分库分表--shardingjdbc

文章目录
- 前言
- 一、shardingjdbc
-
- 简介
- 作用
- 二、如何使用
-
- 1.我有个表现在体量太大了,我想做分库分表
- 2.开始改造
-
- 1 引入shardingjdbc
- 2 更改yml文件
- 3 测试看效果
- 3.旧数据迁移
- 4.其他分库类型
- 5 部分配置说明
- 总结
前言
当项目开始的时候,没有想到后续的分库分表的话,其实对于后续的分库分表操作多少会有一些较难处理的,所以一般分库分表都是在开始的时候就提前已经规划了,已经预留了口子,之后才能顺利的进行;
其实也不是必须要分库分表,由于国产高性能数据库等的出现,例如 tidb,完全遵守sql92标准,其实直接换上这个也是个非常不错的选择;
一、shardingjdbc
简介
- Sharding-JDBC定位为轻量级Java框架,在Java的JDBC层提供的额外服务。它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架
- 市面上常用的 例如 jpa jdbctemplete mybatis mp 原生的 jdbc都是ok的
- 它对于原有代码的改动很小,无入侵
- 支持任意实现JDBC规范的数据库,目前支持MySQL,TIDB, Oracle,SQLServer和PostgreSQL
- 支持分布式事务
- 支持各种连接池
作用
- 分库分表: 单库分表,分库后不再分表,分库分表
- 分布式事务
- 读写分离
- 数据库主键生成策略
- 分库分表路由策略
二、如何使用
1.我有个表现在体量太大了,我想做分库分表

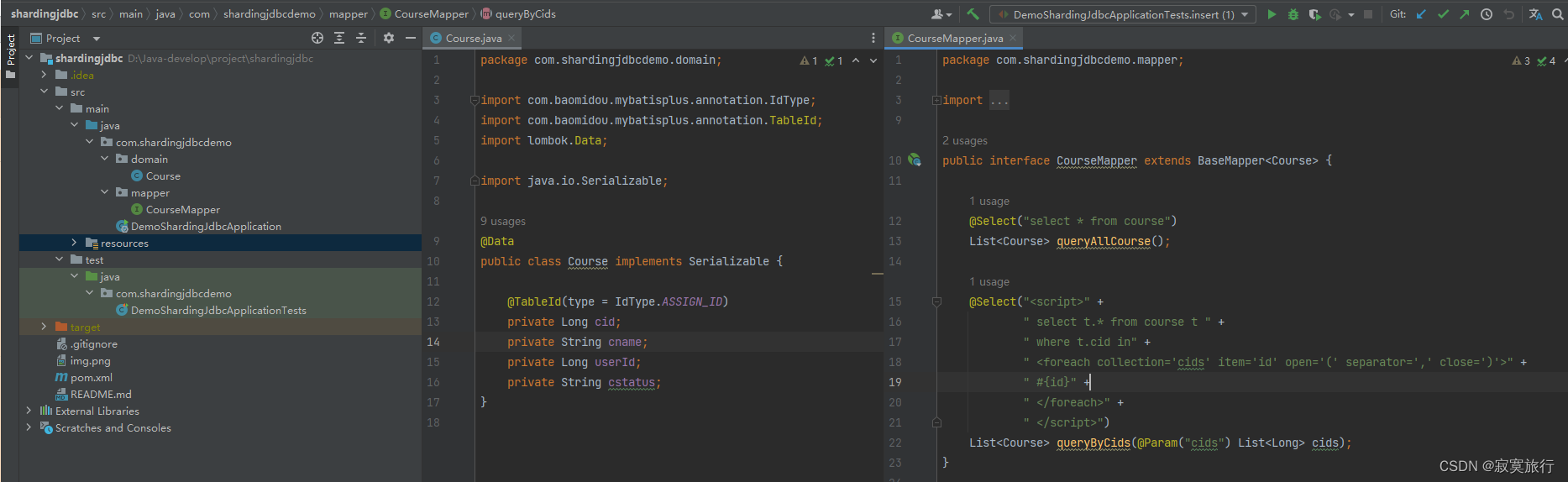
所以这就是我的springboot项目,引入了mp,然后可以实现单表的增删改查
2.开始改造
1 引入shardingjdbc
<dependency><groupId>org.apache.shardingsphere</groupId><artifactId>sharding-jdbc-spring-boot-starter</artifactId><version>4.1.1</version></dependency>
2 更改yml文件
新增两个表:

# 水平单库分表配置
spring:main:allow-bean-definition-overriding: truesharding-sphere:datasource:m1:driver-class-name: com.mysql.cj.jdbc.Driverpassword: roottype: com.alibaba.druid.pool.DruidDataSourceurl: jdbc:mysql://localhost:3306/coursedb?serverTimezone=GMT%2B8username: rootnames: m1props:sql:show: truesharding:tables:course:actual-data-nodes: m1.course_$->{1..2}key-generator:column: cidtype: SNOWFLAKEtable-strategy:inline:algorithm-expression: course_$->{cid%2+1}sharding-column: cid我现在相当于之前的代码没有任何改动
然后yml更改为了shardingjdbc 分库分表配置
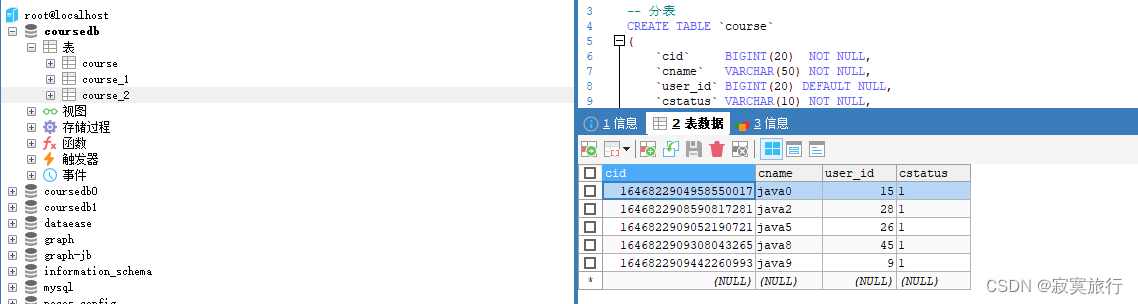
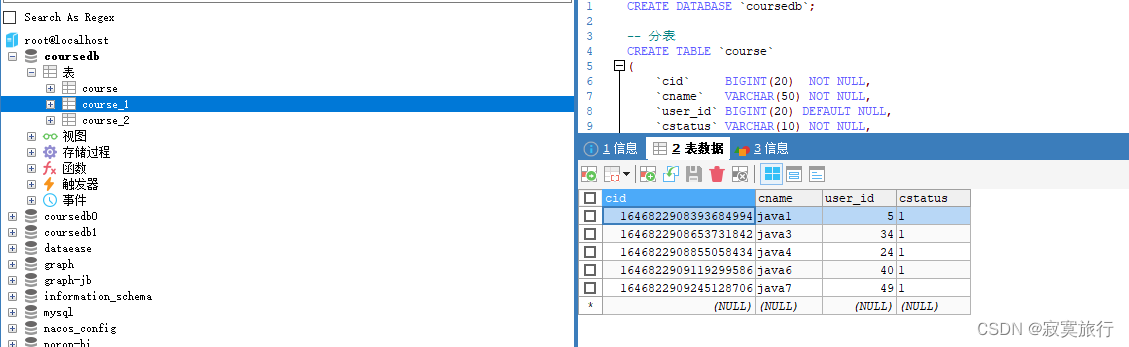
我将要应用的表为 coursedb 库中的 course_1 和 course_2
至此,sardingjdbc已经这个完毕了! 就是这么简单,直接看效果
3 测试看效果
- 新建测试类
@SpringBootTest
@RunWith(SpringRunner.class)
class DemoShardingJdbcApplicationTests {@ResourceCourseMapper courseMapper;/* 插入多条,分配到不同的表中*/@Testvoid insert() {for (int i = 0; i < 10; i++) {Course record = new Course();record.setCname("java" + i);record.setCstatus("1");record.setUserId(RandomUtil.randomLong(50));System.out.println(courseMapper.insert(record));}}}
- 看一段日志
ShardingSphere-SQL: Logic SQL: INSERT INTO course ( cid,
cname,
user_id,
cstatus ) VALUES ( ?,
?,
?,
? )ShardingSphere-SQL: Actual SQL: m1 ::: INSERT INTO course_2 ( cid,
cname,
user_id,
cstatus ) VALUES (?, ?, ?, ?) ::: [1646822909442260993, java9, 9, 1]
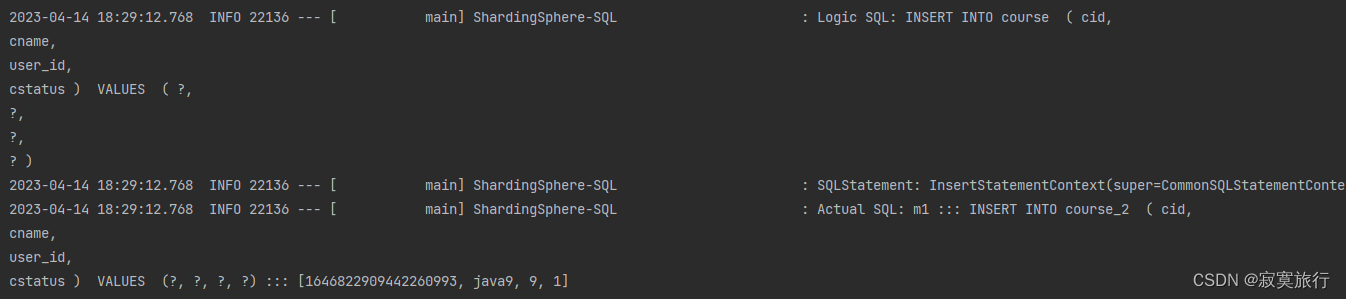
原始sql Logic SQL: INSERT INTO course
实际执行的sql Actual SQL: m1 ::: INSERT INTO course_2
没错,之前的表名称不用动,但是实际上已经在用 course_1 和 course_2
3.旧数据迁移
- 由于之前的course表中还有历史数据,所以需要迁移,因为他已经名存实亡了,以后也不再会用它了,那么就有点小复杂了
- 迁移单张表的数据还好,但是可能涉及到其他数据库
- 如果主键与分库分表之后的类型不一致,就更麻烦了
4.其他分库类型
- 水平分库 表不再分配置
# 水平分库 表不再分配置
spring:main:allow-bean-definition-overriding: truesharding-sphere:datasource:m1:driver-class-name: com.mysql.cj.jdbc.Driverpassword: roottype: com.alibaba.druid.pool.DruidDataSourceurl: jdbc:mysql://localhost:3306/coursedb0?serverTimezone=GMT%2B8username: rootm2:driver-class-name: com.mysql.cj.jdbc.Driverpassword: roottype: com.alibaba.druid.pool.DruidDataSourceurl: jdbc:mysql://localhost:3306/coursedb1?serverTimezone=GMT%2B8username: rootnames: m1,m2props:sql:show: truesharding:tables:course:actual-data-nodes: m$->{1..2}.coursekey-generator:column: cidtype: SNOWFLAKEtable-strategy:inline:algorithm-expression: coursesharding-column: cid- 水平分库 分表配置
# 水平分库 分表配置
spring:main:allow-bean-definition-overriding: truesharding-sphere:datasource:m1:driver-class-name: com.mysql.cj.jdbc.Driverpassword: roottype: com.alibaba.druid.pool.DruidDataSourceurl: jdbc:mysql://localhost:3306/coursedb0?serverTimezone=GMT%2B8username: rootm2:driver-class-name: com.mysql.cj.jdbc.Driverpassword: roottype: com.alibaba.druid.pool.DruidDataSourceurl: jdbc:mysql://localhost:3306/coursedb1?serverTimezone=GMT%2B8username: rootnames: m1,m2props:sql:show: truesharding:# 所有不分片的表,默认执行库default-data-source-name: m1tables:course:actual-data-nodes: m$->{1..2}.course_$->{1..2}key-generator:column: cidtype: SNOWFLAKEdatabase-strategy:inline:algorithm-expression: m$->{user_id % 2 +1}# 配置数据库字段 不是实体类中的字段sharding-column: user_idtable-strategy:inline:algorithm-expression: course_$->{cid % 2 +1}sharding-column: cid5 部分配置说明
tables:course:actual-data-nodes: m$->{1..2}.course_$->{1..2}key-generator:column: cidtype: SNOWFLAKEdatabase-strategy:inline:algorithm-expression: m$->{user_id % 2 +1}# 配置数据库字段 不是实体类中的字段sharding-column: user_idtable-strategy:inline:algorithm-expression: course_$->{cid % 2 +1}sharding-column: cid
- mKaTeX parse error: Expected group after '_' at position 16: ->{1..2}.course_̲->{1…2} 代表笛卡尔乘积,相当于m1.course_1,m1.course_2,m2.course_1,m2.course_2
- database-strategy 分库策略: 选择 m1 / m2
- user_id 分库策略具体算法字段,具体算法 m$->{user_id % 2 +1}
- table-strategy 分表策略: 选择 course_1 / course_2
- cid 分表策略具体算法字段,具体算法 course_$->{cid % 2 +1}
当 user_id 为偶数, cid 为偶数, 选择的应该是 m1.course_1
当 user_id 为偶数, cid 为奇数, 选择的应该是 m1.course_2
当 user_id 为奇数, cid 为偶数, 选择的应该是 m2.course_1
当 user_id 为奇数, cid 为奇数, 选择的应该是 m2.course_2
总结
所有代码均在gitee上: 项目地址
后续还有分页,排序,分布式事务等