST /presentations/logstash-monitorama-2013/css/print/paper.css
10.0.0.1 10003 17/05/2015:10:26:53 POST /presentations/logstash-monitorama-2013/css/print/paper.css
步骤
- 获取 ExecutionEnvironment 运行环境
- 使用 fromCollection 构建数据源
- 使用 groupBy 按照单词进行分组
- 使用 maxBy、minBy对每个分组进行操作
- 打印测试
package batch.transformation;import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.operators.MapOperator;
import org.apache.flink.api.java.operators.ReduceOperator;
import org.apache.flink.api.java.tuple.Tuple2;/* @author lwh* @date 2023/4/12* @description/
public class MinByMaxByDemo2 {public static void main(String[] args) throws Exception {ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();DataSource<String> textFileSource = env.readTextFile("data/input/apache.log");MapOperator<String, Tuple2<String, Integer>> ipWithOne = textFileSource.map(new MapFunction<String, Tuple2<String, Integer>>() {@Overridepublic Tuple2<String, Integer> map(String value) throws Exception {return Tuple2.of(value.split(" ")[0], 1);}});ReduceOperator<Tuple2<String, Integer>> reduced = ipWithOne.groupBy(0).reduce(new ReduceFunction<Tuple2<String, Integer>>() {@Overridepublic Tuple2<String, Integer> reduce(Tuple2<String, Integer> value1, Tuple2<String, Integer> value2) throws Exception {return Tuple2.of(value1.f0, value1.f1 + value2.f1);}});reduced.minBy(1).print();reduced.maxBy(1).print();}
}Aggregate 和 minBy maxBy的区别
Aggregate的min 和 min 方式 对比minBy 和maxBy的区别在:
以min和minBy举例:
首先: 都只能应用于元组数据
另外最重要的区别在于,计算逻辑不同,尽管都是求最小值,但是:
Min在计算的过程中,会记录最小值,对于其它的列,会取最后一次出现的,然后和最小值组合形成结果返回
minBy在计算的过程中,当遇到最小值后,将第一次出现的最小值所在的整个元素返回。
package batch.transformation;import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.tuple.Tuple2;/* Yanshi minBy 和 aggregate.min的区别*/
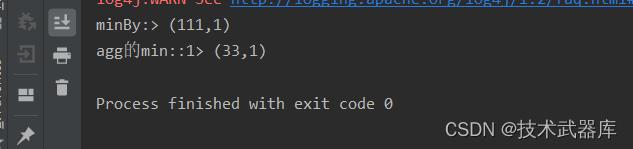
public class MinByVSAggregateMinDemo {public static void main(String[] args) throws Exception {ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();DataSource<Tuple2<Integer, Integer>> source = env.fromElements(Tuple2.of(3, 2),Tuple2.of(1, 2),Tuple2.of(2, 3),Tuple2.of(111, 1),Tuple2.of(1, 1),Tuple2.of(3, 1),Tuple2.of(0, 1),Tuple2.of(33, 2));// 聚合求最小// aggregate的min计算source.min(1).print("agg的min:");source.minBy(1).print("minBy:");/*aggregate的min 和 max: 找到最小值和最大值后, 拼接最后一条数据的其它元素, 组合成结果返回minBy或者maxBy: 找到第一条出现的最小值 或者最大值 将这一条数据作为结果返回所以, minBy或者maxBy的结果更加准确, 一般我们追求结果集的完整选择它们如果只想要最大或者最小值本身, 对结果集的其它内容无所谓, 可以用agg的min和max*/env.execute();}
}
distinct去重
去除重复的数据
示例
读取apache.log日志,统计有哪些ip访问了网站
步骤
- 获取 ExecutionEnvironment 运行环境
- 使用 readTextFile 构建数据源
- 使用 distinct 指定按照哪个字段来进行去重
- 打印测试
package batch.transformation;import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.operators.DistinctOperator;
import org.apache.flink.api.java.operators.MapOperator;public class DistinctDemo {public static void main(String[] args) throws Exception {ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();DataSource<String> logSource = env.readTextFile("data/input/apache.log");// 提取全部的ipMapOperator<String, String> ips = logSource.map(new MapFunction<String, String>() {@Overridepublic String map(String value) throws Exception {return value.split(" ")[0];}});// 对ip进行去重操作DistinctOperator<String> result = ips.distinct();result.print();}
}
/*
distinct算子可以完成 ```全局```去重. ( 撇除分区的影响, 进行整体去重)*/注意:distinct(字段index)只可用于tuple类型

Join
使用join可以将两个DataSet连接起来
示例
有两个csv文件,有一个为 score.csv ,一个为 subject.csv ,分别保存了成绩数据以及学科数据

需要将这两个数据连接到一起,然后打印出来。
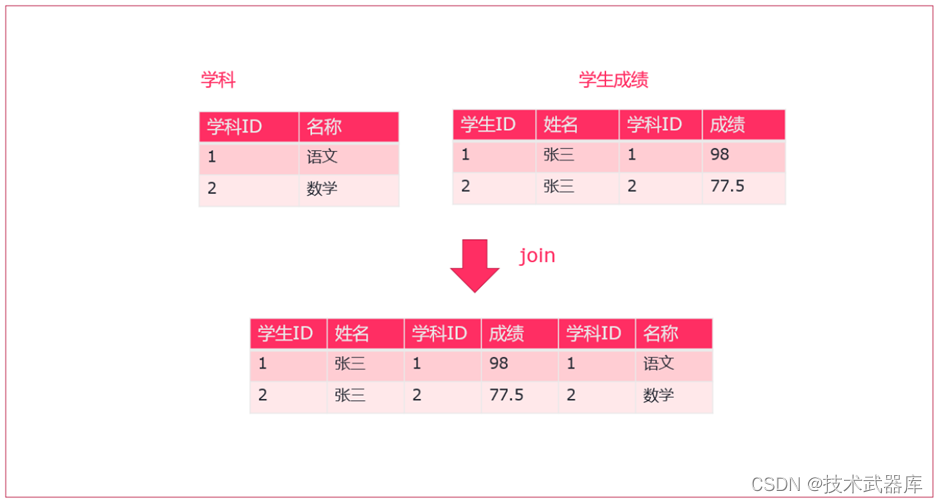
步骤
- 分别将两个文件复制到项目中的 data/join/input 中
- 构建批处理环境
- 创建两个类
学科Subject(学科ID、学科名字)
成绩Score(唯一ID、学生姓名、学科ID、分数——Double类型) - 分别使用 readCsvFile 加载csv数据源,并制定泛型
- 使用join连接两个DataSet,并使用 where 、 equalTo 方法设置关联条件
- 打印关联后的数据源
package batch.transformation;import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.operators.JoinOperator;
import org.apache.flink.api.java.operators.MapOperator;
import org.apache.flink.api.java.tuple.Tuple2;/* 演示Flink的Join算子* 对两个DataSet进行关联, 形成一个DataSet返回*/
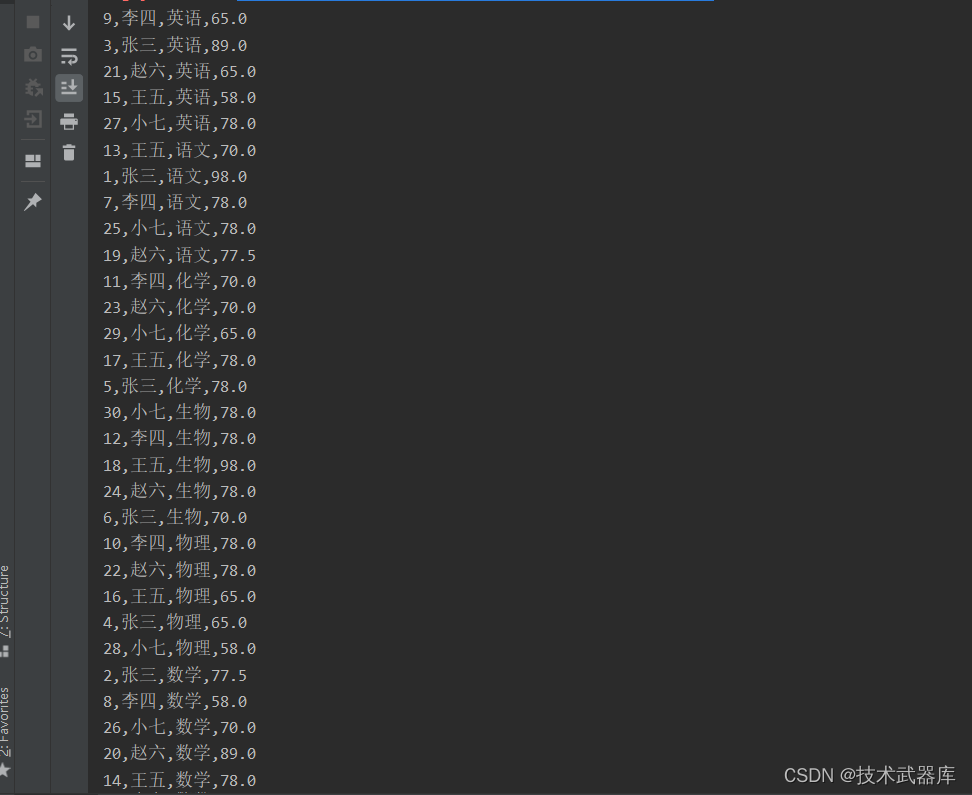
public class JoinDemo {public static void main(String[] args) throws Exception {ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();// read 学科数据DataSource<String> subjectSource = env.readTextFile("data/input/subject.csv");// read scoreDataSource<String> scoreSource = env.readTextFile("data/input/score.csv");// 将两份数据集 转变成JavaBeanMapOperator<String, Subject> subject = subjectSource.map(new MapFunction<String, Subject>() {@Overridepublic Subject map(String value) throws Exception {String[] arr = value.split(",");return new Subject(Integer.parseInt(arr[0]), arr[1]);}});MapOperator<String, Score> score = scoreSource.map(new MapFunction<String, Score>() {@Overridepublic Score map(String value) throws Exception {String[] arr = value.split(",");return new Score(Integer.parseInt(arr[0]), arr[1], Integer.parseInt(arr[2]), Double.parseDouble(arr[3]));}});// 对两个数据集进行join// where表示join左边的数据集, equalTo表示右边的数据集// Join完成后形成一个二元元组对象返回, 元组中 第一个列是 左边数据集, 第二个列是右边的数据集JoinOperator.DefaultJoin<Score, Subject> joined = score.join(subject).where("subjectID").equalTo("id");// 对于左外和右外可以使用 leftOuterJoin和 rightOuterJoin 写法和join一致// 我们的join算子是 ```内关联```模式score.leftOuterJoin(subject).where("subjectID").equalTo("id");// 全外关联也支持 笛卡尔积score.fullOuterJoin(subject);// 将学生分数中的学科id 替换为学科名称MapOperator<Tuple2<Score, Subject>, String> result = joined.map(new MapFunction<Tuple2<Score, Subject>, String>() {@Overridepublic String map(Tuple2<Score, Subject> value) throws Exception {int sid = value.f0.id;String sname = value.f0.name;String subjectName = value.f1.name;Double score = value.f0.score;return sid + "," + sname + "," + subjectName + "," + score;}});result.print();}// POJO类: JavaBeanpublic static class Subject{private int id;private String name;public Subject() {}public Subject(int id, String name) {this.id = id;this.name = name;}public int getId() {return id;}public void setId(int id) {this.id = id;}public String getName() {return name;}public void setName(String name) {this.name = name;}@Overridepublic String toString() {return "Subject{" +"id=" + id +", name='" + name + '\\'' +'}';}}public static class Score{private int id;private String name;private int subjectID;private Double score;public Score() {}public Score(int id, String name, int subjectID, Double score) {this.id = id;this.name = name;this.subjectID = subjectID;this.score = score;}@Overridepublic String toString() {return "Score{" +"id=" + id +", name='" + name + '\\'' +", subjectID=" + subjectID +", score=" + score +'}';}public int getId() {return id;}public void setId(int id) {this.id = id;}public String getName() {return name;}public void setName(String name) {this.name = name;}public int getSubjectID() {return subjectID;}public void setSubjectID(int subjectID) {this.subjectID = subjectID;}public Double getScore() {return score;}public void setScore(Double score) {this.score = score;}}
}
Union
将多个DataSet合并成一个DataSet
【注意】:union合并的DataSet的类型必须是一致的
示例
将以下数据进行取并集操作
数据集1
"hadoop", "hive", "flume"
数据集2
"hadoop", "hive", "spark"
步骤
- 构建批处理运行环境
- 使用 fromCollection 创建两个数据源
- 使用 union 将两个数据源关联在一起
- 打印测试
注意:union可以取并集,但是不会去重。
package batch.transformation;import org.apache.flink.api.java.ExecutionEnvironment;
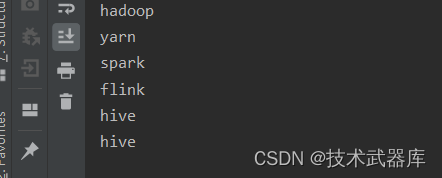
import org.apache.flink.api.java.operators.DataSource;public class UnionDemo {public static void main(String[] args) throws Exception {ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();DataSource<String> source1 = env.fromElements("hadoop", "spark", "hive");DataSource<String> source2 = env.fromElements("yarn", "flink", "hive");source1.union(source2).print();/*Union算子 会进行合并, 不会进行重复判断Union算子 必须进行 同类型元素的合并, 哪怕是顶级类Object也不行, 必须是实体类(撇除继承关系)的类型一致才可以*/}
}
Rebalance
Flink也有数据倾斜的时候,比如当前有数据量大概10亿条数据需要处理,在处理过程中可能会发生如图所示的状况:
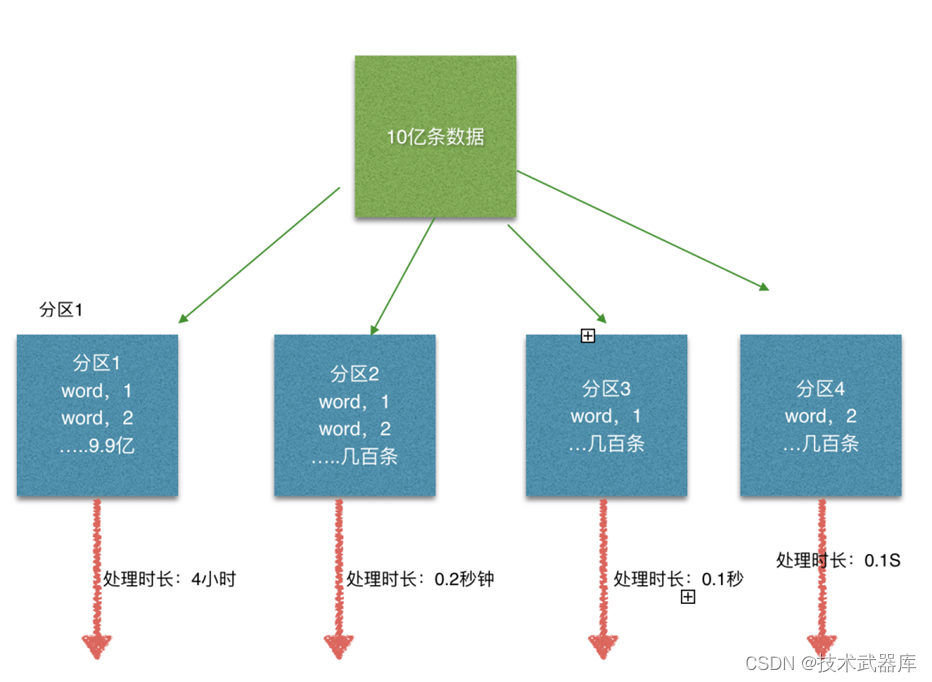
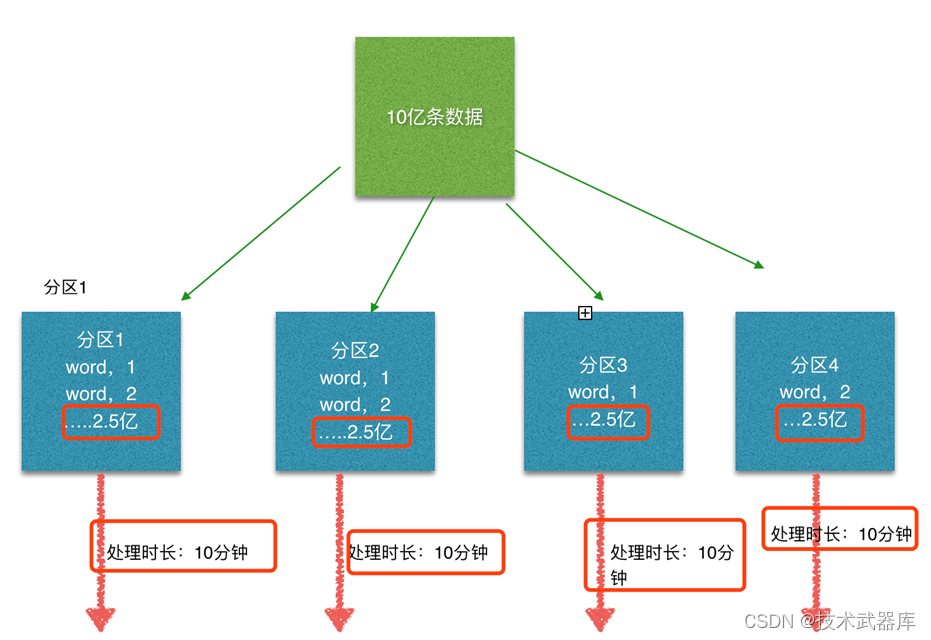
这个时候本来总体数据量只需要10分钟解决的问题,出现了数据倾斜,机器1上的任务需要4个小时才能完成,那么其他3台机器执行完毕也要等待机器1执行完毕后才算整体将任务完成;
所以在实际的工作中,出现这种情况比较好的解决方案就是本节课要讲解的—rebalance
步骤
- 构建批处理运行环境
- 使用 env.generateSequence 创建0-100的并行数据
- 使用 fiter 过滤出来 大于8 的数字
- 使用map操作传入 RichMapFunction ,将当前子任务的ID和数字构建成一个元组
- 在RichMapFunction中可以使用getRuntimeContext.getIndexOfThisSubtask 获取子任务序号
- 打印测试
举例
在不使用rebalance的情况下,观察每一个线程执行的任务特点
package batch.transformation;import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.operators.FilterOperator;
import org.apache.flink.api.java.operators.MapOperator;
import org.apache.flink.api.java.tuple.Tuple2;/* @author lwh* @date 2023/4/12* @description 在不使用rebalance的情况下,观察每一个线程执行的任务特点/
public class BatchDemoRebalance {public static void main(String[] args) throws Exception {ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();DataSource<Long> ds = env.generateSequence(0, 100);FilterOperator<Long> filter = ds.filter(new FilterFunction<Long>() {@Overridepublic boolean filter(Long aLong) throws Exception {return aLong > 8;}});MapOperator<Long, Tuple2<Integer, Long>> countsInPartition = filter.map(new RichMapFunction<Long, Tuple2<Integer, Long>>() {@Overridepublic Tuple2<Integer, Long> map(Long in) throws Exception {//获取并行时子任务的编号getRuntimeContext.getIndexOfThisSubtaskreturn Tuple2.of(getRuntimeContext().getIndexOfThisSubtask(), in);}});countsInPartition.print();}
}使用rebalance
package batch.transformation;import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.operators.FilterOperator;
import org.apache.flink.api.java.operators.MapOperator;
import org.apache.flink.api.java.operators.PartitionOperator;
import org.apache.flink.api.java.tuple.Tuple2;public class RebalanceDemo {public static void main(String[] args) throws Exception {ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();/* 生成一个序列, 接受2个参数* 参数1: 开始* 参数2: 结束*/DataSource<Long> source = env.generateSequence(1, 100);FilterOperator<Long> data = source.filter(new FilterFunction<Long>() {@Overridepublic boolean filter(Long value) throws Exception {return value > 16;}});// 调用rebalance进行重新平衡PartitionOperator<Long> rebalancedData = data.rebalance();/* RichMapFunction 是一个增强版的MapFunction* 增强了2个主要功能:* 1. 可以在里面获得运行时上下文环境"RuntimeContext", 通过getRuntimeContext获取* 2. 它带有open(构建类执行一次)和close(关闭类执行一次)的方法, 可以被复写*/MapOperator<Long, Tuple2<Long, Long>> result = rebalancedData.map(new RichMapFunction<Long, Tuple2<Long, Long>>() {@Overridepublic Tuple2<Long, Long> map(Long value) throws Exception {return Tuple2.of(value, getRuntimeContext().getIndexOfThisSubtask() + 0L);}});result.print();}
}分区
partitionByHash

按照指定的key进行hash分区
分区数量和并行度有关,如果不设置并行度,会自动根据内容自动设置分区数量
还有一个同类函数:partitionByRange 按照key的范围进行排序
Hash和Range是Flink自行控制,我们无法控制
Hash规则是一样的key放入一个分区
Range是值范围在一个区域内(接近)的key,在一个分区
步骤
- 构建批处理运行环境
- 设置并行度为 2
- 使用 fromCollection 构建测试数据集
- 使用 partitionByHash 按照字符串的hash进行分区
- 调用 writeAsText 写入文件到 data/parition_output 目录中
- 打印测试
package batch.transformation;import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.operators.PartitionOperator;
import org.apache.flink.api.java.tuple.Tuple2;public class PartitionByHash {public static void main(String[] args) throws Exception {ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();env.setParallelism(3);DataSource<Tuple2<Integer, Integer>> source = env.fromElements(Tuple2.of(1, 1),Tuple2.of(2, 1),Tuple2.of(3, 1),Tuple2.of(4, 1),Tuple2.of(5, 1),Tuple2.of(6, 1),Tuple2.of(7, 1),Tuple2.of(8, 1),Tuple2.of(9, 1),Tuple2.of(10, 1),Tuple2.of(11, 1),Tuple2.of(12, 1),Tuple2.of(13, 1),Tuple2.of(14, 1),Tuple2.of(15, 1));/*partitionByHash 相同的key会在同一个分区内partitionByRange 按照分区字段的值 来进行均分范围, 相近值的数据 会在一个分区内range的计算是, 最小值和最大值之间, 按照并行度(分区数)最`范围`的均分range是字典值(ASCII)*/PartitionOperator<Tuple2<Integer, Integer>> partitioned = source.partitionByHash(0);
// PartitionOperator<Tuple2<Integer, Integer>> partitioned = source.partitionByRange(0);// 想自定义的话, 需要自定义分区逻辑
// source.partitionCustom()partitioned.map(new RichMapFunction<Tuple2<Integer, Integer>, Tuple2<Integer, Long>>() {@Overridepublic Tuple2<Integer, Long> map(Tuple2<Integer, Integer> value) throws Exception {return Tuple2.of(value.f0, getRuntimeContext().getIndexOfThisSubtask() + 0L);}}).print();}
}sortPartition
根据指定的字段值进行分区的排序;
sortPartition(field, order)

package batch.transformation;import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.api.common.operators.Order;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.operators.MapOperator;
import org.apache.flink.api.java.operators.SortPartitionOperator;
import org.apache.flink.api.java.tuple.Tuple2;/* @author lwh* @date 2023/4/12* @description/
public class SortPartitionDemo {public static void main(String[] args) throws Exception {ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();DataSource<Tuple2<String, Integer>> source = env.fromElements(Tuple2.of("hadoop", 11),Tuple2.of("hadoop", 21),Tuple2.of("hadoop", 3),Tuple2.of("hadoop", 16),Tuple2.of("hive", 13),Tuple2.of("hive", 31),Tuple2.of("hive", 21),Tuple2.of("hive", 11),Tuple2.of("hive", 15),Tuple2.of("hive", 19),Tuple2.of("spark", 51),Tuple2.of("spark", 61),Tuple2.of("spark", 19),Tuple2.of("spark", 35),Tuple2.of("spark", 66),Tuple2.of("spark", 76),Tuple2.of("flink", 11),Tuple2.of("flink", 51),Tuple2.of("flink", 31));// 仅按照单词排序SortPartitionOperator<Tuple2<String, Integer>> sorted1 = source.sortPartition(0, Order.ASCENDING);MapOperator<Tuple2<String, Integer>, Tuple2<Integer, Tuple2<String, Integer>>> pt1 = pt(sorted1);pt1.print();// 按照单词以及数字排序System.out.println("-----------");SortPartitionOperator<Tuple2<String, Integer>> sorted2 = source.sortPartition(0, Order.ASCENDING).sortPartition(1, Order.ASCENDING);pt(sorted2).print();// 在分区内部按照单词排序System.out.println("-----------");pt(source.partitionByHash(0).sortPartition(0, Order.ASCENDING)).print();// 在分区内部按照单词和数字排序System.out.println("-----------");pt(source.partitionByRange(0).sortPartition(0, Order.ASCENDING).sortPartition(1, Order.ASCENDING)).print();}public static MapOperator<Tuple2<String, Integer>, Tuple2<Integer, Tuple2<String, Integer>>> pt(DataSet<Tuple2<String, Integer>> ds){return ds.map(new RichMapFunction<Tuple2<String, Integer>, Tuple2<Integer, Tuple2<String, Integer>>>() {@Overridepublic Tuple2<Integer, Tuple2<String, Integer>> map(Tuple2<String, Integer> value) throws Exception {return Tuple2.of(getRuntimeContext().getIndexOfThisSubtask(), value);}});}}