学习系统编程No.19【进程间通信之控制进程】

引言:
北京时间:2023/4/13/8:00,早八人,早八魂,时间不怎么充足,磨磨引言刚好,学习Linux和Linux有关的系统级知识已经许久了,在不知不觉之中,发现自己已经更到了第19篇,已经赶超了C++的18篇,看来航哥的钱快要还不起了啊,难受,并且更难受的是蛋哥的钱也没还完,也许是课程难度在不断增加,也许是学校的课在不断增加,也许是我越来越摆烂导致,反正有关因素很多,这可能就是生活,总不能那么如意,但是我坚信目标,傻傻向前走就行,课总有一天会上完,钱总有一天会还完,大学总有一天会毕业,人生总有一天会结束,So,不管欠多少钱,珍惜眼前,把握当下(这种话,义务教育深埋我心,哈哈哈!)勇敢向前走就行啦!管他那么多呢,上天安排的最大嘛,ok,玩嘴巴我是专业的,07分了,上课去了,不过之前,我们先把学习内容写一下,该博客我们就来深入管道,并且力所能及的学习一下共享内存的知识,管道的知识博大精深,我们目前还不成气候!

深入管道有关知识
上篇博客,我们浅浅的认识了一下进程间通信的一个最经典场景,匿名管道的场景,并且也自己写代码将该场景构建出来了,但是我们学到的也只是管道有关知识最浅层的部分而已,所以该篇博客,就让我们深入管道有关知识,彻底搞懂进程之间是如何通信,并且是在什么场景什么环境下通信
匿名管道
上篇博客,我们了解了使用匿名管道来构建进程间通信环境,本质就是让具有血缘关系的进行可以共享同一份"资源",当然这里的资源指的就是匿名管道内存级文件对象资源,通过这个文件对象,此时血缘关系进程之间就可以进行通信,所以进程间通信的本质不是如何进行通信,而是如何构建进程间通信的信道方案
进程间通信代码实现(简易)

如上述代码,此时我们就实现了父进程和子进程间的通信,让他们实现了数据传输的功能(子进程可以将数据传给父进程)
管道通信的现象和结论
(在子进程写数据,父进程读数据的前提下)
- 写数据保持不变,读数据时,读慢一点
现象如图:
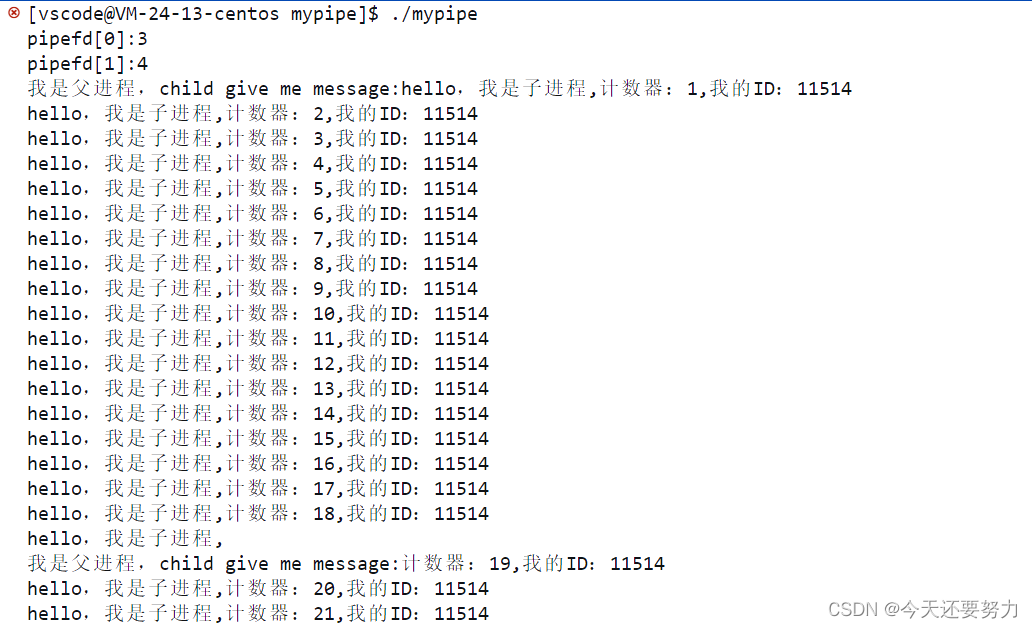
得出结论:在管道通信中,写入的次数和读取的次数不是严格匹配的,也就是说明读和写没有什么太大的关系,你写你的,我读我的,你写到那个位置,我读的时候就从那个位置开始读
- 读数据保持不变,写数据时写慢一点
现象如图:
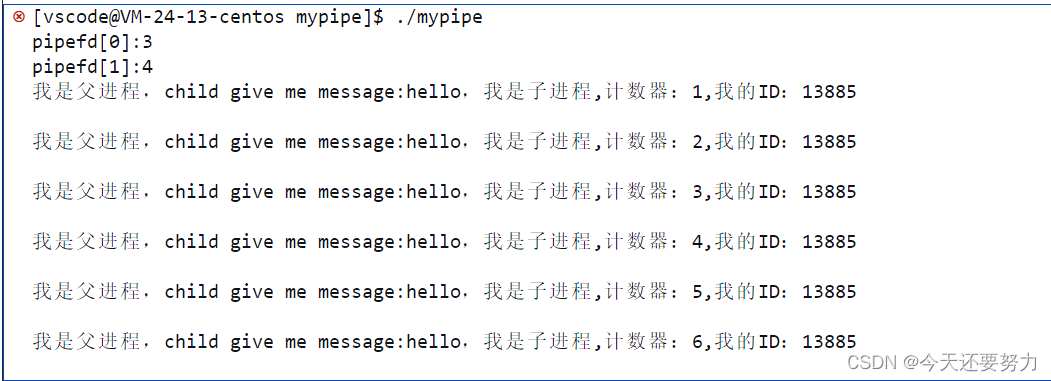
得出结论:写变慢了,导致读也会变慢,也就是read读取完了管道中的所有数据,如果对方不传送数据了,我们就只能等待
- 写端一直写数据(不使用buffer缓冲区),读端等待
现象如图:
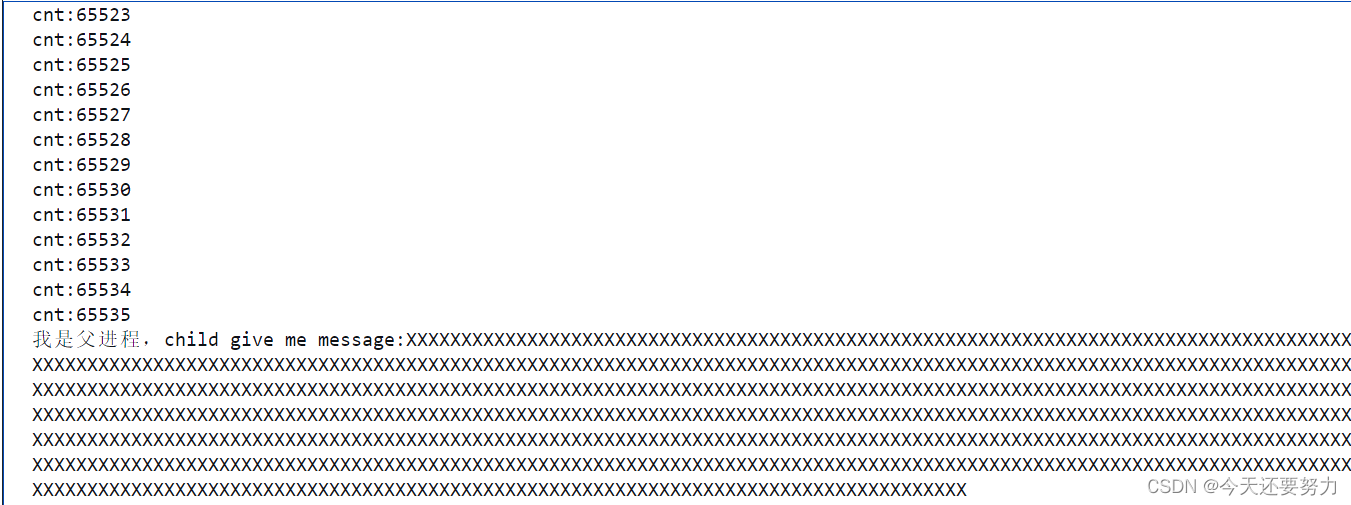
得出结论:管道文件也是有大小的(内存),所以当我们write端将管道文件写满了之后,此时就不能继续写入了,本质就是文件满了,写不下了,只有当数据被读端读取了之后(此时可以将管道文件中的所有数据一次性读取),写端才可以继续写入
- 写端写入一次数据之后就关闭,读端一直读取数据
现象如图:

得出结论:当读端第一次读取管道文件中的数据时,读到的是写端写入的数据X,当第二次进行读取时,此时因为写端关闭,所以read读取的是一个空管道文件,此时返回0,表示的就是读到0个字节大小的数据,也就是读到了文件结尾
- 写端一直写,读端关闭
现象如图:
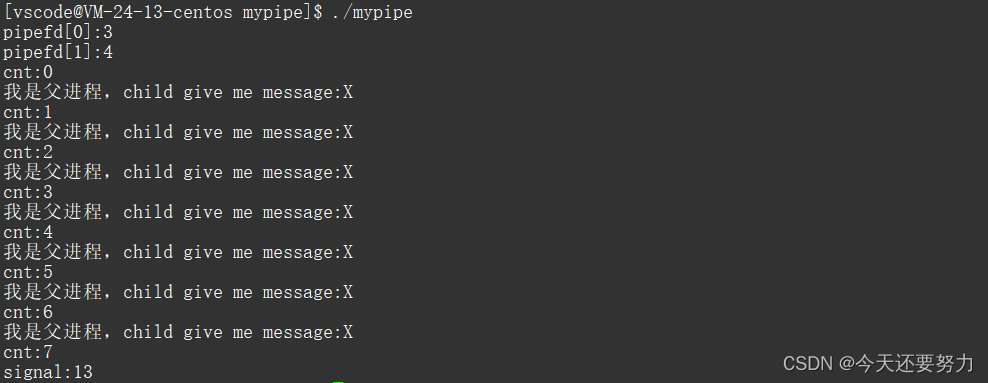
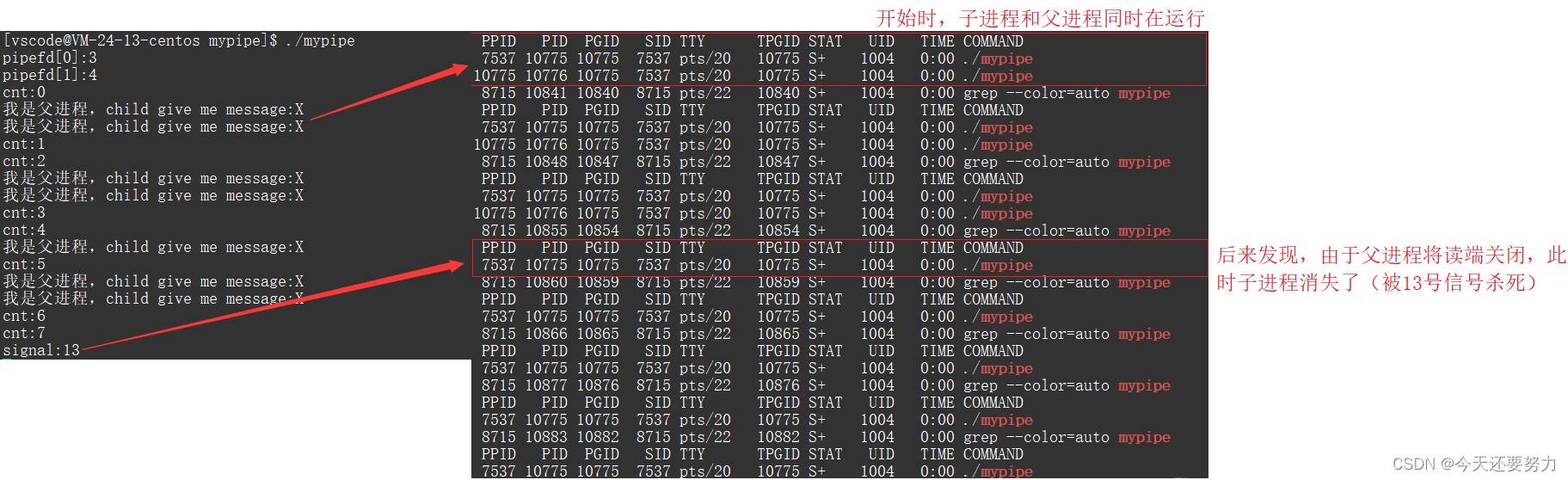
得出结论:操作系统直接会终止这个进程,因为操作系统不会维护没有意义,浪费资源的进程,并且知道,操作系统是通过信号(signal:13)来终止该进程
并且注意:此时我们读数据时,由于是直接使用pipe创建两个指向同一文件对象的文件描述符,并且一个是以写的方式打开文件,一个是以读的方式打开文件,所以要注意的就是,此时这个读和写表示的都只是只读和只写,所以此时由于是只读打开,所以当我们读完该文件中的数据之后,此时这个文件关闭之后,该文件中的数据就会被清空,该点可以很好的和上述知识挂钩!
管道读写规则
1.当没有数据可读时 O_NONBLOCK disable:read调用阻塞,即进程暂停执行,一直等到有数据来到为止, O_NONBLOCK
enable:read调用返回-1,errno值为EAGAIN。
2. 当管道满的时候 O_NONBLOCK disable:write调用阻塞,直到有进程读走数据 O_NONBLOCK enable:调用返回-1,errno值为EAGAIN
3.如果所有管道写端对应的文件描述符被关闭,则read返回0
4.如果所有管道读端对应的文件描述符被关闭,则write操作会产生信号SIGPIPE,进而可能导致write进程 退出
5.当要写入的数据量不大于PIPE_BUF时,linux将保证写入的原子性。
6.当要写入的数据量大于PIPE_BUF时,linux将不再保证写入的原子性。
感兴趣的同学可以参考该链接,了解一下什么是原子性问题:原子性问题详解
管道通信的特点(有上述现象得出)
- 单向通信
- 因为文件描述符的生命周期和进程相关,进程销毁了,进程对应打开的文件也就关了,进程创建了,进程对应的文件也就打开了,并且由于管道本质就是文件,所以管道的生命周期也是由进程决定
- 管道通信,用来进行具有"血缘关系"的进程,进行进程间通信,但常用语父子进程间通信,因为本质它们的文件描述符表是相同的,再准确点来说是因为它们的子进程是继承父进程的进程pcb,所以继承了该进程pcb中指向文件描述符表的那个指针,所以只要是具有"血缘关系",那么它们的文件描述符表就相同
- 匿名管道,我们并不清楚这个管道叫什么名字,因为它本质上就是一个内存级文件,有内核创建,操作系统维护
- 在管道通信中,写入的次数和读取的次数,不是严格匹配
- 管道可以让进程间通信具有一定的协同能力,让读和写可以按照一定的步骤进行通信,自带同步机制
写满了不能继续写,目的是避免数据被覆盖,感兴趣的同学可以去了解一下有关互斥和同步的概念,参考该链接:互斥和同步理解
注意:单个管道就是一个半双工(单向读写),全双工(边写边读,同时读写)
通过管道实现控制进程
搞定了上述知识,此时我们对管道的知识就有了进一步的了解,并且通过上述管道的读写规则和管道通信的特点,此时我们就可以根据原理,来自己实现进程的控制,通过管道的方式,实现一个父进程对多个子进程的控制
原理图如下:
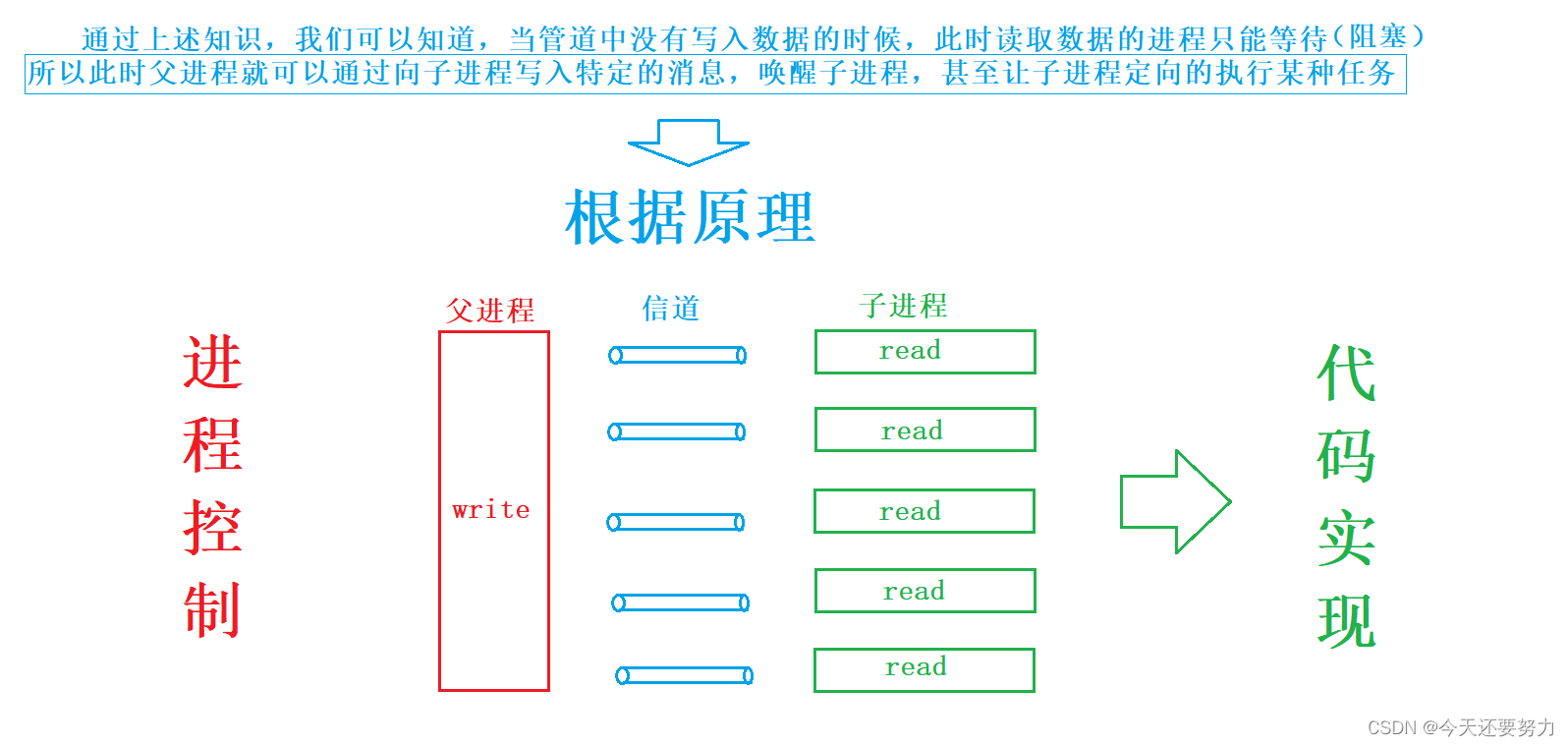
具体代码如下:
#include <iostream>
#include <string>
#include <vector> //目的:就是为了用vector数组的形式将所有的EndPoint管理起来
#include <cassert>
#include <unistd.h>
#include <fcntl.h>
#include <stdlib.h>
#include <stdio.h>
#include <sys/wait.h>
#include <sys/types.h>using namespace std;const int pipename = 5; // 这个表示的就是我们需要控制的进程个数(本质就是通过循环创建来控制而已)class EndPoint // 目的:通过先描述再组织进行管理
{
private:static int number; // 这个位置好奇可以去复习一下(切记在类外初始化就没什么大问题)public: // 类内的成员对象,最好是带一个_ ,不然写拷贝构造容易区分不了pid_t _child_id; // 代表的就是我要管理的子进程对象int _write_fd; // 作为父进程,在管理管道的时候,我们不需要考虑别的,只要考虑要往那个管道里面写就行了,所以此时这个参数表示的就是具体向那个管道里面写string processname; // 给进程取一个名字
public:EndPoint(int id, int fd) : _child_id(id), _write_fd(fd) // 构造函数初始化(直接用对应传上来的id和fd进行初始化进行,这样就确定了写入那个管道,和最终是那个进程进行读取){ // 设计成 process-0[pid:fd]char namebuffer[64];snprintf(namebuffer, sizeof(namebuffer), "process-%d[%d:%d]", number++, _child_id, _write_fd);processname = namebuffer;}const string &name() const // 使用函数的方法,把对象供给外部使用(但是该对象此时并不是私有,所以也可以直接用类对象调用){return processname;}~EndPoint(){}
};
int EndPoint::number = 0;//---------------------------------------------------------------------------------------------------------
// 目的:使用函数指针搞定任务,让子进程可以通过操作码调用想要执行的任务typedef void (*func_t)(); // 重定义一个函数指针,这个是C语言定义的写法,本质上写法:typedef void(*)() func_t;
// 此时这个函数指针,目的是为了帮我们创建不同的函数接口模仿不同的工作任务,并且让这些任务交给子进程去完成void PrintLog()
{cout << "pid:" << getpid() << ", 打印日志任务,正在被执行..." << endl;
}
void InsertMySQL()
{cout << "pid:" << getpid() << ",执行数据块任务,正在被执行..." << endl;
}
void NetRequest()
{cout << "pid:" << getpid() << ", 执行网络请求任务,正在被执行..." << endl;
}// 约定,每一个command都是4字节(并且可以使用枚举的方法)
#define COMMAND_LOG 0 // 这些下标的来源是因为我们已经手动的把,函数接口插入到了vector数组中,所以才可以根据这些操作码来调用对应指定的函数(本质还是下标而已)
#define COMMAND_MYSQL 1
#define COMMAND_REQUEST 2class Task
{
public:Task() // 向函数指针对象中加载内容,也就是进行初始化{funcs.push_back(PrintLog);funcs.push_back(InsertMySQL);funcs.push_back(NetRequest);}void Execute(int command) // 此时由于上述我们定义了很多的命令操作码,所以此时想要执行那个对应的命令,只需要将该命令的操作码传过来就行了{if (command >= 0 && command < funcs.size()){funcs[command](); // 判断,发现是合法请求,那么此时就通过command下标,执行函数指针对象中对应下标的函数接口,也就是执行相应的功能}}~Task(){}public:vector<func_t> funcs;
};//----------------------------------------------------------------------------------------------------------Task task; // 直接定义一个全局的对象供给子进程使用void WaitCommand() // 这个接口可以让子进程不断的去执行对应的命令,也就是上述的各种函数接口
{while (true) // 明白子进程等待命令,不是等待一次就可以的,它是需要循环等待,然后才可以循环执行(同时执行不同的功能){int command;int n = read(0, &command, sizeof(int)); // sizeof(int),每次读数据都规定只读4个字节,因为本质只是在读取具体的命令而已,本质就是在读取vector下标对应的函数指针if (n == sizeof(int)) // 此时read的返回值为4,表示它读到了一个命令,也就是读取成功的意思(并且因为会有读取失败的情况,所以不使用assert,而是使用判断){task.Execute(command);}else if (n == 0) // 此时n=0表示的就是读不到数据,也就是没数据读了,也就是说明对段关闭(写端关闭){cout << "父进程让我退出,我就退出了:" << getpid() << endl;break; // break函数只可以运用于循环函数中,不可以运用于if函数}else{break;}}
}void CreateProcess(vector<EndPoint> *end_points)
{for (int i = 0; i < pipename; ++i){// 1.1创建管道int pipefd[2] = {0}; // 因为在最后我们把父进程以读方式打开的文件和以写方式打开的文件都关闭了,所以此时等下次循环之后,再次创建读写文件描述符时int n = pipe(pipefd); // 此时我们就会有一个问题,就是不知道那个读写文件描述符是和那个进程相匹配(想要解决这个问题,此时就需要有一个结构体),本质就是利用这个结构体,把创建出来管道和进程进行管理(通过先描述,再组织的方式)assert(n == 0);// 1.2创建进程pid_t id = fork();assert(id != -1);if (id == 0){ // 一定是子进程// 1.3 构建单向通信,关闭不需要的文件描述符close(pipefd[1]);// 这个位置一定要明白一个点,就是因为进程间具有独立性(写时拷贝),所以父进程的vector和子进程是没有什么关联的// 子进程此时并不需要如何处理,唯一要处理的就是应该如何读数据,并且由于 所以只需要默认让子进程去标准输入中进行读取就行// 1.3.1 输入重定向dup2(pipefd[0], 0); // 将管道文件重定向到标准输入中,让子进程可以直接从标准输入中进行读取(也可以不进行重定向,只要把对应的文件描述符传过去也是可以的)// 1.3.2 子进程开始等待获取命令(也就是准备读取管道中的数据)WaitCommand(); // 不需要参数,因为重定向之后,waitcommand读取数据,就是直接从标准输入中读取close(pipefd[0]);exit(0); // 并且此时通过在这个直接退出,子进程就不会继续向后执行代码,干扰到父进程了}// 一定是父进程close(pipefd[0]);// 1.4 将新的子进程和他的管道写端,构建对象(不要想的太复杂,想不明白就想想一对一传送),关键点就是注意,写入的是那个文件描述符,和是那个进程进行的读取end_points->push_back(EndPoint(id, pipefd[1])); // 此时这个传参表示的就是我要写入的管道和进程的读取// 也就表示我们此时已经将对应的管道和进程插入到了end_points这个结构体数组类型中,也就表示最终,我们可以通过这个数组,来控制各个子进程// 并且注意,此时我们还是在循环条件里面,所以此时vector数组中 0 1 2 3 4 下标中存放的数据,就是我们对应的写入管道和读取的进程了(因为我们是一个结构体)// 所以此时就导致,我们想要向那个管道中写入数据或者是向那个进程传输数据,此时就只需要去vector数组找到它对应的下标就行了}
}int ShowBoard()
{cout << "------------------------------------------------" << endl;cout << "------0.执行日志任务-------1.执行数据块任务-----" << endl;cout << "------2.执行请求任务-------3.退出程序-----------" << endl;cout << "------------------------------------------------" << endl;cout << "请选择你要执行的任务:";int command = 0;cin >> command;return command;
}void CtrlProcess(const vector<EndPoint> &end_points) // 记住这边不可以直接用指针,用引用会更好
{int cnt = 0;// 注意:此时如下的命令读取,我们可以写成自动的,也可以写成交互式的,此时我们就把它改成交互式的就行while (true) // 通过循环控制vector下标,让子进程按照顺序执行对应功能{// 1.选择任务// int command = COMMAND_LOG; // 经过#define此时这个命令本质上就是下标0对应的函数指针int command = ShowBoard(); // 交互式,直接选择命令if (command < 0 || command > 3){cout << "选择有误,请重新选择:" << endl;continue;}if (command == 3){break;}// 2.选择进程// int index = rand() % end_points.size();//就是产生一个随机数,然后去%我的进程个数,最后得到的肯定是一个小于进程个数的随机数(可以自己演算一下)int index = cnt++; // 此时这边是可以直接把进程pid通过遍历vector给打出来,然后选择执行那个,但是这里使用的是轮询的方法,让进程轮询执行任务cnt %= end_points.size(); // 轮询经典写法(细节拉满),也可以理解是一个归零操作cout << "选择了进程:" << end_points[index].name() << " | 处理任务:" << command << endl;// 3.下发任务write(end_points[index]._write_fd, &command, sizeof(command)); // 表示的就是向那个管道种写命令(此时表示的就是向index这个进程对应的管道写)sleep(3);}
}
void WaitProcess(const vector<EndPoint> &end_points) // 该接口目的:就是为了保证所有的子进程退出,并且不处于僵尸状态(被回收)
{for (int end = end_points.size() - 1; end >= 0; --end) // 根据继承问题,所以此时需要倒着回收,不然会导致子进程一直阻塞住{// 1.要让子进程全部退出,只需要让父进程关闭写端就行(进程读写规则确定)cout << "父进程让所有的子进程全部退出:" << end_points[end]._child_id << endl;close(end_points[end]._write_fd); // 此时管道的写端就是在end_points对象中// 2.父进程回收子进程僵尸状态waitpid(end_points[end]._child_id, 0, 0);cout << "父进程回收了所有的子进程:" << end_points[end]._child_id << endl;}sleep(10); // 不着急退出
}int main()
{// 1.先进行控制进程的结构构建(本质就是创建5个管道和5个进程)vector<EndPoint> end_points; // 这个参数代表的就是父进程要管理的每一个写端(本质就是具体将数据写到那一个子进程中)CreateProcess(&end_points);// 2.当调用完上述构建进程控制的接口,此时父进程就把所有的管道文件(fd)和子进程(id)给录入到了vector数组中,此时父进程继续向下执行,此时就可以通过这个数据去控制进程了CtrlProcess(end_points); // 交互式控制进程实现// 3.代码走到这里表示的就是我们不想控制进程了,想要退出了(此时就要做好善后工作)WaitProcess(end_points);// 4.代码大致搞定,测试一下就行return 0;
}并且注意,上述代码涉及了几个比较偏门的知识点,如下:
函数指针详解 感兴趣的同学可以复习一下
函数指针的重定义:
C语言规定这样写:typedef void(*func_t)();自己认为的写法:typedef void(*)() func_t;,所以这两者是有区别的,要注意,重定义函数指针的时候不可以按照我们自己的理解方法去写,而是要按照C语言规定的方法写,感兴趣的同学可以参考下述链接:重定义函数指针
