Go的IO -- Go语言设计与实现

Go合IO的不解之缘
协程是Go的很大的一个优势。Go天然支持高并发,那么我们来研究一下这个高并发的秘诀在哪里?
执行体调度得当。CPU 不停的在不同的执行体( Goroutine )之间反复横跳!CPU 一直在装填和运行不同执行体的指令,G1(Goroutine 1 的缩写) 不行就搞 G2 ,一刻不能停,这样才能使得大量的执行体( Goroutine )齐头并进,系统才能完成如此高并发的吞吐(注意关键字:并发哦)。
思考一个问题,程序可以分成CPU密集型合IO密集型,Go适合哪一种?
很明显IO密集型,CPU密集型只能买核,买CPU,别无他法。
为什么适合IO密集型。
因为IO设备核CPU是独立的设备,这两者是可以并行运行的。
但是不是所有的IO都适配Go的高并发特性。
IO又分为:网络IO和文件IO。最适合Go的是网络IO密集型的程序。
- 网络IO的fd可以用epoll池来管理事件,实现异步IO
- 文件IO的fd不能用epoll来管理事件,只能进行同步IO
如果想让文件IO实现异步IO,在当前Linux有两种方式:
- Linux系统提供的AIO:但是Go没有封装实现。
- Linux系统提供的
io_uring:内核版本要求高,线上没有普及。
一句话,Go 语言级别把网络 IO 做了异步化,但是文件 IO 还是同步的调用。
Go中最原本的IO库
基础类型
比如:Reader、Writer、Closer、ReaderAt、WriterAt、Seeker、ByteReader、ByteWriter、RuneReader、StringWriter 等;
组合类型
第二大类就是组合类型,往往是把最基本的接口组合起来,使用的语法糖则是 Go 的匿名字段的用法,比如:ReaderCloser、WriteCloser、WriteSeeker 等;
type ReadWriter interface {ReaderWriter
}
进阶类型
这个类型比较有意思,一般是基于基础接口之上,加了一些有趣的实现,比如:
TeeReader、LimitReader、SectionReader、MultiReader、MultiWriter、PipeReader、PipeWriter 等;
IO通用的函数
Copy:把一个Reader读出来,写到Writer里去,直到其中一方出错为止( 比如最常见的,读端出现 EOF );CopyN:这个和Copy一样,读Reader,写Writer,直到出错为止。但是CopyN比Copy多了一个结束条件:数据的拷贝绝对不会超过 N 个;CopyBuffer:这个也是个拷贝实现,和Copy,CopyN本质无差异。这个能让用户指定使用多大的 Buffer 内存,这个可以让用户能根据实际情况优化性能,比如大文件拷贝的话,可以考虑使用大一点的 buffer,提高效率( 1G 的文件拷贝,它也是分了无数次的读写完成的,比如用 1M 的内存 buffer,不停的搬运,搬运 1024 次,才算完)。
io/ioutil工具库
这个库位于 src/io 目录之下,目录路径为 src/io/ioutil。顾名思义,这是一个工具类型的库,util 嘛,你们都懂的,啥都有,是一些方便的函数实现。他的核心是:怎么方便怎么来。
ReadFile:给一个路径,把文件一把读到内存(不需要 open,close,read,write 啥的,统统封装起来)方便不?WriterFile:给一个路径,把内存一把写入文件,方便不?ReadDir:给一个目录路径,把这个路径下的文件列表一把读上来,方便不?ReadAll:给一个Reader流,一把读完,全部读到内存,方便不?
这就是个工具库,就是应付一些简单的场景的 IO 方便而已。注意了,场景一定要简单,举个栗子:
使用 ReadAll 这个函数,是把 Reader 流全部读到内存,所以这里内存要装得下才行,如果你这个 Reader 是从一个 2 T 的文件来的,那就 (⊙o⊙)… 尴尬了。
IO库的拓扑
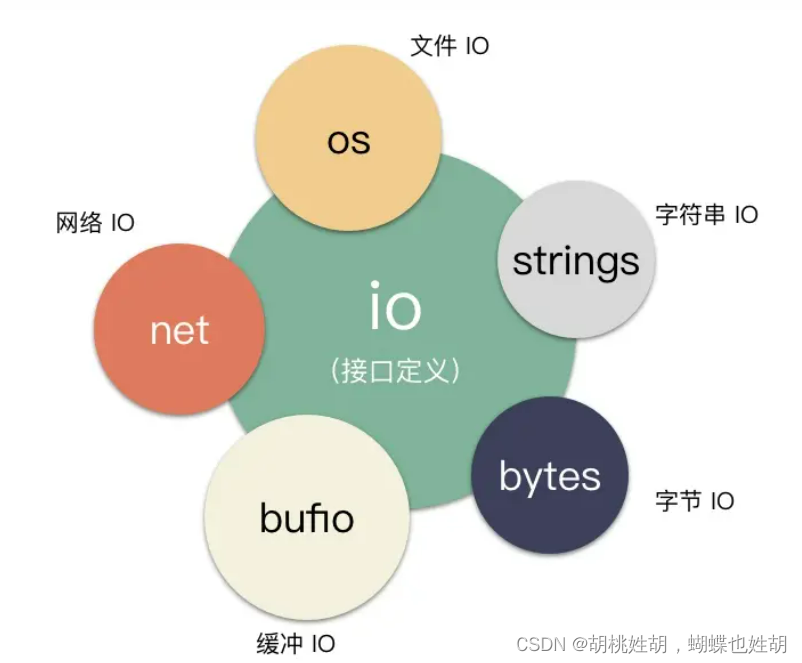
io 和字节的故事:bytes 库
处理字节数组的库,bytes.Reader 可以把 []byte 转换成 Reader,bytes.Buffer 可以把 []byte 转化成 Reader、Writer ,换句话讲,内存块可以作为读写的数据流了。
io 和网络的故事:net 库
网络可以作为读写源,抽象成了 Reader、Writer 的形式。这个是以 net.Conn 封装出来的。
举个栗子:演示一个 C/S 通信。
服务端:
package mainimport ("log""net"
)func handleConn(conn net.Conn) {defer conn.Close()buf := make([]byte, 4096)conn.Read(buf)conn.Write([]byte("pong: "))conn.Write(buf)
}func main() {server, err := net.Listen("tcp", ":8888")if err != nil {log.Println(err)}for {c, err := server.Accept()if err != nil {log.Println(err)}go handleConn(c)}
}
net.Listen创建一个监听套接字,在 Go 里封装成了net.Listener类型;Accept函数返回一个net.Conn,代表一条网络连接,net.Conn既是 Reader,又是 Writer ,拿到之后各自处理即可;
客户端:
func main() {conn, err := net.Dial("tcp", ":9999")if err != nil {panic(err)}conn.Write([]byte(""))io.Copy(os.Stdout, conn)
}
net.Dail传入服务端地址和网络协议类型,即可返回一条和服务端通信的网络连接,返回的结构为net.Conn;net.Conn即可作为读端(Reader),也是写端(Writer);
以上无论是 net.Listener ,还是 net.Conn 都是基于系统调用 socket 之上的一层封装。底下使用的是类似的系统调用:
syscall.Socket
syscall.Connect
syscall.Listen
syscall.GetsockoptInt
- 创建还是用 socket 的调用创建的 fd,创建出来就会立马设置
nonblock模式(因为 Go 的网络 fd 天然要使用 IO 多路复用的方式来走 IO ),还有其他配置; - 把 socket fd 丢到 epoll 池里 ( 通过
poll.runtime_pollOpen把 socket 套接字加到 epoll 池里,底层调用的还是epollctl),监听事件; - 封装好读写事件到来的函数回调;
io和文件的故事:os库
文件 IO,这个就是我们最常见的文件 IO 啦,文件可以作为读端,也可以作为写端。
File
io 的读写端可以是文件。这个太容易理解了,也是我们最常见的读写端,毕竟文件就是存储数据的一种形态。在 Go 里面,我们用 os.OpenFile 这个调用,就可以获取到 Go 帮你封装的文件操作句柄 File ,File 这个结构体对外实现了 Read,Write,ReadAt,WriteAt 等接口,所以自然就可以作为 Reader 和 Writer 来使用。 。
举个栗子:
// 如下,把 test.data 的数据读出来丢到垃圾桶fd, err := os.OpenFile("test.data", os.O_RDWR, 0)if err != nil {panic(err)}io.Copy(ioutil.Discard, fd)
这里返回了一个 File 类型,不难想象这个是基于文件 fd 的一层封装。这个里面大概做了什么?
- 调用系统调用
syscall.Open拿到文件 fd ,顺便设置了下垃圾回收时候的析构函数,其他的好像没了。远比网络 fd 要简单;
Stdin、Stdout、Stderr
Go 这个把标准输入、标准输出、标准错误输出 抽象成了读写源,对应了 os.Stdin,os.Stdout,os.Stderr 这三个变量。这三个变量其实就是 File 类型的变量,定义在 Go 的源码库 src/os/file.go 里:
var (Stdin = NewFile(uintptr(syscall.Stdin), "/dev/stdin")Stdout = NewFile(uintptr(syscall.Stdout), "/dev/stdout")Stderr = NewFile(uintptr(syscall.Stderr), "/dev/stderr")
)
划重点:这个就是我们常用的 0,1,2 句柄哦。
标准输入就可以和方便的作为读端( Reader ),标准输出可以作为写端( Writer )啦。
举个栗子:用一行代码实现一个最简单的 echo 回显的程序。
func main() {// 一行代码实现回显io.Copy(os.Stdout, os.Stdin)
}
把标准输入作为读端,标准输出作为写端。编译出来运行吧,在终端随便输入一个字符串,敲下回车看下效果吧。
缓存与io的故事:bufio库
Reader/Writer 可以是缓冲 IO 的数据流。
在 c 语言,有人肯定用过 fopen 打开的文件(所谓的标准IO):
FILE * fopen ( const char * filename, const char * mode );
这个函数 open 出的是一个 FILE 结构体,而非之前常说的整数 fd 句柄。通过这个文件句柄的 IO 就是标准库帮你实现的缓冲 IO。c 语言的缓冲 IO 有三种模式:
- 全缓冲:数据填满 buffer,才会真正的调用底层 IO;
- 行缓冲:不用等填满 buffer,遇到换行符,就会把 IO 下发下去;
- 不缓冲:bypass 的模式,每次都是直通底层 IO;
Go 的缓冲 IO 则是由 bufio 这个库提供。先讨论下缓冲 IO 究竟是什么吧。
缓冲 IO 是在底层 IO 之上实现的一层 buffer ,什么意思?
假设有个用户,每次写数据都只写 1 个字节,顺序的,写 512 次。之前我们在磁盘 IO 为啥要对齐中提过,非对齐的 IO 性能损失很大。以普通的机械硬盘来说,写 1 个字节,其实要先读一个扇区出来,然后再写下去。所以这里 IO 实际的 IO 次数为 1024 次,实际的 IO 数据量为:读 512 *512 Byte,写了 512 *512 Byte。
能怎么优化呢?
搞一个内存 512 字节的 buffer ,用户写 1 个字节我就先暂存在 buffer 里面,直到写满 512 字节,buffer 满了,然后一次性把 512 字节的 buffer 数据写到底层。你会发现,这里实际的 IO 只有一次,实际的数据量只有 512 字节。这就是 buffer io ,能极大的减少底层真实的 IO 次数。
所以,缓冲 IO 的优势是什么?
一目了然,写的时候能聚合 IO,极大减少 IO 次数。读的时候还能实现预读的效果,同样也减少 IO 次数。
这个也很容易理解,buffer io 相当于缓存数据了,一份数据多份存储了,这里给数据的一致性管理带来了复杂性,预读还有可能读到脏数据等等混乱情况。
bufio 这个库我们先理解名字,buffer io 的缩写。那顾名思义,核心是实现了缓存 IO 的库。对一个 Reader/Writer 携带一个内存 buffer 做了一层封装,达到聚合 io 的目的。
